


6 ноября 2018 Живой журнал
"Человек, который может овладеть разговором за лондонским обедом, может овладеть всем миром. Будущее принадлежит денди", - в своё время иронично подметил Оскар Уайльд. Времена немного поменялись. И овладеть миром под силу будет только роботу, овладевшему разговором за давосским завтраком. А будущее принадлежит искусственному интеллекту. Без всяких шуток.
Но насколько далеко это будущее? Если судить по СМИ, обильно вставляющих в статьи и репортажи термины«ИИ»/«AI», то машинный интеллект уже давно стал рядовым явлением и завтра-послезавтра мы все тоже будем проводить деловые завтраки с робо-собеседниками. Если верить самому Герману Оскаровичу, если вы до сих пор не пользуетесь ИИ — ваше место на свалке истории. Для современных интеллектуалов-«денди» ИИ стал модной концепцией, частое упоминание которой свидетельствует о прогрессивности, широте взглядов и чуть ли не приобщенности к Высшему Знанию.
Если же обратиться к специалистам, занимающимся этой темой не один десяток лет... о-о-о, всё становится гораздо интереснее. «Для начала, - скажут они с хитрой улыбкой, - никто не знает, что такое искусственный интеллект». Нет, вам без проблем приведут то или иное определение. Но добавят, что есть и другие, и их немало, и найти между ними что-то общее порой тяжело. А в целом ситуация напоминает древнюю историю о слепцах, пытающихся на ощупь понять, на кого похож слон.
«Нет никаких поводов, кроме собственного высокомерия, верить в то, что сейчас мы находимся ближе к пониманию разумности, чем алхимики — к секретам ядерной физики», - писал в 1986 Терри Виноград, один из влиятельнейших экспертов того времени. Тридцать лет спустя высокомерия у новых «денди» не убавилось, а вот удалось ли приблизиться к пониманию — большой вопрос...
«Искусственный интеллект, - разведут руками специалисты, - это такой «Священный Грааль»: все про него слышали, но буйные фантазии вокруг совершенно затмевают скучное положение дел в реальности». А практикам не нужны фантазии. В области машинного обучения, крупные успехи в которой породили всю недавнюю шумиху вокруг «ИИ», предпочитают избегать этого звучного термина.
Проблема в том, что непонятно, где именно провести границу между ИИ и «просто» продвинутым алгоритмом, возможно ли провести такую границу, наконец, нужна ли вообще такая граница. Поэтому практики заняты совсем не поисками «Священного Грааля». А сосредоточены на более четко определенных задачах: машинном зрении, обработке естественного языка, автономности и так далее.

Нет, нашим провинциальным "денди" еще далеко до законодателей мод...
Но в ходе решения этих задач ограничения существующих алгоритмов становятся более чем очевидными. Мы не знаем, где провести границу искусственного интеллекта — однако мы прекрасно осведомлены о том, что рамки способностей сегодняшних программ крайне узки. И мы всегда стремились расширить эти рамки. А для этого нужно сформулировать новые вызовы.
Те вызовы, о которых здесь пойдёт речь, требуют создания алгоритмов очень высокой сложности, требуют технологических прорывов и совершенно новых подходов. Они определяют новые рамки способностей — и мы поговорим, как эти рамки соотносятся с теми или иными аспектами биологического интеллекта. Мы обсудим, насколько удачно продуманы предлагаемые вызовы и в чем могут быть их слабые места. Наконец, мы посмотрим на современные достижения в направлении данных вызовов и на то, какой путь еще предстоит пройти. Начнем!
1. Тест Тьюринга
Тест Тьюринга вот уже много лет считается «классическим», более того — практически безальтернативным способом определения разумности машин. В популярных изданиях в 99,9% случаев, как только речь заходит об искусственном разуме, тест Тьюринга упоминается как главный аргумент, позволяющий проверить т. н. «сильный» ИИ. Да и среди специалистов имя Тьюринга стало почти синонимом для любого теста, который измеряет машинный интеллект, несмотря на специфику и авторство идеи испытания.
Сам Алан Тьюринг, наоборот, стремился уйти от неопределенности границ «разумности» и «мышления». Его тест как раз вписывается в подход, упомянутый в введении: сформулировать условия, выполнение которых будет свидетельствовать о значительно возросших способностях машин.
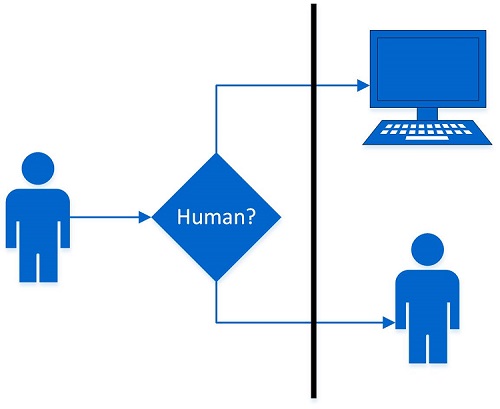
В силу известности теста Тьюринга я не буду подробно останавливаться на деталях (существуют разные версии с незначительными вариациями) и ограничусь схематичным описанием. Тест представляет собой игру для трех участников. Один из них, «судья» (человек или жюри из людей), задает вопросы двум другим: машине и человеку. Цель задающего вопросы — распознать, кто/что из отвечающих является машиной, а кто — человеком. Цель машины — имитировать в своих ответах человека настолько хорошо, чтобы заставить «судью» ошибаться. Игра обычно продолжается от 5 до 25 минут. Машина, способная обманывать «судью» в половине и более случаев, признаётся прошедшей тест.
Простые и ясные условия теста и особенно тот факт, что он стал первой целенаправленной и продуманной схемой проверки «человеческих качеств» алгоритмов, поспособствовали широкому признанию работы Тьюринга в научных кругах. (Забегая вперед, почти все тесты из этого обзора ничуть не хуже по простоте и ясности). Ей посвящено большое количество публикаций, разработаны предложения по усовершенствованию теста и предложены более четкие методики его проведения.
В числе сильных сторон теста Тьюринга называют прежде всего широту охвата знаний и способностей, которыми в теории должна владеть машина, чтобы каждый раз убедительно отвечать на самые разные вопросы. Действительно, тест ничем не ограничивает тему и характер вопросов, и в интересах «судьи» постараться найти слабые места на всём протяжении областей человеческого знания.
Здесь лежит определенная хитрость: несмотря на простоту схемы теста, требуется, чтобы «судья» самостоятельно обеспечивал высокий уровень сложности вопросов. Именно наличие человека-«судьи» задает сложность прохождения теста; более того, именно «судья» каждый раз формирует новый, уникальный вызов, на который предстоит ответить машине.
В этом особенность теста Тьюринга: он описывает не столько сам вызов, сколько общие правила формулирования вызова для машин. Это значит, что результаты разных раундов тестирования вряд ли абсолютно сопоставимы между собой, мало предсказуемы, и тем более трудно говорить о какой-либо стандартизации. Исход теста Тьюринга зависит от «судьи» едва ли не в большей степени, чем от машины-кандидата. Без всяких натяжек можно говорить, что человек-«судья» играет в этом испытании более активную роль, чем машина. Всё это является достаточно серьезными недостатками с точки зрения методологии науки. Остается спасаться тем, что описываемый тест проверяет лишь произвольно выбранные рамки возможностей машины и не претендует на строгие выводы и подтверждение фундаментальных концепций.
Но это лишь одна из проблем. Есть и другие, не менее серьезные. Часть из них проистекает из игрового характера теста. Игры стремятся сбалансировать, так, чтобы ни одна из сторон не могла получить преимущество за счет эксплуатации «нечестных» (т. е. не соответствующих духу игры) приемов. К сожалению, Алан Тьюринг не успел оценить баланс сторон на практике. А практика скоро показала, что баланс оставляет желать лучшего.
Дух игры подразумевает, что в ней соревнуются два интеллекта: человеческий и машинный. Но одновременно с человеческим интеллектом в игру привносится и человеческая иррациональность. И вот ее-то оказывается возможным эксплуатировать весьма эффективно.
Сами принципы теста способствуют такой эксплуатации. В конце концов, задача машины — обмануть человека, а не продемонстрировать более качественные знания. И если обмануть человеческий интеллект можно, лишь обладая превосходящим интеллектом, то сыграть на наших иррациональных убеждениях оказывается очень просто.
Более примитивному алгоритму (точнее, его создателям) оказывается выгоднее играть «на понижение», демонстрируя не признаки разумности, но признаки «натуральности» в общении с «судьей». И надеяться на склонность человека к антропоморфизму: мы склонны одушевлять даже самые простые и банальные предметы вокруг себя.
Можно вспомнить про вымышленную Ильфом и Петровым Эллочку-людоедку, которая прекрасно обходилась словарным запасом в 30 слов. А можно просто поглядеть на современное общение в Сети: для выражения широкого спектра мнений молодёжи вполне хватает «лол», «жесть» и пёстрого набора эмотиконов. И становится понятно, что Тьюринг слегка переоценил трудность задачи для машины.

Справедливость этих рассуждений подтверждает успех чатбота «Женя Густман», которому несколько раз удавалось дурачить значительную долю «судей» на значимых конкурсах. А в 2014 — преодолеть установленную организаторами планку в 30% перепутавших программу с человеком. Что дало повод для шквала статей в прессе на тему «Тест Тьюринга пройден!!!1111» и не менее внушительного шквала критики со стороны научного сообщества, направленной на сенсационализм масс-медиа, убогость чатбота «Жени», плохую организацию теста в частности и его фундаментальные ограничения в целом, и еще много чего...
«Женя» пытался персонифицировать 13-летнего мальчика из Одессы. Его английская версия объявляла, что английский язык не является для нее родным. Нежный возраст был призван объяснить пробелы в фундаментальном знании и сыграть на эмоциях. «Они же дети», да. «Женя» умел старательно уходить от вопросов, не стеснялся рассказывать шуточки и вставлять смайлики там, где это необходимо (то есть, практически везде). Иначе говоря, «Женя» агрессивно снижал планку — и это работало, работало на удивление эффективно.
Так что еще раз подчеркнем огромную роль «судьи» в испытании: именно он должен устанавливать планку и не засчитывать попытки испытуемого алгоритма «поднырнуть» под нее. И в связи с тем, что человек является в нем ключевой фигурой, упомянем еще один недостаток теста Тьюринга, отмечаемый теоретиками: его ярко выраженную антропоцентричность. И это еще мягко сказано. Точнее всего эту особенность описал Гэри Фостел: «В тесте Тьюринга проверяется не интеллект, а человечность». Ведь от машины требуется только имитировать человеческую персону, не больше и не меньше.
Впрочем, недостатком это можно назвать только в контексте споров о том, что же представляет собой интеллект. С нашей же точки зрения, антропоцентричный подход лишь очерчивает определенные рамки возможностей, причем далеко не самые широкие. Нам эти рамки интересны еще и потому, что только они позволяют сделать условия теста близкими и интуитивно понятными.
Поскольку недостатки были выявлены серьезные, ряд исследователей предложили свои варианты усовершенствования теста. Один из самых сильных, на мой взгляд, был опубликован в 2003 году Эдвардом Фейгенбаумом. Давайте познакомимся с его особенностями.
Во-первых, тема разговора. Для каждого раунда выбирается определенная область формализованных научных знаний. Фейгенбаум предлагает такие сферы, как естественные науки, медицина и инженерное дело, и допускает, что список может быть расширен (например, гуманитарные науки?).
Во-вторых, участники. В качестве игрока-человека, отвечающего на вопросы, и в качестве «судьи», выступают ведущие специалисты в своей области, элитные учёные (скажем, члены Академии Наук). Допустим, это двое астрофизиков, или спецов по информатике, или по молекулярной биологии.
В-третьих, суть общения. «Судья» постулирует проблемы в своей области, задает вопросы, требует теоретически обоснованного объяснения и так далее. Происходящее можно сравнить с «экзаменом» на очень глубокое владение темой или на защиту ученой степени. Сможет ли машина справиться с дискуссией настолько хорошо, что «судья»-академик не сможет отличить ее от своего титулованного коллеги?
Для более надежного результата Фейгенбаум советует «экзаменовать» машину на нескольких парах специалистов. А самим специалистам, чтобы усложнить тест, следует общаться на языке, насыщенном терминами и оборотами из своей предметной области, которые необязательно понятны простому «человеку с улицы».
Фейгенбаум называет свой тест «Очень великим вызовом» (англ. «Very Grand Challenge»). И такое определение вполне оправдано: сложность этого теста невероятно высока. Когда алгоритм сможет на равных дискутировать со светилами науки и ведущими инженерами, представления об ИИ из научной фантастики станут очень близкими к реальности...
Но до этого момента еще очень далеко. Пока ни у кого даже нет и мысли выставлять свои программы против экспертов в тесте Фейгенбаума. А вот конкурсы по более простому тесту Тьюринга проводятся уже несколько десятилетий. Существует несколько организаций, популяризующих этот тест. Cтарейшим и самым влиятельным считается конкурс на премию Лёбнера, организуемый ежегодно с 1991.

Конкурс проводится в Блетчли-Парк - бывшей усадьбе, в которой в годы Второй Мировой Тьюринг с коллегами взламывали немецкие шифры
Премия Лёбнера имеет свой призовой фонд ($4000 за 1 место) и отличается вполне серьезным подходом к делу. По мере совершенствования алгоритмов организаторам пришлось ужесточить требования к судейскому корпусу. Теперь алгоритмы оценивают представители научного сообщества, профессионалы индустрии, а также представители масс-медиа. Притворяться «13-летним мальчиком» стало не так просто.
Очередной конкурс завершился совсем недавно. Давайте посмотрим, что в нем показала программа, занявшее первое место - «Мицуку», созданная Стивом Уорсвиком. «Мицуку» занимает первое место уже третий год подряд, кроме того, на ее счету победа на премии Лёбнера-2013 и нескольких других конкурсах. Чатбот разрабатывается Уорсвиком с 2005 года.
Вот часть переписки «Мицуку» с одним из «судей», Дж. Харрисом, возглавляющим исследование технологий в стартапе «CognitionX». (Все раунды доступны по ссылке)

Как видим, всё идет наперекосяк уже с третьей реплики бота. Не слишком уместный скрипт заставлял «Мицуку» писать сообщения «судье», если прошло более 60 секунд с момента последнего ответа. Харрис моментально «раскусил» эту особенность, и в дальнейшем такие запросы программы его здорово раздражали. («Судье» нужно было время, чтобы одновременно разговаривать с другим участником-человеком и делать заметки).
Дальше «судья» изучает изъяны «машинного интеллекта», постепенно теряя к нему интерес. И становится предельно понятно, что речь идет не об изъянах интеллекта, а о примитивном подборе готовых ответов под реплики судьи, зачастую малоуспешном. А ведь это программа, третий год удерживающая «чемпионский» статус, объективно одна из лучших...

Аватар "Мицуку" в "Twitch". Если не получается вытягивать за счет мозгов, приходится полагаться на внешние данные...
Вспомним еще раз об игровом характере теста Тьюринга. Для того, чтобы игра удалась, необходимо, чтобы вызовы были соразмерны способностям участников. Но сейчас — и это признают сами участвующие в конкурсе разработчики — пропасть между «мыслящей машиной», какой представлял её Тьюринг, и нынешними чатботами безбрежна и непреодолима. Нынешние конкурсы и тесты, по сути, представляют собой «игру в одни ворота». Либо гротескное искажение замысла теста, в котором не люди определяют интеллект машин, а машины тестируют человеческую глупость. Вероятно, именно поэтому специалисты по ИИ не считают, что тест Тьюринга имеет сейчас хоть какой-то полезный практический смысл.
«Мицуку», как и многие другие программы, участвовавшие в конкурсе, написана на AIML. Это разновидность XML, которая предназначена для организации базы реплик чатботов и их контекстно-зависимой выдачи. Результаты конкурса на премию Лёбнера хорошо демонстрируют пределы такого подхода в создании «умных» алгоритмов. Кропотливое создание базы знаний вручную одним человеком или небольшой командой в конечном итоге заводит в тупик: количество возможных вопросов необъятно, а их логическая взаимосвязь делает использование заранее заготовленных ответов бессмысленным.
Чтобы выйти из этого тупика и преодолеть существующую пропасть, нужны альтернативные подходы. Некоторые из них будут обсуждаться далее. Пока же, дабы закончить на позитивной ноте, предлагаю (при базовом знании английского) поболтать с «Мицуку». Пускай до серьезной борьбы в тесте Тьюринга ей далеко, она хотя бы способна немного вас развлечь.
/ (C) Источник
Не является индивидуальной инвестиционной рекомендацией
При копировании ссылка обязательна Нашли ошибку: выделить и нажать Ctrl+Enter
Но насколько далеко это будущее? Если судить по СМИ, обильно вставляющих в статьи и репортажи термины«ИИ»/«AI», то машинный интеллект уже давно стал рядовым явлением и завтра-послезавтра мы все тоже будем проводить деловые завтраки с робо-собеседниками. Если верить самому Герману Оскаровичу, если вы до сих пор не пользуетесь ИИ — ваше место на свалке истории. Для современных интеллектуалов-«денди» ИИ стал модной концепцией, частое упоминание которой свидетельствует о прогрессивности, широте взглядов и чуть ли не приобщенности к Высшему Знанию.
Если же обратиться к специалистам, занимающимся этой темой не один десяток лет... о-о-о, всё становится гораздо интереснее. «Для начала, - скажут они с хитрой улыбкой, - никто не знает, что такое искусственный интеллект». Нет, вам без проблем приведут то или иное определение. Но добавят, что есть и другие, и их немало, и найти между ними что-то общее порой тяжело. А в целом ситуация напоминает древнюю историю о слепцах, пытающихся на ощупь понять, на кого похож слон.
«Нет никаких поводов, кроме собственного высокомерия, верить в то, что сейчас мы находимся ближе к пониманию разумности, чем алхимики — к секретам ядерной физики», - писал в 1986 Терри Виноград, один из влиятельнейших экспертов того времени. Тридцать лет спустя высокомерия у новых «денди» не убавилось, а вот удалось ли приблизиться к пониманию — большой вопрос...
«Искусственный интеллект, - разведут руками специалисты, - это такой «Священный Грааль»: все про него слышали, но буйные фантазии вокруг совершенно затмевают скучное положение дел в реальности». А практикам не нужны фантазии. В области машинного обучения, крупные успехи в которой породили всю недавнюю шумиху вокруг «ИИ», предпочитают избегать этого звучного термина.
Проблема в том, что непонятно, где именно провести границу между ИИ и «просто» продвинутым алгоритмом, возможно ли провести такую границу, наконец, нужна ли вообще такая граница. Поэтому практики заняты совсем не поисками «Священного Грааля». А сосредоточены на более четко определенных задачах: машинном зрении, обработке естественного языка, автономности и так далее.
Нет, нашим провинциальным "денди" еще далеко до законодателей мод...
Но в ходе решения этих задач ограничения существующих алгоритмов становятся более чем очевидными. Мы не знаем, где провести границу искусственного интеллекта — однако мы прекрасно осведомлены о том, что рамки способностей сегодняшних программ крайне узки. И мы всегда стремились расширить эти рамки. А для этого нужно сформулировать новые вызовы.
Те вызовы, о которых здесь пойдёт речь, требуют создания алгоритмов очень высокой сложности, требуют технологических прорывов и совершенно новых подходов. Они определяют новые рамки способностей — и мы поговорим, как эти рамки соотносятся с теми или иными аспектами биологического интеллекта. Мы обсудим, насколько удачно продуманы предлагаемые вызовы и в чем могут быть их слабые места. Наконец, мы посмотрим на современные достижения в направлении данных вызовов и на то, какой путь еще предстоит пройти. Начнем!
1. Тест Тьюринга
Тест Тьюринга вот уже много лет считается «классическим», более того — практически безальтернативным способом определения разумности машин. В популярных изданиях в 99,9% случаев, как только речь заходит об искусственном разуме, тест Тьюринга упоминается как главный аргумент, позволяющий проверить т. н. «сильный» ИИ. Да и среди специалистов имя Тьюринга стало почти синонимом для любого теста, который измеряет машинный интеллект, несмотря на специфику и авторство идеи испытания.
Сам Алан Тьюринг, наоборот, стремился уйти от неопределенности границ «разумности» и «мышления». Его тест как раз вписывается в подход, упомянутый в введении: сформулировать условия, выполнение которых будет свидетельствовать о значительно возросших способностях машин.
В силу известности теста Тьюринга я не буду подробно останавливаться на деталях (существуют разные версии с незначительными вариациями) и ограничусь схематичным описанием. Тест представляет собой игру для трех участников. Один из них, «судья» (человек или жюри из людей), задает вопросы двум другим: машине и человеку. Цель задающего вопросы — распознать, кто/что из отвечающих является машиной, а кто — человеком. Цель машины — имитировать в своих ответах человека настолько хорошо, чтобы заставить «судью» ошибаться. Игра обычно продолжается от 5 до 25 минут. Машина, способная обманывать «судью» в половине и более случаев, признаётся прошедшей тест.
Простые и ясные условия теста и особенно тот факт, что он стал первой целенаправленной и продуманной схемой проверки «человеческих качеств» алгоритмов, поспособствовали широкому признанию работы Тьюринга в научных кругах. (Забегая вперед, почти все тесты из этого обзора ничуть не хуже по простоте и ясности). Ей посвящено большое количество публикаций, разработаны предложения по усовершенствованию теста и предложены более четкие методики его проведения.
В числе сильных сторон теста Тьюринга называют прежде всего широту охвата знаний и способностей, которыми в теории должна владеть машина, чтобы каждый раз убедительно отвечать на самые разные вопросы. Действительно, тест ничем не ограничивает тему и характер вопросов, и в интересах «судьи» постараться найти слабые места на всём протяжении областей человеческого знания.
Здесь лежит определенная хитрость: несмотря на простоту схемы теста, требуется, чтобы «судья» самостоятельно обеспечивал высокий уровень сложности вопросов. Именно наличие человека-«судьи» задает сложность прохождения теста; более того, именно «судья» каждый раз формирует новый, уникальный вызов, на который предстоит ответить машине.
В этом особенность теста Тьюринга: он описывает не столько сам вызов, сколько общие правила формулирования вызова для машин. Это значит, что результаты разных раундов тестирования вряд ли абсолютно сопоставимы между собой, мало предсказуемы, и тем более трудно говорить о какой-либо стандартизации. Исход теста Тьюринга зависит от «судьи» едва ли не в большей степени, чем от машины-кандидата. Без всяких натяжек можно говорить, что человек-«судья» играет в этом испытании более активную роль, чем машина. Всё это является достаточно серьезными недостатками с точки зрения методологии науки. Остается спасаться тем, что описываемый тест проверяет лишь произвольно выбранные рамки возможностей машины и не претендует на строгие выводы и подтверждение фундаментальных концепций.
Но это лишь одна из проблем. Есть и другие, не менее серьезные. Часть из них проистекает из игрового характера теста. Игры стремятся сбалансировать, так, чтобы ни одна из сторон не могла получить преимущество за счет эксплуатации «нечестных» (т. е. не соответствующих духу игры) приемов. К сожалению, Алан Тьюринг не успел оценить баланс сторон на практике. А практика скоро показала, что баланс оставляет желать лучшего.
Дух игры подразумевает, что в ней соревнуются два интеллекта: человеческий и машинный. Но одновременно с человеческим интеллектом в игру привносится и человеческая иррациональность. И вот ее-то оказывается возможным эксплуатировать весьма эффективно.
Сами принципы теста способствуют такой эксплуатации. В конце концов, задача машины — обмануть человека, а не продемонстрировать более качественные знания. И если обмануть человеческий интеллект можно, лишь обладая превосходящим интеллектом, то сыграть на наших иррациональных убеждениях оказывается очень просто.
Более примитивному алгоритму (точнее, его создателям) оказывается выгоднее играть «на понижение», демонстрируя не признаки разумности, но признаки «натуральности» в общении с «судьей». И надеяться на склонность человека к антропоморфизму: мы склонны одушевлять даже самые простые и банальные предметы вокруг себя.
Можно вспомнить про вымышленную Ильфом и Петровым Эллочку-людоедку, которая прекрасно обходилась словарным запасом в 30 слов. А можно просто поглядеть на современное общение в Сети: для выражения широкого спектра мнений молодёжи вполне хватает «лол», «жесть» и пёстрого набора эмотиконов. И становится понятно, что Тьюринг слегка переоценил трудность задачи для машины.
Справедливость этих рассуждений подтверждает успех чатбота «Женя Густман», которому несколько раз удавалось дурачить значительную долю «судей» на значимых конкурсах. А в 2014 — преодолеть установленную организаторами планку в 30% перепутавших программу с человеком. Что дало повод для шквала статей в прессе на тему «Тест Тьюринга пройден!!!1111» и не менее внушительного шквала критики со стороны научного сообщества, направленной на сенсационализм масс-медиа, убогость чатбота «Жени», плохую организацию теста в частности и его фундаментальные ограничения в целом, и еще много чего...
«Женя» пытался персонифицировать 13-летнего мальчика из Одессы. Его английская версия объявляла, что английский язык не является для нее родным. Нежный возраст был призван объяснить пробелы в фундаментальном знании и сыграть на эмоциях. «Они же дети», да. «Женя» умел старательно уходить от вопросов, не стеснялся рассказывать шуточки и вставлять смайлики там, где это необходимо (то есть, практически везде). Иначе говоря, «Женя» агрессивно снижал планку — и это работало, работало на удивление эффективно.
Так что еще раз подчеркнем огромную роль «судьи» в испытании: именно он должен устанавливать планку и не засчитывать попытки испытуемого алгоритма «поднырнуть» под нее. И в связи с тем, что человек является в нем ключевой фигурой, упомянем еще один недостаток теста Тьюринга, отмечаемый теоретиками: его ярко выраженную антропоцентричность. И это еще мягко сказано. Точнее всего эту особенность описал Гэри Фостел: «В тесте Тьюринга проверяется не интеллект, а человечность». Ведь от машины требуется только имитировать человеческую персону, не больше и не меньше.
Впрочем, недостатком это можно назвать только в контексте споров о том, что же представляет собой интеллект. С нашей же точки зрения, антропоцентричный подход лишь очерчивает определенные рамки возможностей, причем далеко не самые широкие. Нам эти рамки интересны еще и потому, что только они позволяют сделать условия теста близкими и интуитивно понятными.
Поскольку недостатки были выявлены серьезные, ряд исследователей предложили свои варианты усовершенствования теста. Один из самых сильных, на мой взгляд, был опубликован в 2003 году Эдвардом Фейгенбаумом. Давайте познакомимся с его особенностями.
Во-первых, тема разговора. Для каждого раунда выбирается определенная область формализованных научных знаний. Фейгенбаум предлагает такие сферы, как естественные науки, медицина и инженерное дело, и допускает, что список может быть расширен (например, гуманитарные науки?).
Во-вторых, участники. В качестве игрока-человека, отвечающего на вопросы, и в качестве «судьи», выступают ведущие специалисты в своей области, элитные учёные (скажем, члены Академии Наук). Допустим, это двое астрофизиков, или спецов по информатике, или по молекулярной биологии.
В-третьих, суть общения. «Судья» постулирует проблемы в своей области, задает вопросы, требует теоретически обоснованного объяснения и так далее. Происходящее можно сравнить с «экзаменом» на очень глубокое владение темой или на защиту ученой степени. Сможет ли машина справиться с дискуссией настолько хорошо, что «судья»-академик не сможет отличить ее от своего титулованного коллеги?
Для более надежного результата Фейгенбаум советует «экзаменовать» машину на нескольких парах специалистов. А самим специалистам, чтобы усложнить тест, следует общаться на языке, насыщенном терминами и оборотами из своей предметной области, которые необязательно понятны простому «человеку с улицы».
Фейгенбаум называет свой тест «Очень великим вызовом» (англ. «Very Grand Challenge»). И такое определение вполне оправдано: сложность этого теста невероятно высока. Когда алгоритм сможет на равных дискутировать со светилами науки и ведущими инженерами, представления об ИИ из научной фантастики станут очень близкими к реальности...
Но до этого момента еще очень далеко. Пока ни у кого даже нет и мысли выставлять свои программы против экспертов в тесте Фейгенбаума. А вот конкурсы по более простому тесту Тьюринга проводятся уже несколько десятилетий. Существует несколько организаций, популяризующих этот тест. Cтарейшим и самым влиятельным считается конкурс на премию Лёбнера, организуемый ежегодно с 1991.
Конкурс проводится в Блетчли-Парк - бывшей усадьбе, в которой в годы Второй Мировой Тьюринг с коллегами взламывали немецкие шифры
Премия Лёбнера имеет свой призовой фонд ($4000 за 1 место) и отличается вполне серьезным подходом к делу. По мере совершенствования алгоритмов организаторам пришлось ужесточить требования к судейскому корпусу. Теперь алгоритмы оценивают представители научного сообщества, профессионалы индустрии, а также представители масс-медиа. Притворяться «13-летним мальчиком» стало не так просто.
Очередной конкурс завершился совсем недавно. Давайте посмотрим, что в нем показала программа, занявшее первое место - «Мицуку», созданная Стивом Уорсвиком. «Мицуку» занимает первое место уже третий год подряд, кроме того, на ее счету победа на премии Лёбнера-2013 и нескольких других конкурсах. Чатбот разрабатывается Уорсвиком с 2005 года.
Вот часть переписки «Мицуку» с одним из «судей», Дж. Харрисом, возглавляющим исследование технологий в стартапе «CognitionX». (Все раунды доступны по ссылке)
Как видим, всё идет наперекосяк уже с третьей реплики бота. Не слишком уместный скрипт заставлял «Мицуку» писать сообщения «судье», если прошло более 60 секунд с момента последнего ответа. Харрис моментально «раскусил» эту особенность, и в дальнейшем такие запросы программы его здорово раздражали. («Судье» нужно было время, чтобы одновременно разговаривать с другим участником-человеком и делать заметки).
Дальше «судья» изучает изъяны «машинного интеллекта», постепенно теряя к нему интерес. И становится предельно понятно, что речь идет не об изъянах интеллекта, а о примитивном подборе готовых ответов под реплики судьи, зачастую малоуспешном. А ведь это программа, третий год удерживающая «чемпионский» статус, объективно одна из лучших...
Аватар "Мицуку" в "Twitch". Если не получается вытягивать за счет мозгов, приходится полагаться на внешние данные...
Вспомним еще раз об игровом характере теста Тьюринга. Для того, чтобы игра удалась, необходимо, чтобы вызовы были соразмерны способностям участников. Но сейчас — и это признают сами участвующие в конкурсе разработчики — пропасть между «мыслящей машиной», какой представлял её Тьюринг, и нынешними чатботами безбрежна и непреодолима. Нынешние конкурсы и тесты, по сути, представляют собой «игру в одни ворота». Либо гротескное искажение замысла теста, в котором не люди определяют интеллект машин, а машины тестируют человеческую глупость. Вероятно, именно поэтому специалисты по ИИ не считают, что тест Тьюринга имеет сейчас хоть какой-то полезный практический смысл.
«Мицуку», как и многие другие программы, участвовавшие в конкурсе, написана на AIML. Это разновидность XML, которая предназначена для организации базы реплик чатботов и их контекстно-зависимой выдачи. Результаты конкурса на премию Лёбнера хорошо демонстрируют пределы такого подхода в создании «умных» алгоритмов. Кропотливое создание базы знаний вручную одним человеком или небольшой командой в конечном итоге заводит в тупик: количество возможных вопросов необъятно, а их логическая взаимосвязь делает использование заранее заготовленных ответов бессмысленным.
Чтобы выйти из этого тупика и преодолеть существующую пропасть, нужны альтернативные подходы. Некоторые из них будут обсуждаться далее. Пока же, дабы закончить на позитивной ноте, предлагаю (при базовом знании английского) поболтать с «Мицуку». Пускай до серьезной борьбы в тесте Тьюринга ей далеко, она хотя бы способна немного вас развлечь.
/ (C) Источник
Не является индивидуальной инвестиционной рекомендацией
При копировании ссылка обязательна Нашли ошибку: выделить и нажать Ctrl+Enter