


14 мая 2015 QuantAlgos
Основные принципы увеличения прибыльности алгоритмов автоматизированной торговли изложены в блоге Inovancetech. Представляю здесь перевод этой статьи. В ней использованы некоторые алгоритмы и результаты цикла про машинное обучение
После построения алгоритма, вам нужно убедиться, что он робастен и будет генерировать прибыльные сигналы при реальной торговле. В данном посте мы представим 3 легких способа увеличить производительность вашей модели.
Прежде чем улучшать модель, вы должны определить базовую производительность стратегии. Самый лучший способ сделать это - протестировать модель на новых исходных данных. Однако, вы всегда владеете довольно ограниченным набором данных, несмотря на их множество, предоставляемое финансовыми институтами. Значит, вы должны тщательно обдумать, как использовать имеющийся набор . По этим причинам, самое лучшее - разделить его на три отдельных части.
Тренировочный набор данных:
Это данные, которые вы используете для тренировки, или построения модели. Алгоритм будет пытаться найти взаимосвязь между входом ( вашими индикаторами) и выходом (где будет находится цена в следующем периоде - выше или ниже текущей). Обычно берут 60% имеющихся данных для этого набора.
Тестовый набор данных:
Мы будем использовать тестовый набор для определения производительности модели на данных, которые не использовались для тренировки. Этот набор мы применим для сравнения разных моделей ( или одной модели с разными параметрами), необходимо, чтобы это был как можно более репрезентативный набор, учитывающий разные ситуации на рынках. Обычно, берут 20% от имеющихся данных для тестирования.
Проверочный набор данных:
Проверочные данные используются для определения, как хорошо наша окончательная модель будет работать на будущих периодах. Мы можем использовать данный набор единожды, как выборку "out-of sample", для избежания подгонок под эти последние данные. Если результат не соответствует требуемым показателям, вы должны использовать другой проверочный набор, чтобы убедиться в робастности модели. Последние 20% данных зарезервированы для проверочного набора.
1.Понимание вашей модели.
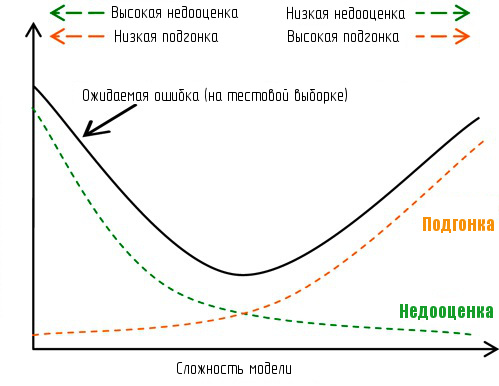
Перед тем, как улучшать модель, вам нужно понять характеристики данной модели, особенно - в каком случае возникает ее недооценка/подгонка под данные? Недооценка возникает, если алгоритм использует упрощенные предположения о состоянии рынка. Подгонка бывает, когда система подстраивается под шум, наличествующий в данных. Фокус в том, как определить, какое значение сигнала содержится в данных, без подгонки под случайный шум.
Быстрый способ узнать, где модель попадает под недооценку/подгонку, это сравнение ошибки тренировочного набора с ошибкой тестового набора данных. Если у вас большая ошибка в тренировочном и большая ошибка в тестовом наборе, вы с большой вероятностью имеете дело с недооценкой, а если вы получаете низкую величину ошибки в тренировочном наборе и высокою - в тестовом, то модель страдает от подгонки. В заглавии поста все это наглядно показано на графике.
Вы получите несколько лучшие результаты на новых данных, если ваша модель больше подвержена недооценке, чем подгонке, но ниже даны способы исправления для обоих вариантов:

*Регуляризация - процесс штрафования моделей за их сложность, в результате чего предпочтение отдается более простым моделям, таким образом уменьшается вероятность подгонки ( больше информации будет представлено в примерах на языке R далее).
Мы получили представление, когда наши модели подвержены недооценке/подгонке, далее рассмотрим другие способы улучшения алгоритмов.
2. Создание индикаторов.
Использование правильных входных данных для модели чрезвычайно важно. Выражение "мусор на входе - мусор на выходе" соответствует действительности, это означает, что если мы не подали значимой информации на вход алгоритма, то никогда не найдем в ней каких-либо паттернов или связей.
Если вы говорите "я использую 14-периодный RSI для торговли", за этими словами может скрываться больше, чем сказано. Вы можете применять наклон RSI, или его локальные максимумы и минимумы, расхождение с ценовым рядом, и множество других факторов. Однако модель получает только одну часть информации - текущее значение RSI. Для создания индикатора, или вычисления, основанного на значении RSI, нам нужно дать алгоритму больше информации, чем просто одно значение.
Используем наивный байесовский алгоритм , более стабильный, чем другие, склонные к подгонке, для создания сложных индикаторов, могущих улучшить производительность. Используем программу на языке R, применение наивного байесовского классификатора подробно разбирается в части 2 цикла про машинное обучение.
Во-первых, инсталлируем нужные библиотеки, устанавливаем входные данные и вычисляем основные входные параметры:
install.packages(“quantmod”)
library(quantmod)
install.packages(“e1071”)
library(e1071)
startDate = as.Date("2009-01-01")
endDate = as.Date("2014-06-01")
#Установим диапазон дат, который хотим исследовать
getSymbols("MSFT", src = "yahoo", from = startDate, to = endDate)
#Получаем наши данные
EMA5<-EMA(Op(MSFT),5)
RSI14<-RSI(Op(MSFT),14)
Volume<-lag(MSFT[,5],1)
#Вычисляем основные индикаторы. Отметим: у нас есть лаг в данных по объему, так как мы используем вчерашние данные в качестве входных для избежания подгонки данных, так как мы вычисляем индикаторы из цен открытия
PriceChange<- Cl(MSFT) - Op(MSFT)
Class<-ifelse(PriceChange>0,"UP","DOWN")
#Создаем переменную, которую хотим предсказывать
BaselineDataSet<-data.frame(EMA5,RSI14,Volume)
BaselineDataSet<-round(BaselineDataSet,2)
#Округляем входные данные до двух знаков после запятой, для использовании байесовского алгоритма
BaselineDataSet<-data.frame(BaselineDataSet,Class)
BaselineDataSet<-BaselineDataSet[-c(1:14),]
colnames(BaselineDataSet)<-c("EMA5","RSI14","Volume","Class")
#Создаем набор данных, удаляя периоды вычисления индикаторов
BaselineTrainingSet<-BaselineDataSet[1:808,];BaselineTestSet< -BaselineDataSet[809:1077,];BaselineValSet<-BaselineDataSet[1078:1347,]
#Разделяем данные на 60% тренировочного набора, 20% тестового набора и 20% проверочного набораЗатем строим основную модель:
BaselineNB<-naiveBayes(Class~EMA5+RSI14+Volume,data=BaselineTrainingSet)
table(predict(BaselineNB,BaselineTestSet),BaselineTestSet[,4],dnn=list('predicted','actual'))
Получается не очень хорошо. Только 46% предсказаний верны, и у нас наблюдается недооценка, приводящая к большому числу предсказаний увеличения цены. Это серьезное доказательство того, что наша модель недостаточно сложна для обработки имеющихся входных данных.
Давайте создадим более сложные индикаторы и посмотрим, удастся ли уменьшить недооценку:
EMA5Cross<-EMA5-Op(MSFT)
RSI14ROC3<-ROC(RSI14,3,type="discrete")
VolumeROC1<-ROC(Volume,1,type="discrete")
#Исследуем расстояние между 5- периодной ЕМА и ценой открытия, и одно- и трехпериодный индикатор ROC на нашем индикаторе RSI и объемах, соответственно
FeatureDataSet<-data.frame(EMA5Cross,RSI14ROC3,VolumeROC1)
FeatureDataSet<-round(FeatureDataSet,2)
#Округляем значение индикатора
FeatureDataSet<-data.frame(FeatureDataSet, Class)
FeatureDataSet<-FeatureDataSet[-c(1:17),]
colnames(FeatureDataSet)<-c("EMA5Cross","RSI14ROC3","VolumeROC1","Class")
#Создаем и называем набор данных
FeatureTrainingSet<-FeatureDataSet[1:806,]; FeatureTestSet< -FeatureDataSet[807:1075,]; FeatureValSet<-FeatureDataSet[1076:1344,]
#Создаем тренировочный, тестовы и проверочный наборыИ наконец, создаем нашу модель:
FeatureNB<-naiveBayes(Class~EMA5Cross+RSI14ROC3+VolumeROC1,data=FeatureTrainingSet)Посмотрим, удалось ли уменьшить недооценку:
table(predict(FeatureNB,FeatureTestSet),FeatureTestSet[,4],dnn=list('predicted','actual'))
У нас получилось увеличить аккуратность предсказания с 7% до 53% с использованием только относительно простых методов! Разберитесь как это произошло, просто наблюдайте за изменением этих индикаторов и переводите такие наблюдения в значения, которые понимает алгоритм, и вы сможете улучшить производительность стратегии еще больше.
В следующей статье мы разберем техники смешивания и форсирования, применяемые к множеству алгоритмов с целью улучшения производительности стратегии.
В этой части разберем технику улучшения производительности стратегии, использующую множество моделей.
Одним из наиболее мощных методов улучшения прибыльности вашей модели является объединение нескольких алгоритмов в так называемое "множество". Теория состоит в том, что комбинируя разные модели и их предсказания, мы получаем более робастные результаты. Тесты показывают, что даже объединение простых моделей может быть производительнее более сложной, но единственной стратегии.
Существует три основных техники объединения:
Смешивание:
Смешивание основано на создании моделей, прогоняемых на немного различных тренировочных наборах и усреднения их результатов для получения одного предсказания. Тренировочный набор переделывается путем повторения или удаления вхождений данных, в результате чего получается несколько разных наборов. Этот процесс работает хорошо для нестабильных алгоритмов (например, деревья решений) или, если присутствует определенная степень случайности в процессе создания моделей ( как, например, начальные веса в нейронных сетях). Получив усредненное предсказание для коллекции моделей с высоким значением подгонки, мы можем уменьшить результирующую подгонку без увеличения недооценки, что приведет к лучшим результатам.
Форсирование:
Форсирование представляет собой пошаговый процесс стимулирования моделей к улучшению их результатов в тех местах, где ранее они показывали низкую производительность. Большие веса присваиваются диапазонам исходных данных, ранее неправильно классифицированных, и окончательное предсказание получается путем комбинирования взвешенного "голосования" всех моделей в множестве. Эта техника хорошо работает со "слабыми" классификаторами с тенденцией к недооценке данных, таких как простые деревья решений и наивный байесовский классификатор. Здесь используются алгоритмы с высокой недооценкой , множество которых в целом позволяет лучше детектировать необходимый сигнал.
Упаковка:
Ранее мы рассматривали множества, содержащие модели с одним и тем же алгоритмом, но разными параметрами. Что если у нас имеется множество моделей с разными алгоритмами? Упаковка включает широкий спектр моделей с использованием "метаобучения", позволяющего составить наилучшую комбинацию отдельных моделей. Предсказания, сделанные каждой моделью, подаются далее в "метаобучение", которое анализирует характеристики каждой модели и выдает окончательное предсказание. Упаковку лучше всего применять, когда вы владеете коллекцией моделей, основанных на отличных друг от друга алгоритмах.
Применим модель с высокой дисперсией результатов, простое дерево решений, чтобы продемонстрировать, как смешивание улучшает производительность.
Сначала, построим дерево решений, используя те же индикаторы, что и при создании наивного байесовского классификатора из части 1:
install.packages(“rpart”)
library(rpart)
install.packages(“foreach”)
library(foreach)
BaselineDecisionTree<-rpart(Class~EMA5Cross+RSI14ROC3+VolumeROC1,data=FeatureTrainingSet, cp=.001)
library(rpart)
install.packages(“foreach”)
library(foreach)
BaselineDecisionTree<-rpart(Class~EMA5Cross+RSI14ROC3+VolumeROC1,data=FeatureTrainingSet, cp=.001)
Посмотрим, как модель ведет себя на тестовой выборке:
table(predict(BaselineDecisionTree,FeatureTestSet,type="class"),FeatureTestSet[,4],dnn=list('predicted','actual'))

Доля правильных предсказаний около 51%. Сравнивая этот результат с долей на тренировочном наборе, которая была равна 73%, мы делаем вывод, что наше дерево решений имеет высокую подгонку под тренировочную выборку.
Давайте посмотрим, как техника смешивания поможет уменьшить подгонку. Язык R предоставляет пару различных алгоритмов смешивания, но мы создадим такой алгоритм самостоятельно, для лучшего управления параметрами смешивания:
length_divisor<-10
iterations<-1501
#Эти операторы определяют как мы создаем разные тренировочные наборы и сколько моделей включить во множество. Мы строим 1501 модель на случайных выборках по 1/10 от всех данных
BaggedDecisionTree<- foreach(m=1:iterations,.combine=cbind) %do% { training_positions <- sample(nrow(FeatureTrainingSet), size=floor((nrow(FeatureTrainingSet)/length_divisor)))
train_pos<-1:nrow(FeatureTrainingSet) %in% training_positions
BaselineDecisionTree<-rpart(Class~EMA5Cross+RSI14ROC3+VolumeROC1,data=FeatureTrainingSet[train_pos,])
predict(BaselineDecisionTree,newdata=FeatureTestSet)
}
#Это наш алгоритм смешивания.
CumulativePredictions<-apply(BaggedDecisionTree[,1:iterations],1,function(x){s<-(sum(x)/iterations)
round(s,0)})
#Сейчас нужно агрегировать предсказания наших 1501 моделей
FinalPredictions<-ifelse(CumulativePredictions==1,"DOWN","UP")
#Возвращаем решение - бинарный выбор из нашей классификации (цена возросла/снизилась)
iterations<-1501
#Эти операторы определяют как мы создаем разные тренировочные наборы и сколько моделей включить во множество. Мы строим 1501 модель на случайных выборках по 1/10 от всех данных
BaggedDecisionTree<- foreach(m=1:iterations,.combine=cbind) %do% { training_positions <- sample(nrow(FeatureTrainingSet), size=floor((nrow(FeatureTrainingSet)/length_divisor)))
train_pos<-1:nrow(FeatureTrainingSet) %in% training_positions
BaselineDecisionTree<-rpart(Class~EMA5Cross+RSI14ROC3+VolumeROC1,data=FeatureTrainingSet[train_pos,])
predict(BaselineDecisionTree,newdata=FeatureTestSet)
}
#Это наш алгоритм смешивания.
CumulativePredictions<-apply(BaggedDecisionTree[,1:iterations],1,function(x){s<-(sum(x)/iterations)
round(s,0)})
#Сейчас нужно агрегировать предсказания наших 1501 моделей
FinalPredictions<-ifelse(CumulativePredictions==1,"DOWN","UP")
#Возвращаем решение - бинарный выбор из нашей классификации (цена возросла/снизилась)
Снова проверяем производительность на тестовой выборке (так как дерево создано на случайных диапазонах из тренировочного набора, мы можем получить несколько разные результаты - это один из недостатков работы с нестабильными алгоритмами):
table(FinalPredictions,FeatureTestSet[,4],dnn=list('predicted','actual'))

Намного лучше! Из-за уменьшения дисперсии нам удалось увеличить нашу производительность до 54%. В окончании, возьмем лучшую модель и прогоним ее на проверочной выборке, чтобы удостовериться, что мы построили робастный алгоритм.
Пока смешанные деревья решений на проверочной выборке и наивный байесовский классификатор из части 1 на тестовой выборке работают примерно с одинаковой производительностью. Автор отмечает, что ему больше нравятся модели с высокой недооценкой, чем с высокой подгонкой. Модели с тенденцией к недооценке могут работать не так хорошо на тренировочной и тестовой выборке, но вы можете быть уверены, что они покажут те же результаты на новых данных. Модели с высокой подгонкой, с другой стороны, имеют высокий риск показать значительно более низкую производительность в этом случае.
По этим соображением, применим технику смешивания к нашему наивному байесовскому алгоритму. И в результате прогона на проверочном наборе получаем:
table(predict(FeatureNB,FeatureValSet),FeatureValSet[,4],dnn=list('predicted','actual'))

Неплохо, и очень похоже на производительность на тренировочной и тестовой выборках! Наша окончательная производительность на проверочной выборке составила 54%. Значит мы построили хорошую робастную модель.
Заключение.
Первый шаг к увеличению производительности вашей модели - это понимание, в каком случае она подвержена недооценке/подгонке. Если вы сможете определить эти состояния, значит сможете и предпринять необходимые исправления.
http://www.quantalgos.ru/ (C)
Не является индивидуальной инвестиционной рекомендацией
При копировании ссылка обязательна Нашли ошибку: выделить и нажать Ctrl+Enter