


17 июня 2017 smart-lab.ru division_by_zero

Я думал-думал, я все понял - про машинное обучение в применении к трейдингу
в последние несколько месяцев я изучал машинное обучение, точнее, в основном, классификаторы на основе supervised learning
и я понял одну вещь — весь этот ручной трейдинг, соблюдение дисциплины, философия трейдинга, 30 гуру трейдинга и «к нам приехал Ларри Вильямс дорогой, сейчас он нас научит как жить» — все это туфта.
Если в поведении акций и других фин инструментов есть какие то закономерности, которые позволяют выцарапать из торговли хоть какой то risk-adjusted return — то это можно сделать только с помощью машинного обучения.
Точнее, сделать это можно, наверное, многими способами, но только машинное обучение предоставляет научный метод, оптимизирующий результат.
Почему ?
Потому что Машинное обучение (а оно бывает разное, я говорю в данном случае о supervised learning ) — оно тем и занимается, что строит модель на основе эмпирических данных, причем там есть методы типа adaboost, которые позволяют залить в модель десятки параметров и выжать из каждого их них хоть какую то кроху закономерностей, если она вообще там есть.
Я уверен, что в этот момент много умных людей пытаются на этом заработать.
Все эти технические индикаторы, какие то роботы на основе скользящих средних — все это вчерашний день по сравнению с хорошим алгоритмом машинного обучения, все равно что арифмометр по сравнению с айпадом. Я последние несколько дней провел (убил ?) в экспериментах по применению adaboost + decision trees к торговле.
Работает медленно, зараза, плюс Питон толком не поддерживает многоядерные процессоры, поэтому после каждого изменения параметров приходится ждать нового пересчета классификатора несколько минут.
Там есть способы ускорить все это дело, пользуясь всякими Apache Spark, но начинать надо с малого.Будучи полным лохом в алготрейдинге, пока только гоняю код, но хочу попробовать сделать функционирующую торговую приблуду на основе машинного обучения...
Охренительно интересная тема, скажу я вам.
Часть 2. грааль почти не виден
Прежде чем поделиться опытом разработки торговой системы, подумал, что полезно систематизировать мои посты, так как они в общем то группируются в три серии: (1) Александр едет к в гости к Дедушке Баффету (2) Долгосрочный пассивный портфель на основе идей Стратегического Инвестирования АКА портфель, который сделает Сипи, Арсагеру и Чорный квадрат и (3) Торговая система на машинном обучении
В самом конце этого поста приведены ссылки ни эти три цикла, если кому-то интересно их перечитать.
Итак, про машинное обучение.
Краткое содержание предыдущей серии.
В предыдущей серии автор пришел к выводу, что ручная торговля не может тягаться с правильным классификатором, построенным на основе принципов машинного обучения.
Будучи приверженцем секты долгосрочного инвестирования (свидетелей Дедушки Баффета ака Шадринистов), автор не верит в идею торговли как долгосрочный способ заработка
Тем не менее, для апробации вновь приобретенных знаний, автор решил постоить торговую систему на основе машинного обучения, и опробовать ее на реальном рынке и своих деньгах.
Итак, продолжаем
Последние 20 дней были убиты на написание кода на Питоне. Получился продукт из спичек и желудей, длиной приблизительно 1000 строк кода. В процессе написания пришлось перейти с процедуральной парадигмы на объектно-ориентированную, так как автор уперся в проблему непонимания собственного кода (также известную как феномен «х. проссышь») Потом, уже с объектно-ориентированным кодом, автор опять столкнулся с этой проблемой, и не раз. Пришлось делать так называемый рефакторинг, то есть чистить софт, чтобы в нем можно было хоть как то разобраться.Все дела были заброшены, и царил кодинг, жестокий и беспощадный.
В целом, получившийся программный продукт состоит из 4-х блоков
Первый блок отвечает за загрузку исторических финансовых данных
Второй блок отвечает за сам движок машинного обучения — калькуляцию входных параметров (features) и меток (labels), с последующей тренировкой движка. Этот же блок отвечает за так называемый cross validation — тестирование движка с различными параметрами, с целью определенияих оптимального набора
Третий блок отвечает за связь с брокером, которая происходит через restful web apis. Найти брокера, который предоставлял бы web apis, оказалось не простым делом. Казалось бы, что проще! Так нет, многие брокеры поддерживают API для C, java, их собственных экзотических программных платформ, но почему-то не Web API. Потом, когда был найден правильный брокер, оказалось, что чтобы заставить эти API работать, надо потратить охренительное количество времени.
Четвертый блок отвечает за risk management, что в моем пока что примитивном коде означает поддержание требуемого уровня маржи у брокера (через ограничение количества и размера открытых позиций), и поддержание правильного баланса между длинными и короткими позициями (пока не реализовано)
В процессе написания этого софта я извлек для себя следующие уроки:
Чтобы избежать эффекта overfitting, обучать и тестировать классификатор надо на разных наборах данных. В моем случае, у меня в распоряжении есть приблизительно три года исторических цен. Поэтому, каждый классификатор тестировался так: обучаем на данных из года номер 1,2, тестируем на годе номер 3. Потом обучаем на годах 2,3, тестируем на 1. Потом обучаем на 1 и 3, тестируем на 2. Потом считаем среднюю статистику по этим трем экспериментам и на их основе считаем recall и precision. Что такое рекол и пресижын, спрсите вы? Сейчас объясню. Recall — это какой процент из «правильных» результатов реально угадывает классификатор. Precision — это какой процент из выданных классификатором рекомендаций является реально правильными ответами.
Вообще, эти два понятия немного трудновато просечь вначале, но потом все становится понятным. Вот на вебе нашел хорошую картинку. Короче, низкий precision — гораздо хуже, чем низкий recall. Низкий precision означает, что классификатор выдает большой процент false positives, и они как раз портят всю статистику. При тестировании мои классификаторы выдавали recall около 30% и precision около 60%
По уму, конечно, система должна работать с короткими позициями так же хорошо, как с длинными. Иначе получается, что ты просто ловишь повышенную бету за счет повышенного риска. Работу с короткими позициями мне еще предстоит реализовать
Окрыленный предварительными результатами на исторических данных, я сел писать интеграцию с брокером, и наконец, запустил адскую машинку несколько дней назад
В следующей серии, под условным названием «красное море» (sea of red) я поделюсь результатами работы на реальных деньгах.
Пока эти результаты,… хм… эээ… неоднозначны. Но статистики пока мало, так что машинка продолжает работать и прожигать деньги на транзакционных издержках, до тех пор, пока не накопится достаточная выборка транзакцияй для анал-иза.
Часть 3. Reminiscences of machine learning operator, или поездка на Красное Море
вот все говорят, что Смартлаб читать — только время терять.
Я не соглашусь.
Иногда можно встретить очень умных людей, и получить полезную инфу.
В комментариях к одному из моих предыдущих постов про машинное обучение, уважаемый пользователь AlexeyT сказал, что adaboost -алгоритм для лошков, и все пацаны на районе давно используют xgboost.
Мне стало стыдно перед пацанами, быстренько почитал про xgboost, не без танцев с бубном поставил его на свой третий питон, и начал фигачить торговую систему, уже на новом алгоритме.
По ходу нашел кучу багов, пофиксил их по мере сил.
Подключил к брокеру, настроил все эти его кривые web apis, и понеслось !
Пока что, результатом работы системы стала эпичная поездка на Красное Море (sea of red). С глубоким погружением к рыбам в акваланге.
Собственно, не только система не дает никаких положительных сигналов, а наоборот — если бы я поступал в точности наоборот от ее сигналов, то заработал бы как минимум процента 3 в день. Вот, например, типичная картина за четыре дня — из 9 эмитентов, купленных по совету системы, 8 (!!!!!) в глубокой просадке, гораздо хуже рынка, и только один в более-менее плюсе ( не обращайте внимания на нищебродские суммы — я пока гоняю очень небольшие позиции, для наработки статистики)
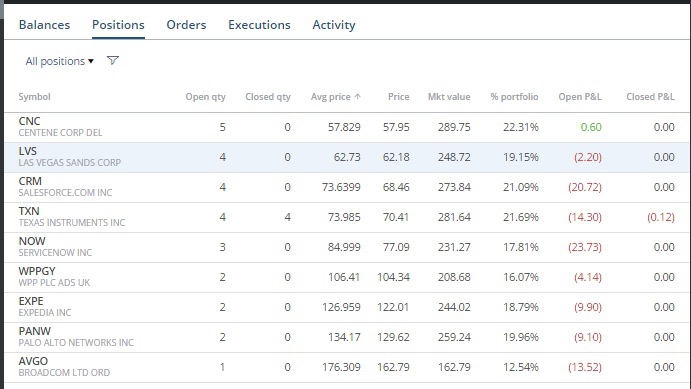
Самое интересное, что при тестировании на исторических данных алгоритм-таки дает положительный результат. Причем, тестирование происходит железобетонно на данных, не используемых при обучении. То есть, я учу классификатор только на годах 2014 и 2015, а тестирую только на 2016.
Начинаешь гонять систему на реальном рынке — тут и получается ж...
То ли в коде где-то косяк, то ли где то наверху опять поменяли матрицу, и я не вписался
Как пел Лаертский — то ли водка плохая стала, то ли космос как-то влияет.
Начинаешь как-то даже симпатизировать ребятам из Чорного Квадрата — неудивительно, что у них несколько месяцев в убыток.
Не хочет работать машинное обучение, хоть плачь! Поневоле закроешь фонд и уйдешь в запой !
С другой стороны, неделя статистики — это еще мало, так что продолжаем прожигать деньги.
Очевидная польза от всего этого приключения — что я вспомнил питон, ООП, библиотеку Pandas и разобрался в Supervised Learning — классификаторах.
Предупреждаю сразу — это еще не конец сериала про Машинное Обучение.
Меня так просто не возьмешь ! Я не потерял надежды подогнать реальность под теорию, и продолжаю накапливать статистику.
О закрытии проекта будет сообщено дополнительно :-)
/ (C) Источник
Не является индивидуальной инвестиционной рекомендацией
При копировании ссылка обязательна Нашли ошибку: выделить и нажать Ctrl+Enter