


24 августа 2018 Trade Like A Pro
Разработка торговых экспертов на языке MQL4 является не такой уж простой задачей. Во-первых — алгоритмизация любой сложной торговой системы уже представляет собой проблему, так как нужно учесть очень много деталей, начиная с особенностей ТС и заканчивая спецификой среды MetaTrader 4. Во-вторых, даже наличие детальнейшего алгоритма не избавляет от сложностей, возникающих при переносе разработанного алгоритма на язык программирования MQL4.
Компилятор оказывает некоторую помощь при написании корректных экспертов. После начала компиляции MetaEditor сообщит обо всех синтаксических ошибках в вашем коде. Но, к сожалению, помимо синтаксических ошибок ваш советник может содержать еще и логические ошибки, которые компилятор выловить не может. Поэтому этим нам придется заняться самим. Как это сделать — в нашем сегодняшнем материале.
Самые распространенные ошибки компиляции
При наличии ошибок в коде программа не может быть скомпилирована. Для полного контроля всех ошибок рекомендуется использовать строгий режим компиляции, который устанавливается директивой:
Этот режим значительно упрощает поиск ошибок. Теперь перейдем к самым распространенным ошибкам при компиляции.
Идентификатор совпадает с зарезервированным словом
Если наименование переменной или функции совпадает с одним из зарезервированных слов:
то компилятор выводит сообщения об ошибках:
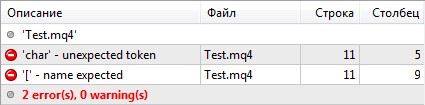
Для исправления данной ошибки нужно исправить имя переменной или функции. Я рекомендую придерживаться следующей системы для именования:
Все функции должны обозначать действие. То есть это должен быть глагол. Например, OpenLongPosition() или ModifyStopLoss(). Ведь функции всегда именно что-то делают, верно?
Кроме того, функции желательно называть в так называемом CamelCase стиле. А переменные в cebab_case стиле. Это общепринятая практика.
Кстати, об именах переменных. Переменные — это существительные. Например, my_stop_loss, day_of_week, current_month. Не так страшно назвать переменную длинным именем, гораздо страшнее назвать ее непонятно. Что такое dow, индекс Dow Jones? Нет, это, оказывается, день недели. Конечно, сегодня вам и так понятно, что это за переменная. Но когда вы откроете код советника месяц спустя, все будет уже не так явно. А это время, упущенное на расшифровку посланий из прошлого – оно вам надо?
Специальные символы в наименованиях переменных и функций
Идем дальше. Если наименования переменных или функций содержат специальные символы ($, @, точка):
то компилятор выводит сообщения об ошибках:
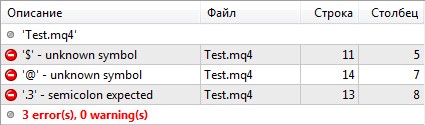
Для исправления данной ошибки снова нужно скорректировать имена переменных или функций, ну или сразу называть их по-человечески. В идеале код нужно писать так, чтобы даже человек, не знающий программирование, просто его прочел и понял, что там вообще происходит.
Ошибки использования оператора switch
Старая версия компилятора позволяла использовать любые значения в выражениях и константах оператора switch:
В новом компиляторе выражения и константы оператора switch должны быть целыми числами, поэтому при использовании подобных конструкций возникают ошибки:
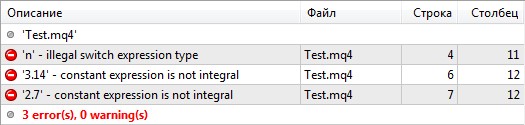
Поэтому, когда вы разбираете код классики, такой, как WallStreet, Ilan и прочей нетленки (что очень полезно для саморазвития), можно натолкнуться на эту ошибку. Лечится она очень просто, например, при использовании такой вот строки:
Вот так можно запросто решить проблему:
Возвращаемые значений функций
Все функции, кроме void, должны возвращать значение объявленного типа. Например:
При строгом режиме компиляции (strict) возникает ошибка:

В режиме компиляции по умолчанию компилятор выводит предупреждение:

Если возвращаемое значение функции не соответствует объявлению:
Тогда при строгом режиме компиляции возникает ошибка:

В режиме компиляции по умолчанию компилятор выводит предупреждение:

Для исправления таких ошибок в код функции всего-навсего нужно добавить оператор возврата return c возвращаемым значением соответствующего типа.
Массивы в аргументах функций
Массивы в аргументах функций передаются только по ссылке. Раньше это было не так, поэтому в старых советниках можно встретить эту ошибку. Вот пример:
Данный код при строгом режиме компиляции (strict) приведет к ошибке:

В режиме компиляции по умолчанию компилятор выводит предупреждение:

Для исправления таких ошибок нужно явно указать передачу массива по ссылке, добавив префикс & перед именем массива:
Кстати, константные массивы (Time[], Open[], High[], Low[], Close[], Volume[]) не могут быть переданы по ссылке. Например, вызов:
вне зависимости от режима компиляции приводит к ошибке:

Для устранения подобных ошибок нужно скопировать необходимые данные из константного массива:
Одна из самых распространенных ошибок – потеря советником индикатора. В таких случаях обычно пользователи эксперта на форумах гневно пишут: «Советник не работает!» или «Ставлю советник на график и ничего не происходит!». Решение этого вопроса на самом деле очень простое. Как всегда, достаточно просто заглянуть на вкладку «Журнал» терминала и обнаружить там запись вроде:
Говорит это нам о том, что индикатор в папку положить забыли, или же он назван по-другому. Если индикатор отсутствует, нужно добавить его в папку с индикаторами. Если он есть, стоит проверить его название в коде советника – скорее всего там он называется по-другому.
Предупреждения компилятора
Предупреждения компилятора носят информационный характер и не являются сообщениями об ошибках, однако они указывают на возможные источники ошибок и лучше их скорректировать. Чистый код не должен содержать предупреждений.
Пересечения имен глобальных и локальных переменных
Если на глобальном и локальном уровнях присутствуют переменные с одинаковыми именами:
то компилятор выводит предупреждение и укажет номер строки, на которой объявлена глобальная переменная:

Для исправления таких предупреждений нужно скорректировать имена глобальных переменных.
Несоответствие типов
В следующем примере:
при строгом режиме компиляции при несоответствии типов компилятор выводит предупреждения:
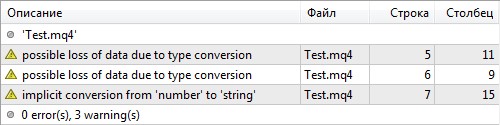
В данном примере компилятор предупреждает о возможной потере точности при присвоении различных типов данных и неявном преобразовании типа int в string.
Для исправления нужно использовать явное приведение типов:
Неиспользуемые переменные
Наличие переменных, которые не используются в коде программы (лишние сущности) не является хорошим тоном.
Сообщения о таких переменных выводятся вне зависимости от режима компиляции:
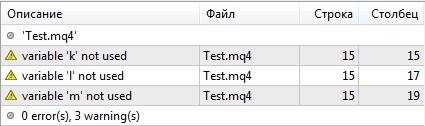
Для исправления нужно просто убрать неиспользуемые переменные из кода программы.
Диагностика ошибок при компиляции
Часто после написания программы возникают проблемы при компиляции, вызванные ошибками в коде. Это могут быть самые различные ошибки, но в любом случае возникает необходимость оперативного обнаружения участка кода, где допущена ошибка.
Нередко у людей уходит немало времени и масса нервов на поиски какой-нибудь лишней скобки. Однако, есть способ быстрого обнаружения ошибок, который основан на использовании комментирования.
Написать достаточно большой код без единой ошибки – очень приятно. Но, к сожалению, так получается не часто. Я не рассматриваю здесь ошибки, которые приводят к неверному исполнению кода. Здесь пойдёт речь об ошибках, из-за которых становится невозможной компиляция.
Весьма распространённые ошибки – вставка лишней скобки в сложном условии, нехватка скобки, не выставление двоеточия, запятой при объявлении переменных, опечатка в названии переменной и так далее. Часто при компиляции можно сразу увидеть, в какой строке допущена подобная ошибка. Но бывают и случаи, когда найти такую ошибку не так просто. Ни компилятор, ни зоркий глаз нам не могут помочь сразу найти ошибку. В таких случаях, как правило, начинающие программисты начинают «обходить» весь код, пытаясь визуально определить ошибку. И снова, и снова, пока выдерживают нервы.
Однако MQL, как и другие языки программирования, предлагает отличный инструмент – комментирование. Используя его, можно отключать какие-то участки кода. Обычно комментирование используют именно для вставки каких-то комментариев, или же отключения неиспользуемых участков кода. Комментирование можно также успешно применять и при поиске ошибок.
Поиск ошибок обычно сводится к определению участка кода, где допущена ошибка, а затем, в этом участке, визуально находится ошибка. Думаю, вряд ли кто-то будет сомневаться в том, что исследовать «на глаз» 5-10 строчек кода проще и быстрей, чем 100-500, а то и несколько тысяч.
При использовании комментирования задача предельно проста. Сначала нужно закомментировать различные участки кода (иногда чуть ли не весь код), тем самым «отключив» его. Затем, по очереди, комментирование снимается с этих участков кода. После очередного снятия комментирования совершается попытка компиляции. Если компиляция прошла успешно – ошибка не в этом участке кода. Затем открывается следующий участок кода и так далее. Когда находится проблемный участок кода, визуально ищется ошибка, затем устраняется. Опять происходит попытка компиляции. Если всё прошло успешно, ошибка устранена.
Важно правильно определять участки кода, которые необходимо комментировать. Если это условие (или иная логическая конструкция), то оно должно комментироваться полностью. Если комментируется участок кода, где объявляются переменные, важно, чтобы не был открыт участок, где происходит обращение к этим переменным. Иначе говоря — комментирование должно применяться по логике программирования. Несоблюдения такого подхода приводит к возникновению новых, вводящих в заблуждение, ошибок при компиляции.
Вот отличный пример ошибки, когда неясно, где ее искать и нас может выручить комментирование кода.

Ошибки времени выполнения
Ошибки, возникающие в процессе исполнения кода программы, принято называть ошибками времени выполнения (runtime errors). Такие ошибки обычно зависят от состояния программы и связаны с некорректными значениями переменных.
Например, если переменная используется в качестве индекса элементов массива, то ее отрицательные значения неизбежно приведут к выходу за пределы массива.
Выход за пределы массива (Array out of range)
Эта ошибка часто возникает в индикаторах при обращении к индикаторным буферам. Функция IndicatorCounted() возвращает количество баров, не изменившихся после последнего вызова индикатора. Значения индикаторов на уже рассчитанных ранее барах не нуждаются в пересчете, поэтому для ускорения расчетов достаточно обрабатывать только несколько последних баров.
Большинство индикаторов, в которых используется данный способ оптимизации вычислений, имеют такой вид:
Часто встречается некорректная обработка случая counted_bars==0 (начальную позицию limit нужно уменьшить на значение, равное 1 + максимальный индекс относительно переменной цикла).
Также следует помнить о том, что в момент исполнения функции start() мы можем обращаться к элементам массивов индикаторных буферов от 0 до Bars()-1. Если есть необходимость работы с массивами, которые не являются индикаторными буферами, то их размер следует увеличить при помощи функции ArrayResize() в соответствии с текущим размером индикаторных буферов. Максимальный индекс элемента для адресации также можно получить вызовом ArraySize() с одним из индикаторных буферов в качестве аргумента.
Деление на ноль (Zero divide)
Ошибка «Zero divide» возникает в случае, если при выполнении операции деления делитель оказывается равен нулю:
При выполнении данного скрипта во вкладке «Эксперты» возникает сообщение об ошибке и завершении работы программы:
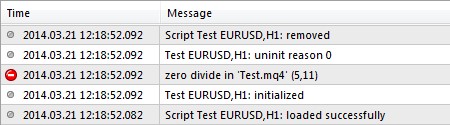
Обычно такая ошибка возникает в случаях, когда значение делителя определяется значениями каких-либо внешних данных. Например, если анализируются параметры торговли, то величина задействованной маржи оказывается равна 0, если нет открытых ордеров. Другой пример: если анализируемые данные считываются из файла, то в случае его отсутствия нельзя гарантировать корректную работу. По этой причине желательно стараться учитывать подобные случаи и корректно их обрабатывать.
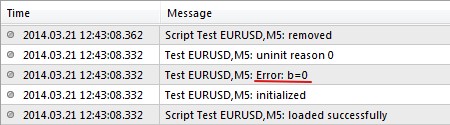
Самый простой способ — проверять делитель перед операцией деления и выводить сообщение о некорректном значении параметра:
В результате критической ошибки не возникает, но выводится сообщение о некорректном значении параметра и работа завершается:
Использование 0 вместо NULL для текущего символа
В старой версии компилятора допускалось использование 0 (нуля) в качестве аргумента в функциях, требующих указания финансового инструмента.
Например, значение технического индикатора Moving Average для текущего символа можно было запрашивать следующим образом:
В новом компиляторе для указания текущего символа нужно явно указывать NULL:
Кроме того, текущий символ и период графика можно указать при помощи функций Symbol() и Period().
Еще лучше, если вы будете использовать предопределенные переменные _Symbol и _Period – они обрабатываются быстрее:
Строки в формате Unicodе и их использование в DLL
Строки представляют собой последовательность символов Unicode. Следует учитывать этот факт и использовать соответствующие функции Windows. Например, при использовании функций библиотеки wininet.dll вместо InternetOpenA() и InternetOpenUrlA() следует вызывать InternetOpenW() и InternetOpenUrlW(). При передаче строк в DLL следует использовать структуру MqlString:
Совместное использование файлов
При открытии файлов необходимо явно указывать флаги FILE_SHARE_WRITE и FILE_SHARE_READ для совместного использования.
В случае их отсутствия, файл будет открыт в монопольном режиме, что не позволит больше никому его открывать, пока он не будет закрыт монополистом.
Например, при работе с оффлайновыми графиками требуется явно указывать флаги совместного доступа:
Особенность преобразования datetime
Следует иметь ввиду, что преобразование типа datetime в строку зависит от режима компиляции:
Например, попытка работы с файлами, имя которых содержит двоеточие, приведет к ошибке.
Обработка ошибок времени выполнения
Так как без использования встроенных пользовательских функций не сможет обойтись ни один торгующий эксперт, то в первую очередь попытаемся упростить себе жизнь при анализе ошибок, возвращаемых этими функциями.
В наборе «из коробки» доступны некоторые библиотеки для упрощения написания советников, в том числе и для работы с ошибками. Хранятся они в папке MQL4/Include:
Нам понадобятся две библиотеки:
stderror.mqh — содержит константы для номера каждой ошибки;
stdlib.mqh — содержит несколько вспомогательных функций, в том числе и функцию возврата описания ошибки в виде строки:
Поэтому подключим в наш проект обе эти библиотеки:
Сами описания ошибок находятся в файле MQL4/Library/stdlib.mql4 и они на английском языке. Поэтому, если вы против иностранных языков, всегда можно переписать описания на свой родной.
Еще одна встроенная необходимая нам функция — GetLastError(). Именно она возвращает коды ошибок в виде целого числа (int), который мы потом будем обрабатывать. Сами коды ошибок и их описания на русском можно посмотреть в руководстве по mql4 от MetaQuotes. Оттуда же можно взять информацию для перевода файла stdlib.mql4 на русский.
Теперь, когда мы подключили необходимые библиотеки, рассмотрим результаты работы функций, непосредственно связанных с торговыми операциями, так как игнорирование сбоев в этих функциях может привести к критическим для бота последствиям.
К сожалению, средствами MQL4 нельзя написать обобщенную библиотеку для обработки всех возможных ошибочных ситуаций. В каждом отдельном случае придется обрабатывать ошибки отдельно. Но не все так плохо, – многие ошибки не нужно обрабатывать, их достаточно исключить на этапе разработки и тестирования эксперта, хотя для этого и нужно вовремя узнать об их наличии.
Рассмотрим для примера две типичные для экспертов на MQL4 ошибки:
Ошибка 130 — ERR_INVALID_STOPS
Ошибка 146 — ERR_TRADE_CONTEXT_BUSY
Одним из случаев, когда возникает первая ошибка, является попытка эксперта выставить отложенный ордер слишком близко к рынку. Ее наличие может серьезно ухудшить показатели эксперта в некоторых случаях. Например, допустим эксперт, открыв прибыльную позицию, поджимает прибыль каждые 150 пунктов. Если при очередной такой попытке возникнет ошибка 130, а цена безвозвратно вернется к предыдущему уровню стопа, эксперт может лишить вас законной прибыли. Несмотря на возможность таких последствий, данную ошибку можно исключить в корне, доработав код эксперта так, чтобы он учитывал минимальное допустимое расстояние между ценой и стопами.
Вторую ошибку, связанную с занятостью торгового контекста терминала, полностью исключить не получится. При работе нескольких экспертов в одном терминале всегда возможна ситуация, когда один из экспертов попытается открыть позицию, пока другой все еще делает то же самое. Следовательно, такую ошибку всегда нужно обрабатывать.
Таким образом, мы всегда должны быть в курсе, если какая-то из используемых встроенных функций возвращает ошибку во время работы эксперта. Добиться этого можно, используя следующую нехитрую вспомогательную функцию:
Использовать ее мы будем следующим образом:
Конечно, это упрощенный пример. Для написания более грамотных функций открытия, закрытия и модификации ордеров смотрите этот урок.
Первым параметром в функцию logError() передается имя функции, в которой была обнаружена ошибка, в нашем примере — в функции openLongTrade(). Если наш эксперт вызывает функцию OrderSend() в нескольких местах, это позволит нам точно установить, в каком из них произошла ошибка. Вторым параметром передается описание ошибки, чтобы можно было понять, где именно внутри функции openLongTrade() была обнаружена ошибка. Это может быть как краткое описание ошибки, так и более развернутое, с перечислением значений всех параметров, переданных во встроенную функцию.
Я предпочитаю последний вариант, так как при возникновении ошибки можно сразу получить всю необходимую для анализа информацию. Для примера допустим, что до вызова OrderSend() текущая цена успела сильно отклониться от последней известной нам цены. В результате при выполнении этого примера произойдет ошибка и в протоколе работы эксперта появятся следующие строки:
То есть сразу будет видно:
в какой функции произошла ошибка;
к чему она относится (в данном случае — к попытке открыть позицию);
какая именно ошибка возникла (код ошибки и ее описание).
Теперь рассмотрим третий, необязательный, параметр функции logError(). Он необходим в тех случаях, когда мы хотим обработать конкретный вид ошибки, а об остальных будем отчитываться в протоколе работы эксперта, как и прежде:
Здесь в функции updateStopLoss() вызывается встроенная функция OrderModify(). Эта функция несколько отличается в плане обработки ошибок от OrderSend(). Если ни один из параметров изменяемого ордера не отличается от его текущих параметров, то функция вернет ошибку ERR_NO_RESULT. Если в нашем эксперте такая ситуация допустима, то мы должны игнорировать конкретно эту ошибку. Для этого мы анализируем значение, возвращаемое GetLastError(). Если произошла ошибка с кодом ERR_NO_RESULT, то мы ничего не выводим в протокол.
Однако если произошла другая ошибка, то необходимо полностью отрапортовать о ней, как мы делали это раньше. Именно для этого мы сохраняем результат функции GetLastError() в промежуточной переменной и передаем его третьим параметром в функцию logError(). Дело в том, что встроенная функция GetLastError() автоматически обнуляет код последней ошибки после своего вызова. Если бы мы не передали код ошибки явно в logError(), то в протоколе была бы отражена ошибка с кодом 0 и описанием «no error».
Похожие действия необходимо совершать и при обработке других ошибок, например, реквотов. Основная идея заключается в том, чтобы обрабатывать только ошибки, требующие обработки, а остальные передавать в функцию logError(). Тогда мы всегда будем в курсе, если во время работы эксперта произошла непредвиденная ошибка. Проанализировав логи, мы сможем решить, требует ли данная ошибка отдельной обработки или же ее можно исключить, доработав код эксперта. Такой подход часто заметно упрощает жизнь и сокращает время, уходящее на борьбу с ошибками.
Диагностика логических ошибок
Логические ошибки в коде эксперта могут доставить много проблем. Отсутствие возможности пошаговой отладки экспертов делают борьбу с такими ошибками не очень приятным занятием. Основным средством для диагностики этого на данный момент является встроенная функция Print(). С ее помощью можно выполнять распечатку текущих значений важных переменных, а также протоколировать ход работы эксперта прямо в терминале во время тестирования. При отладке эксперта во время тестирования с визуализацией также может помочь встроенная функция Comment(), которая выводит сообщения на график. Как правило, убедившись, что эксперт работает не так, как было задумано, приходится добавлять временные вызовы функции Print() и протоколировать внутреннее состояние эксперта в предполагаемых местах возникновения ошибки.
Однако, для обнаружения сложных ошибочных ситуаций порой приходится добавлять десятки таких вызовов функции Print(), а после обнаружения и устранения проблемы их приходится удалять или комментировать, чтобы не загромождался код эксперта и не замедлялось его тестирование. Ситуация ухудшается, если в коде эксперта функция Print() уже используется для периодического протоколирования различных состояний. Тогда удаление временных вызовов Print() не удается выполнить путем простого поиска фразы ‘Print’ в коде эксперта. Приходится задумываться, чтобы не удалить еще и полезные вызовы этой функции.
Например, при протоколировании ошибок функций OrderSend(), OrderModify() и OrderClose() полезным бывает печатать в протокол текущее значение переменных Bid и Ask. Это несколько облегчает распознавание причин таких ошибок, как ERR_INVALID_STOPS и ERR_OFF_QUOTES.
Чтобы выделить такие диагностические выводы в протокол, я рекомендую использовать такую вспомогательную функцию:
Это желательно сделать по нескольким причинам. Во-первых, теперь такие вызовы не будут попадаться при поиске ‘Print’ в коде эксперта, ведь искать мы будем logInfo. Во-вторых, у этой функции есть еще одна полезная особенность, о которой мы поговорим чуть позже.
Добавление и удаление временных диагностических вызовов функции Print() отнимает у нас драгоценное время. Поэтому я предлагаю рассмотреть еще один подход, который эффективен при обнаружении логических ошибок в коде и позволяет немного сэкономить наше время. Рассмотрим следующую несложную функцию:
В данном случае, так как мы открываем длинную позицию, совершенно очевидно, что при нормальной работе эксперта значение параметра stopLoss никогда не будет больше или равно текущей цене Bid. То есть, при вызове функции openLongTrade() всегда выполняется условие stopLoss < Bid. Так как мы знаем об этом еще на этапе написания рассматриваемой функции, то мы сразу же можем этим воспользоваться следующим образом:
То есть мы логируем наше утверждение в коде при помощи новой вспомогательной функции assert(). Сама функция выглядит довольно просто:
Первым параметром функции является ее имя, в котором проверяется наше условие (по аналогии с функцией logError()). Вторым параметром передается результат проверки этого условия. И третьим параметром передается его описание. В результате, если ожидаемое условие не выполняется, в протокол будет выведена следующая информация:
название функции, в которой условие было нарушено;
описание нарушенного условия.
В качестве описания можно передавать, например, само условие, а можно выводить и более подробное описание, содержащее значения контролируемых переменных на момент проверки условия, если это поможет разобраться в причинах ошибки.
Конечно же, рассмотренный пример максимально упрощен. Но, надеюсь, основную идею отражает достаточно хорошо. В процессе наращивания функциональности эксперта мы отдаем себе отчет в том, как он должен работать и какие состояния и входные параметры функций допустимы, а какие нет. Фиксируя это в коде эксперта при помощи функции assert() мы получаем ценную информацию о месте, в котором нарушается логика работы эксперта. Более того, мы частично избавляем себя от необходимости добавлять и удалять временные вызовы функции Print(), так как функция assert() выдает диагностические сообщения в протокол только в момент обнаружения несоответствий в ожидаемых нами условиях.
Еще одним полезным приемом является использование этой функции перед каждой операцией деления. Дело в том, что иногда в результате той или иной логической ошибки иногда происходит деление на ноль. Работа эксперта в этом случае прекращается, а в протоколе появляется одна лишь строка с печальным диагнозом: ‘zero divide’. Узнать, в каком именно месте произошла эта ошибка, если операция деления используется в коде неоднократно, достаточно сложно. Вот здесь и поможет функция assert(). Вставляем соответствующие проверки перед каждой операцией деления:
И теперь, в случае деления на ноль, достаточно будет лишь взглянуть в логи, чтобы узнать, в каком именно месте произошла ошибка.
Обработка состояний
Во время работы эксперта на вашем счете могут возникнуть некоторые ситуации, которые не являются ошибками – так называемые состояния эксперта. Такие состояния не являются ошибками, но все же их стоит логировать. В этом помогают специальные функции языка mql4.
Функция IsExpertEnabled() возвращает информацию о возможности запуска экспертов. Функция вернет true, если в клиентском терминале разрешен запуск экспертов, иначе возвращает false. В случае возврата false полезно будет известить об этом пользователя с просьбой включить соответствующую настройку. Пример:
Если эксперт использует внешние библиотеки, пригодится функция IsLibrariesAllowed(). Она возвращает true, если эксперт может вызвать библиотечную функцию, иначе возвращает false.
Если библиотека в виде dll файла, пригодится функция IsDllsAllowed(). Также нелишним будет проверить, есть ли вообще возможность торговать при помощи экспертов с помощью функции IsTradeAllowed().
Если вы хотите узнать, является ли счет демонстрационным, или же реальным, можно использовать функцию IsDemo().
Все вышеперечисленные проверки стоит сделать в функции OnInit().
Конечно же, стоит проверять периодически связь с сервером. В этом поможет функция IsConnected().
Следующие три функции помогут определить, в каком режиме находится советник. Если IsOptimisation() возвращает true, проводится оптимизация, если IsTesting(), то тестирование, IsVisualMode() – тестирование в режиме визуализации. Под каждый из этих вариантов в советнике может быть предусмотрена своя логика. Например, для режима визуализации можно что-то выводить на график (и не выводить в других режимах ради экономии ресурсов). В режиме тестирования можно выводить отладочную информацию, в режиме оптимизации максимально облегчить код, чтобы сэкономить время.
И последняя функция – IsTradeContextBusy(). Она вернет true, если поток для выполнения торговых операций занят. Это бывает полезно при совершении экспертом торговых операций. Можно применить функцию Sleep для ожидания некоторого момента и новой попытки.
Еще одна полезная функция — UninitializeReason()
Можно также логировать причину выхода советника.
Компилятор оказывает некоторую помощь при написании корректных экспертов. После начала компиляции MetaEditor сообщит обо всех синтаксических ошибках в вашем коде. Но, к сожалению, помимо синтаксических ошибок ваш советник может содержать еще и логические ошибки, которые компилятор выловить не может. Поэтому этим нам придется заняться самим. Как это сделать — в нашем сегодняшнем материале.
Самые распространенные ошибки компиляции
При наличии ошибок в коде программа не может быть скомпилирована. Для полного контроля всех ошибок рекомендуется использовать строгий режим компиляции, который устанавливается директивой:
#property strict
Этот режим значительно упрощает поиск ошибок. Теперь перейдем к самым распространенным ошибкам при компиляции.
Идентификатор совпадает с зарезервированным словом
Если наименование переменной или функции совпадает с одним из зарезервированных слов:
int char[]; // неправильно
int char1[]; // правильно
int char() // неправильно
{
return(0);
}то компилятор выводит сообщения об ошибках:
Для исправления данной ошибки нужно исправить имя переменной или функции. Я рекомендую придерживаться следующей системы для именования:
Все функции должны обозначать действие. То есть это должен быть глагол. Например, OpenLongPosition() или ModifyStopLoss(). Ведь функции всегда именно что-то делают, верно?
Кроме того, функции желательно называть в так называемом CamelCase стиле. А переменные в cebab_case стиле. Это общепринятая практика.
Кстати, об именах переменных. Переменные — это существительные. Например, my_stop_loss, day_of_week, current_month. Не так страшно назвать переменную длинным именем, гораздо страшнее назвать ее непонятно. Что такое dow, индекс Dow Jones? Нет, это, оказывается, день недели. Конечно, сегодня вам и так понятно, что это за переменная. Но когда вы откроете код советника месяц спустя, все будет уже не так явно. А это время, упущенное на расшифровку посланий из прошлого – оно вам надо?
Специальные символы в наименованиях переменных и функций
Идем дальше. Если наименования переменных или функций содержат специальные символы ($, @, точка):
int $var1; // неправильно
int @var2; // неправильно
int var.3; // неправильно
void f@() // неправильно
{
return;
}то компилятор выводит сообщения об ошибках:
Для исправления данной ошибки снова нужно скорректировать имена переменных или функций, ну или сразу называть их по-человечески. В идеале код нужно писать так, чтобы даже человек, не знающий программирование, просто его прочел и понял, что там вообще происходит.
Ошибки использования оператора switch
Старая версия компилятора позволяла использовать любые значения в выражениях и константах оператора switch:
void start()
{
double n=3.14;
switch(n)
{
case 3.14:
Print("Pi");
break;
case 2.7:
Print("E");
break;
}
}В новом компиляторе выражения и константы оператора switch должны быть целыми числами, поэтому при использовании подобных конструкций возникают ошибки:
Поэтому, когда вы разбираете код классики, такой, как WallStreet, Ilan и прочей нетленки (что очень полезно для саморазвития), можно натолкнуться на эту ошибку. Лечится она очень просто, например, при использовании такой вот строки:
switch(MathMod(day_48, 10))Вот так можно запросто решить проблему:
switch((int)MathMod(day_48, 10))Возвращаемые значений функций
Все функции, кроме void, должны возвращать значение объявленного типа. Например:
int function()
{
}При строгом режиме компиляции (strict) возникает ошибка:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
Если возвращаемое значение функции не соответствует объявлению:
int init()
{
return;
}Тогда при строгом режиме компиляции возникает ошибка:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
Для исправления таких ошибок в код функции всего-навсего нужно добавить оператор возврата return c возвращаемым значением соответствующего типа.
Массивы в аргументах функций
Массивы в аргументах функций передаются только по ссылке. Раньше это было не так, поэтому в старых советниках можно встретить эту ошибку. Вот пример:
double ArrayAverage(double a[])
{
return(0);
}Данный код при строгом режиме компиляции (strict) приведет к ошибке:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
Для исправления таких ошибок нужно явно указать передачу массива по ссылке, добавив префикс & перед именем массива:
double ArrayAverage(double &a[])
{
return(0);
}Кстати, константные массивы (Time[], Open[], High[], Low[], Close[], Volume[]) не могут быть переданы по ссылке. Например, вызов:
ArrayAverage(Open);вне зависимости от режима компиляции приводит к ошибке:
Для устранения подобных ошибок нужно скопировать необходимые данные из константного массива:
//--- массив для хранения значений цен открытия
double OpenPrices[];
//--- копируем значения цен открытия в массив OpenPrices[]
ArrayCopy(OpenPrices,Open,0,0,WHOLE_ARRAY);
//--- вызываем функцию
ArrayAverage(OpenPrices);Одна из самых распространенных ошибок – потеря советником индикатора. В таких случаях обычно пользователи эксперта на форумах гневно пишут: «Советник не работает!» или «Ставлю советник на график и ничего не происходит!». Решение этого вопроса на самом деле очень простое. Как всегда, достаточно просто заглянуть на вкладку «Журнал» терминала и обнаружить там запись вроде:
2018.07.08 09:15:44.957 2016.01.04 00:51 cannot open file
'C:Users1AppDataRoamingMetaQuotesTerminal
MQL4indicatorsKELTNER_F12.ex4' [2]Говорит это нам о том, что индикатор в папку положить забыли, или же он назван по-другому. Если индикатор отсутствует, нужно добавить его в папку с индикаторами. Если он есть, стоит проверить его название в коде советника – скорее всего там он называется по-другому.
Предупреждения компилятора
Предупреждения компилятора носят информационный характер и не являются сообщениями об ошибках, однако они указывают на возможные источники ошибок и лучше их скорректировать. Чистый код не должен содержать предупреждений.
Пересечения имен глобальных и локальных переменных
Если на глобальном и локальном уровнях присутствуют переменные с одинаковыми именами:
int i; // глобальная переменная
void OnStart()
{
int i=0,j=0; // локальные переменные
for (i=0; i<5; i++) {
j+=i;
}
PrintFormat("i=%d, j=%d",i,j);
}то компилятор выводит предупреждение и укажет номер строки, на которой объявлена глобальная переменная:
Для исправления таких предупреждений нужно скорректировать имена глобальных переменных.
Несоответствие типов
В следующем примере:
#property strict
void OnStart()
{
double a=7;
float b=a;
int c=b;
string str=c;
Print(c);
}при строгом режиме компиляции при несоответствии типов компилятор выводит предупреждения:
В данном примере компилятор предупреждает о возможной потере точности при присвоении различных типов данных и неявном преобразовании типа int в string.
Для исправления нужно использовать явное приведение типов:
#property strict
void OnStart()
{
double a=7;
float b=(float)a;
int c=(int)b;
string str=(string)c;
Print(c);
}Неиспользуемые переменные
Наличие переменных, которые не используются в коде программы (лишние сущности) не является хорошим тоном.
void OnStart()
{
int i,j=10,k,l,m,n2=1;
for(i=0; i<5; i++) {j+=i;}
}Сообщения о таких переменных выводятся вне зависимости от режима компиляции:
Для исправления нужно просто убрать неиспользуемые переменные из кода программы.
Диагностика ошибок при компиляции
Часто после написания программы возникают проблемы при компиляции, вызванные ошибками в коде. Это могут быть самые различные ошибки, но в любом случае возникает необходимость оперативного обнаружения участка кода, где допущена ошибка.
Нередко у людей уходит немало времени и масса нервов на поиски какой-нибудь лишней скобки. Однако, есть способ быстрого обнаружения ошибок, который основан на использовании комментирования.
Написать достаточно большой код без единой ошибки – очень приятно. Но, к сожалению, так получается не часто. Я не рассматриваю здесь ошибки, которые приводят к неверному исполнению кода. Здесь пойдёт речь об ошибках, из-за которых становится невозможной компиляция.
Весьма распространённые ошибки – вставка лишней скобки в сложном условии, нехватка скобки, не выставление двоеточия, запятой при объявлении переменных, опечатка в названии переменной и так далее. Часто при компиляции можно сразу увидеть, в какой строке допущена подобная ошибка. Но бывают и случаи, когда найти такую ошибку не так просто. Ни компилятор, ни зоркий глаз нам не могут помочь сразу найти ошибку. В таких случаях, как правило, начинающие программисты начинают «обходить» весь код, пытаясь визуально определить ошибку. И снова, и снова, пока выдерживают нервы.
Однако MQL, как и другие языки программирования, предлагает отличный инструмент – комментирование. Используя его, можно отключать какие-то участки кода. Обычно комментирование используют именно для вставки каких-то комментариев, или же отключения неиспользуемых участков кода. Комментирование можно также успешно применять и при поиске ошибок.
Поиск ошибок обычно сводится к определению участка кода, где допущена ошибка, а затем, в этом участке, визуально находится ошибка. Думаю, вряд ли кто-то будет сомневаться в том, что исследовать «на глаз» 5-10 строчек кода проще и быстрей, чем 100-500, а то и несколько тысяч.
При использовании комментирования задача предельно проста. Сначала нужно закомментировать различные участки кода (иногда чуть ли не весь код), тем самым «отключив» его. Затем, по очереди, комментирование снимается с этих участков кода. После очередного снятия комментирования совершается попытка компиляции. Если компиляция прошла успешно – ошибка не в этом участке кода. Затем открывается следующий участок кода и так далее. Когда находится проблемный участок кода, визуально ищется ошибка, затем устраняется. Опять происходит попытка компиляции. Если всё прошло успешно, ошибка устранена.
Важно правильно определять участки кода, которые необходимо комментировать. Если это условие (или иная логическая конструкция), то оно должно комментироваться полностью. Если комментируется участок кода, где объявляются переменные, важно, чтобы не был открыт участок, где происходит обращение к этим переменным. Иначе говоря — комментирование должно применяться по логике программирования. Несоблюдения такого подхода приводит к возникновению новых, вводящих в заблуждение, ошибок при компиляции.
Вот отличный пример ошибки, когда неясно, где ее искать и нас может выручить комментирование кода.
Ошибки времени выполнения
Ошибки, возникающие в процессе исполнения кода программы, принято называть ошибками времени выполнения (runtime errors). Такие ошибки обычно зависят от состояния программы и связаны с некорректными значениями переменных.
Например, если переменная используется в качестве индекса элементов массива, то ее отрицательные значения неизбежно приведут к выходу за пределы массива.
Выход за пределы массива (Array out of range)
Эта ошибка часто возникает в индикаторах при обращении к индикаторным буферам. Функция IndicatorCounted() возвращает количество баров, не изменившихся после последнего вызова индикатора. Значения индикаторов на уже рассчитанных ранее барах не нуждаются в пересчете, поэтому для ускорения расчетов достаточно обрабатывать только несколько последних баров.
Большинство индикаторов, в которых используется данный способ оптимизации вычислений, имеют такой вид:
//+------------------------------------------------------------------+
//| Custom indicator iteration function |
//+------------------------------------------------------------------+
int start()
{
//--- иногда для расчета требуется не менее N баров (например, 100)
// если на графике нет такого количества баров (например, на таймфрейме MN)
if (Bars<100) {
return(-1); // прекращаем расчет и выходим досрочно
}
//--- количество баров, не изменившихся с момента последнего вызова индикатора
int counted_bars=IndicatorCounted();
//--- в случае ошибки выходим
if (counted_bars<0) {
return(-1);
}
//--- позиция бара, с которого начинается расчет в цикле
int limit=Bars-counted_bars;
//--- если counted_bars=0, то начальную позицию в цикле нужно уменьшить на 1,
if (counted_bars==0) {
limit--; // чтобы не выйти за пределы массива при counted_bars==0
//--- в расчетах используется смещение на 10 баров вглубь
//--- истории, поэтому добавим это смещение при первом расчете
limit-=10;
} else {
//--- индикатор уже рассчитывался ранее, counted_bars>0
//--- при повторных вызовах увеличим limit на 1, чтобы
//--- гарантированно обновлять значения индикатора для последнего бара
limit++;
}
//--- основной цикл расчета
for (int i=limit; i>0; i--) {
// используются значения баров, уходящих вглубь истории на 5 и 10
Buff1[i]=0.5*(Open[i+5]+Close[i+10])
}
}Часто встречается некорректная обработка случая counted_bars==0 (начальную позицию limit нужно уменьшить на значение, равное 1 + максимальный индекс относительно переменной цикла).
Также следует помнить о том, что в момент исполнения функции start() мы можем обращаться к элементам массивов индикаторных буферов от 0 до Bars()-1. Если есть необходимость работы с массивами, которые не являются индикаторными буферами, то их размер следует увеличить при помощи функции ArrayResize() в соответствии с текущим размером индикаторных буферов. Максимальный индекс элемента для адресации также можно получить вызовом ArraySize() с одним из индикаторных буферов в качестве аргумента.
Деление на ноль (Zero divide)
Ошибка «Zero divide» возникает в случае, если при выполнении операции деления делитель оказывается равен нулю:
void OnStart()
{
int a=0, b=0,c;
c=a/b;
Print("c=",c);
}При выполнении данного скрипта во вкладке «Эксперты» возникает сообщение об ошибке и завершении работы программы:
Обычно такая ошибка возникает в случаях, когда значение делителя определяется значениями каких-либо внешних данных. Например, если анализируются параметры торговли, то величина задействованной маржи оказывается равна 0, если нет открытых ордеров. Другой пример: если анализируемые данные считываются из файла, то в случае его отсутствия нельзя гарантировать корректную работу. По этой причине желательно стараться учитывать подобные случаи и корректно их обрабатывать.
Самый простой способ — проверять делитель перед операцией деления и выводить сообщение о некорректном значении параметра:
void OnStart()
{
int a=0, b=0,c;
if (b!=0) {
c=a/b; Print(c);
} else {
Print("Error: b=0");
return;
}
}В результате критической ошибки не возникает, но выводится сообщение о некорректном значении параметра и работа завершается:
Использование 0 вместо NULL для текущего символа
В старой версии компилятора допускалось использование 0 (нуля) в качестве аргумента в функциях, требующих указания финансового инструмента.
Например, значение технического индикатора Moving Average для текущего символа можно было запрашивать следующим образом:
AlligatorJawsBuffer[i]=iMA(0,0,13,8,MODE_SMMA,PRICE_MEDIAN,i); // неправильноВ новом компиляторе для указания текущего символа нужно явно указывать NULL:
AlligatorJawsBuffer[i]=iMA(NULL,0,13,8,MODE_SMMA,PRICE_MEDIAN,i); // правильноКроме того, текущий символ и период графика можно указать при помощи функций Symbol() и Period().
AlligatorJawsBuffer[i]=iMA(Symbol(),Period(),13,8,MODE_SMMA,PRICE_MEDIAN,i); // правильноЕще лучше, если вы будете использовать предопределенные переменные _Symbol и _Period – они обрабатываются быстрее:
AlligatorJawsBuffer[i]=iMA(_Symbol,_Period,13,8,MODE_SMMA,PRICE_MEDIAN,i); // правильноСтроки в формате Unicodе и их использование в DLL
Строки представляют собой последовательность символов Unicode. Следует учитывать этот факт и использовать соответствующие функции Windows. Например, при использовании функций библиотеки wininet.dll вместо InternetOpenA() и InternetOpenUrlA() следует вызывать InternetOpenW() и InternetOpenUrlW(). При передаче строк в DLL следует использовать структуру MqlString:
#pragma pack(push,1)
struct MqlString
{
int size; // 32-битное целое, содержит размер распределенного для строки буфера
LPWSTR buffer; // 32-разрядный адрес буфера, содержащего строку
int reserved; // 32-битное целое, зарезервировано, не использовать
};
#pragma pack(pop,1)Совместное использование файлов
При открытии файлов необходимо явно указывать флаги FILE_SHARE_WRITE и FILE_SHARE_READ для совместного использования.
В случае их отсутствия, файл будет открыт в монопольном режиме, что не позволит больше никому его открывать, пока он не будет закрыт монополистом.
Например, при работе с оффлайновыми графиками требуется явно указывать флаги совместного доступа:
// 1-st change - add share flags
ExtHandle=FileOpenHistory(c_symbol+i_period+".hst",
FILE_BIN|FILE_WRITE|FILE_SHARE_WRITE|FILE_SHARE_READ);Особенность преобразования datetime
Следует иметь ввиду, что преобразование типа datetime в строку зависит от режима компиляции:
datetime date=D'2014.03.05 15:46:58';
string str="mydate="+date;
//--- str="mydate=1394034418" - без директивы #property strict
//--- str="mydate=2014.03.05 15:46:58" - с директивой #property strictНапример, попытка работы с файлами, имя которых содержит двоеточие, приведет к ошибке.
Обработка ошибок времени выполнения
Так как без использования встроенных пользовательских функций не сможет обойтись ни один торгующий эксперт, то в первую очередь попытаемся упростить себе жизнь при анализе ошибок, возвращаемых этими функциями.
В наборе «из коробки» доступны некоторые библиотеки для упрощения написания советников, в том числе и для работы с ошибками. Хранятся они в папке MQL4/Include:
Нам понадобятся две библиотеки:
stderror.mqh — содержит константы для номера каждой ошибки;
stdlib.mqh — содержит несколько вспомогательных функций, в том числе и функцию возврата описания ошибки в виде строки:
string ErrorDescription(int error_code)Поэтому подключим в наш проект обе эти библиотеки:
#include <stderror.mqh>
#include <stdlib.mqh>Сами описания ошибок находятся в файле MQL4/Library/stdlib.mql4 и они на английском языке. Поэтому, если вы против иностранных языков, всегда можно переписать описания на свой родной.
Еще одна встроенная необходимая нам функция — GetLastError(). Именно она возвращает коды ошибок в виде целого числа (int), который мы потом будем обрабатывать. Сами коды ошибок и их описания на русском можно посмотреть в руководстве по mql4 от MetaQuotes. Оттуда же можно взять информацию для перевода файла stdlib.mql4 на русский.
Теперь, когда мы подключили необходимые библиотеки, рассмотрим результаты работы функций, непосредственно связанных с торговыми операциями, так как игнорирование сбоев в этих функциях может привести к критическим для бота последствиям.
К сожалению, средствами MQL4 нельзя написать обобщенную библиотеку для обработки всех возможных ошибочных ситуаций. В каждом отдельном случае придется обрабатывать ошибки отдельно. Но не все так плохо, – многие ошибки не нужно обрабатывать, их достаточно исключить на этапе разработки и тестирования эксперта, хотя для этого и нужно вовремя узнать об их наличии.
Рассмотрим для примера две типичные для экспертов на MQL4 ошибки:
Ошибка 130 — ERR_INVALID_STOPS
Ошибка 146 — ERR_TRADE_CONTEXT_BUSY
Одним из случаев, когда возникает первая ошибка, является попытка эксперта выставить отложенный ордер слишком близко к рынку. Ее наличие может серьезно ухудшить показатели эксперта в некоторых случаях. Например, допустим эксперт, открыв прибыльную позицию, поджимает прибыль каждые 150 пунктов. Если при очередной такой попытке возникнет ошибка 130, а цена безвозвратно вернется к предыдущему уровню стопа, эксперт может лишить вас законной прибыли. Несмотря на возможность таких последствий, данную ошибку можно исключить в корне, доработав код эксперта так, чтобы он учитывал минимальное допустимое расстояние между ценой и стопами.
Вторую ошибку, связанную с занятостью торгового контекста терминала, полностью исключить не получится. При работе нескольких экспертов в одном терминале всегда возможна ситуация, когда один из экспертов попытается открыть позицию, пока другой все еще делает то же самое. Следовательно, такую ошибку всегда нужно обрабатывать.
Таким образом, мы всегда должны быть в курсе, если какая-то из используемых встроенных функций возвращает ошибку во время работы эксперта. Добиться этого можно, используя следующую нехитрую вспомогательную функцию:
void logError(string functionName, string msg, int errorCode = -1)
{
Print("ERROR: in " + functionName + "()");
Print("ERROR: " + msg );
int err = GetLastError();
if (errorCode != -1) {
err = errorCode;
}
if (err != ERR_NO_ERROR) {
Print("ERROR: code=" + err + " - " + ErrorDescription( err ));
}
}Использовать ее мы будем следующим образом:
void openLongTrade()
{
int ticket = OrderSend(Symbol(), OP_BUY, 1.0, Ask + 5, 5, 0, 0);
if (ticket == -1) {
logError("openLongTrade", "could not open order");
}
}Конечно, это упрощенный пример. Для написания более грамотных функций открытия, закрытия и модификации ордеров смотрите этот урок.
Первым параметром в функцию logError() передается имя функции, в которой была обнаружена ошибка, в нашем примере — в функции openLongTrade(). Если наш эксперт вызывает функцию OrderSend() в нескольких местах, это позволит нам точно установить, в каком из них произошла ошибка. Вторым параметром передается описание ошибки, чтобы можно было понять, где именно внутри функции openLongTrade() была обнаружена ошибка. Это может быть как краткое описание ошибки, так и более развернутое, с перечислением значений всех параметров, переданных во встроенную функцию.
Я предпочитаю последний вариант, так как при возникновении ошибки можно сразу получить всю необходимую для анализа информацию. Для примера допустим, что до вызова OrderSend() текущая цена успела сильно отклониться от последней известной нам цены. В результате при выполнении этого примера произойдет ошибка и в протоколе работы эксперта появятся следующие строки:
ERROR: in openLongTrade()
ERROR: could not open order
ERROR: code=138 - requoteТо есть сразу будет видно:
в какой функции произошла ошибка;
к чему она относится (в данном случае — к попытке открыть позицию);
какая именно ошибка возникла (код ошибки и ее описание).
Теперь рассмотрим третий, необязательный, параметр функции logError(). Он необходим в тех случаях, когда мы хотим обработать конкретный вид ошибки, а об остальных будем отчитываться в протоколе работы эксперта, как и прежде:
void updateStopLoss(double newStopLoss)
{
bool modified = OrderModify(OrderTicket(), OrderOpenPrice(),
newStopLoss, OrderTakeProfit(), OrderExpiration());
if (!modified) {
int errorCode = GetLastError();
if (errorCode != ERR_NO_RESULT ) {
logError("updateStopLoss", "failed to modify order", errorCode);
}
}
}Здесь в функции updateStopLoss() вызывается встроенная функция OrderModify(). Эта функция несколько отличается в плане обработки ошибок от OrderSend(). Если ни один из параметров изменяемого ордера не отличается от его текущих параметров, то функция вернет ошибку ERR_NO_RESULT. Если в нашем эксперте такая ситуация допустима, то мы должны игнорировать конкретно эту ошибку. Для этого мы анализируем значение, возвращаемое GetLastError(). Если произошла ошибка с кодом ERR_NO_RESULT, то мы ничего не выводим в протокол.
Однако если произошла другая ошибка, то необходимо полностью отрапортовать о ней, как мы делали это раньше. Именно для этого мы сохраняем результат функции GetLastError() в промежуточной переменной и передаем его третьим параметром в функцию logError(). Дело в том, что встроенная функция GetLastError() автоматически обнуляет код последней ошибки после своего вызова. Если бы мы не передали код ошибки явно в logError(), то в протоколе была бы отражена ошибка с кодом 0 и описанием «no error».
Похожие действия необходимо совершать и при обработке других ошибок, например, реквотов. Основная идея заключается в том, чтобы обрабатывать только ошибки, требующие обработки, а остальные передавать в функцию logError(). Тогда мы всегда будем в курсе, если во время работы эксперта произошла непредвиденная ошибка. Проанализировав логи, мы сможем решить, требует ли данная ошибка отдельной обработки или же ее можно исключить, доработав код эксперта. Такой подход часто заметно упрощает жизнь и сокращает время, уходящее на борьбу с ошибками.
Диагностика логических ошибок
Логические ошибки в коде эксперта могут доставить много проблем. Отсутствие возможности пошаговой отладки экспертов делают борьбу с такими ошибками не очень приятным занятием. Основным средством для диагностики этого на данный момент является встроенная функция Print(). С ее помощью можно выполнять распечатку текущих значений важных переменных, а также протоколировать ход работы эксперта прямо в терминале во время тестирования. При отладке эксперта во время тестирования с визуализацией также может помочь встроенная функция Comment(), которая выводит сообщения на график. Как правило, убедившись, что эксперт работает не так, как было задумано, приходится добавлять временные вызовы функции Print() и протоколировать внутреннее состояние эксперта в предполагаемых местах возникновения ошибки.
Однако, для обнаружения сложных ошибочных ситуаций порой приходится добавлять десятки таких вызовов функции Print(), а после обнаружения и устранения проблемы их приходится удалять или комментировать, чтобы не загромождался код эксперта и не замедлялось его тестирование. Ситуация ухудшается, если в коде эксперта функция Print() уже используется для периодического протоколирования различных состояний. Тогда удаление временных вызовов Print() не удается выполнить путем простого поиска фразы ‘Print’ в коде эксперта. Приходится задумываться, чтобы не удалить еще и полезные вызовы этой функции.
Например, при протоколировании ошибок функций OrderSend(), OrderModify() и OrderClose() полезным бывает печатать в протокол текущее значение переменных Bid и Ask. Это несколько облегчает распознавание причин таких ошибок, как ERR_INVALID_STOPS и ERR_OFF_QUOTES.
Чтобы выделить такие диагностические выводы в протокол, я рекомендую использовать такую вспомогательную функцию:
void logInfo(string msg)
{
Print("INFO: " + msg);
}Это желательно сделать по нескольким причинам. Во-первых, теперь такие вызовы не будут попадаться при поиске ‘Print’ в коде эксперта, ведь искать мы будем logInfo. Во-вторых, у этой функции есть еще одна полезная особенность, о которой мы поговорим чуть позже.
Добавление и удаление временных диагностических вызовов функции Print() отнимает у нас драгоценное время. Поэтому я предлагаю рассмотреть еще один подход, который эффективен при обнаружении логических ошибок в коде и позволяет немного сэкономить наше время. Рассмотрим следующую несложную функцию:
void openLongTrade(double stopLoss)
{
int ticket = OrderSend(Symbol(), OP_BUY, 1.0, Ask, 5, stopLoss, 0);
if (ticket == -1) {
logError("openLongTrade", "could not open order");
}
}В данном случае, так как мы открываем длинную позицию, совершенно очевидно, что при нормальной работе эксперта значение параметра stopLoss никогда не будет больше или равно текущей цене Bid. То есть, при вызове функции openLongTrade() всегда выполняется условие stopLoss < Bid. Так как мы знаем об этом еще на этапе написания рассматриваемой функции, то мы сразу же можем этим воспользоваться следующим образом:
void openLongTrade( double stopLoss )
{
assert("openLongTrade", stopLoss < Bid, "stopLoss < Bid");
int ticket = OrderSend(Symbol(), OP_BUY, 1.0, Ask, 5, stopLoss, 0);
if (ticket == -1) {
logError("openLongTrade", "could not open order");
}
}То есть мы логируем наше утверждение в коде при помощи новой вспомогательной функции assert(). Сама функция выглядит довольно просто:
void assert(string functionName, bool assertion, string description = "")
{
if (!assertion) {
Print("ASSERT: in " + functionName + "() - " + description);
}
}Первым параметром функции является ее имя, в котором проверяется наше условие (по аналогии с функцией logError()). Вторым параметром передается результат проверки этого условия. И третьим параметром передается его описание. В результате, если ожидаемое условие не выполняется, в протокол будет выведена следующая информация:
название функции, в которой условие было нарушено;
описание нарушенного условия.
В качестве описания можно передавать, например, само условие, а можно выводить и более подробное описание, содержащее значения контролируемых переменных на момент проверки условия, если это поможет разобраться в причинах ошибки.
Конечно же, рассмотренный пример максимально упрощен. Но, надеюсь, основную идею отражает достаточно хорошо. В процессе наращивания функциональности эксперта мы отдаем себе отчет в том, как он должен работать и какие состояния и входные параметры функций допустимы, а какие нет. Фиксируя это в коде эксперта при помощи функции assert() мы получаем ценную информацию о месте, в котором нарушается логика работы эксперта. Более того, мы частично избавляем себя от необходимости добавлять и удалять временные вызовы функции Print(), так как функция assert() выдает диагностические сообщения в протокол только в момент обнаружения несоответствий в ожидаемых нами условиях.
Еще одним полезным приемом является использование этой функции перед каждой операцией деления. Дело в том, что иногда в результате той или иной логической ошибки иногда происходит деление на ноль. Работа эксперта в этом случае прекращается, а в протоколе появляется одна лишь строка с печальным диагнозом: ‘zero divide’. Узнать, в каком именно месте произошла эта ошибка, если операция деления используется в коде неоднократно, достаточно сложно. Вот здесь и поможет функция assert(). Вставляем соответствующие проверки перед каждой операцией деления:
assert("buildChannel", distance > 0, "distance > 0");
double slope = delta / distance;И теперь, в случае деления на ноль, достаточно будет лишь взглянуть в логи, чтобы узнать, в каком именно месте произошла ошибка.
Обработка состояний
Во время работы эксперта на вашем счете могут возникнуть некоторые ситуации, которые не являются ошибками – так называемые состояния эксперта. Такие состояния не являются ошибками, но все же их стоит логировать. В этом помогают специальные функции языка mql4.
Функция IsExpertEnabled() возвращает информацию о возможности запуска экспертов. Функция вернет true, если в клиентском терминале разрешен запуск экспертов, иначе возвращает false. В случае возврата false полезно будет известить об этом пользователя с просьбой включить соответствующую настройку. Пример:
void OnStart()
{
if (!IsExpertEnabled() {
//советникам не разрешено торговать
Alert("Attention! Please press the "Expert Advisors" button in MT4");
}
//рабочий алгоритм советника
return;
}
Если эксперт использует внешние библиотеки, пригодится функция IsLibrariesAllowed(). Она возвращает true, если эксперт может вызвать библиотечную функцию, иначе возвращает false.
Если библиотека в виде dll файла, пригодится функция IsDllsAllowed(). Также нелишним будет проверить, есть ли вообще возможность торговать при помощи экспертов с помощью функции IsTradeAllowed().
Если вы хотите узнать, является ли счет демонстрационным, или же реальным, можно использовать функцию IsDemo().
Все вышеперечисленные проверки стоит сделать в функции OnInit().
Конечно же, стоит проверять периодически связь с сервером. В этом поможет функция IsConnected().
Следующие три функции помогут определить, в каком режиме находится советник. Если IsOptimisation() возвращает true, проводится оптимизация, если IsTesting(), то тестирование, IsVisualMode() – тестирование в режиме визуализации. Под каждый из этих вариантов в советнике может быть предусмотрена своя логика. Например, для режима визуализации можно что-то выводить на график (и не выводить в других режимах ради экономии ресурсов). В режиме тестирования можно выводить отладочную информацию, в режиме оптимизации максимально облегчить код, чтобы сэкономить время.
И последняя функция – IsTradeContextBusy(). Она вернет true, если поток для выполнения торговых операций занят. Это бывает полезно при совершении экспертом торговых операций. Можно применить функцию Sleep для ожидания некоторого момента и новой попытки.
Еще одна полезная функция — UninitializeReason()
int deinit()
{
switch(UninitializeReason())
{
case REASON_CHARTCLOSE:
case REASON_REMOVE:
CleanUp();
break; // очистка и освобождение ресурсов.
case REASON_RECOMPILE:
case REASON_CHARTCHANGE:
case REASON_PARAMETERS:
case REASON_ACCOUNT:
StoreData();
break; // подготовка к рестарту.
}
//...
}Можно также логировать причину выхода советника.
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба