


15 февраля 2021 smart-lab.ru
Так вот о сантиментах на фондовой бирже.
Вот вам лайхак как быстро что то сделать (про качество мы ничего не говорим, просто как вообще начать эту тему). Ну раз так, то начнем с англоязычного сегмента, ибо там информации и готовых скриптов завались. Да, как известно в любой теме можно потонуть, если копать очень глубоко. Но мы же трейдеры нас в общем интересует не программирование, а извлечение профита с помощью программирования. Так что к черту NLP и давайте не будем морочить голову слишком погружаясь в теорию.
Какие пункты я вижу:
1.
Первая задача это достать данные для анализа. Сначала я подумал о твитах. Популярная тема, наверняка много готовых кодов по выкачке, поисковики наверно есть неплохие, готовых баз на все случаи жизни итп итд. И главное — мы ведь используем железного болвана там где человеческий мозг может утонуть в потоке информации, ну так вот ам и твиттер. Но начав копать, очень скоро обнаружилось что твиттер это такая большая пребольшая куча… эээ… мусора, а не какой то источник информации. Кстати забавно, когда я регился на твиттер, то в качестве рекомендуемых твиттеров мне предлагали исключительно твиттеры так скажем оппозиционные, если это можно так назвать. Та же история кстати в ютубе, я все больше и больше чувствую себя в каком то интернет концлагере, где тебе пихают строго определенные каналы, авторов, видение. Ну да ладно. Твиттер помойка, так откуда качнуть новости? Есть openblender, оттуда можно что то качнуть более качественное, ну там разворотики WallStreet, а вот тут выложены (не переходите по ссылке, там фигня!) базы данных новостей Reddit, да еще и ранжированное. Спасибо Kaggle! Первые новости от 08.08.08. Ну помните — Цхинвал, миротворцы, стремительное наступление грузин,… затем стремительно отступление, галстук. Понимает насколько не пригодные данные для анализа влияние сантиментов там собраны? Ну вот как эта новость влияла на рынок? Те кто торгует отлично понимают что для рынка такая информация ценности не представляет. Я еще глянул на notebooks по этой базе, понятно дело никто никаких успехов не достиг. И они еще удивляются. Вообще поражает насколько часто люди пытающиеся использовать ML слабо представляют что такое биржа, пытаясь из букв ж, о п, а, сложить слово «вечность».
Да, еще есть stocktweet, где так называемые «розничные трейдеры» в перерывах своего обогащения, делятся своим виденьем рынке. Тоже куча твитов, тоже сомнительная ценность
Если говорим о более серьезных материалах, это отчеты, которые публичные компании должны предоставлять, это всякие 10-K, 10-Q, 8-Q итд. На сайте SEC они выложены в свободном доступе и воспользовавшись Edgar + Python (или что то другое по своему желанию) мы спокойно все это можем скачать. Так как нас интересуют сантименты, то нам нужен какой то текстовый блок, где важные директора компании рассуждали о перспективах и о том насколько хороша их компания. Это в отчете 10-К раздел 'Item 7. managements discussion and analysis of financial condition and results of operation'. Осталось только его вытащить, по айтишному — распарсить. Проблема в том что задача не тривиальная, тем более с моим весьма начальным уровнем знаний в этой области. Не тривиальна она, потому что отчеты всех компаний оформлены по разному, где то есть гиперссылки, где то нет, где то пробел, где то 5, где то точка, где то ее нет, одним словом какие регулярные шаблоны не создавай, а всего не учтешь. GeneralMotors вообще сдает этот отчет по своим личным хотелкам, и только где то в конце дает оглавление как требует комиссия. Бардак одним словом и какой то универсальный скрипт который вытаскивал нужный мне раздел для все 500 компаний входящий в индекс SP500 у меня не получилось написать. Но я не сдаюсь, не не.
Ну допустим с горем пополам нашли мы 100 компаний чей 7 раздел мы можем вытащить.
2.
Дальше стоит задача получения какие то циферок характеризующих сантимент. Самый простой способ это использовать библиотеки тональностей Лофрана-Макдональда или Саифа Мохаммада. Техника проста — у вас есть како то csv файлик где собраны слова которые характеризуют те или иные эмоции, и вам нужно в тексте посчитать сколько раз встречалось слово характеризующее к примеру позитив, или удивление или еще чего то там (у Муххамеда 8 эмоций). Как говорится «всего делоф». Ни о каком ML тут понимаете речи вообще не идет. Тут чисто лексический анализ, довольно наивный. Вот например слово debt относится к negative и sadness, хотя ребенку ясно что важен контекст, может там речь о уменьшении debt. Поэтому нет ничего удивительного что полученные мною оценки из года в год и от компании к компании имели примерно одни те же циферки:
«На базе позитива в 30% намешаем 15% доверия, подсолим 15% негатива, поперчим печали 10%, каплю страха, и щепотку удивления» — блюдо готово. Думаю все дело в том что из года в год в этих отчетах встречаются все те же шаблонные слова, поэтому и результаты одинаковые. Я специально глянул на 2020 год, ну там Ковид, кризис, все дела. Ну и да, неуверенности добавилось, было условно 5%, стало 5,5%, или если измерять в словах было 200, стало 220.
Конечно можно по другому сделать, есть word2vec или finBERT, но тут нужны уже размеченные данные. И тут есть некий финт ушами. Все эти приблуды учатся на основе размеченных данных, ну так можно просто взять размеченные данные (размечали их типа крутые фундаменталисты) и глянуть дают ли они что то для извлечения прибыли, потому что все эти word2vec или finBERT просто заменяют собой аналитиков, и вся их продвинутость это достичь 100% сходства с тем как оценивает текст аналитик — хомосапиенс. А вы пробовали торговать по рекомендациям аналитиков, и как успехи?! Кстати можно по другому сделать — пометить отчеты на основе выросли акции в следующем году, упали или болтались в ноль. Кстати такого подхода не видел, это опять к вопросу что машингленингом на фондовых биржах занимаются не трейдеры-практики, а розовые пони и мечтатели — теоретики. И так мы плавно переходим к 3 пункту
3.
Надо попробовать связать полученные циферки с котировочками. 10-К выходят примерно в феврале-марте, так что можно глянуть на динамику после. И тут можно прикрутить какие то регрессии, но можно и проще — например взять 100 самых позитивных отчета и 100 самых негативных и глянуть выливался ли оптимизм/негатив директоров на динамику фишки. Ну или взять одну компанию и отследить по годам как менялись сантименты.
Итого:
Если кто то хочет научиться парсить, узнать что такое Edgar, XBRL, какой поток инфы бесплатно вы можете получить (хотя по идее за это берут денюжку), или вы какой то фундаменталист торгующий на американских биржах и вам нужно получить какие то циферки по деятельности фирмы, или кто то хочет начать изучать NLP, то вполне можно начать с сантиментов на финансовых рынках. Улучшения для своих торговых систем вы почти наверняка не получите, зато все остальное вполне так.
Делюсь результатами. Напомню что я создал базу американских фишек входящих в SP500, выкачал для них отчеты 10-К с 2010 года, из которых достал 7 пункт «managements discussion and analysis of financial condition and results of operation». По идее должен был получить около 5000 текстов, но в парсинге 7 пункта и заключалась самая большая заковыка. В общем на финишную прямую вырулилось только около 2000 отчетов.
Для каждого отчета я получил оценку сантиментов, по 10 эмоциям и по каждой из них, разбил свои 2000 отчетов на три ровных группы — с максимальными значениями, минимальными и средними. И для каждой из этой группы глянул на сколько изменилась цена акции через 250 торговых дней, после опубликования отчета.
Вот корреляционна матрица между эмоциями (+ длина отчета).
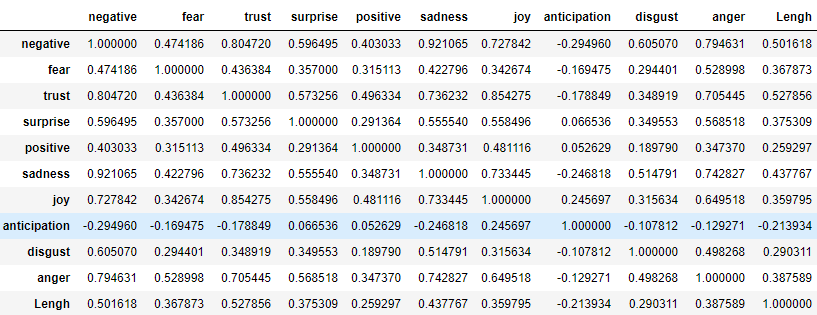
Как видим между позитивными и негативными эмоциями корреляция +0,4. Что может показаться странным, если предположить что они противостоят друг другу. Однако, тут видимо другая логика — есть отчеты где составившие их буквально сыпят эмоциями, и отчеты выдержанные в более строгом стиле. Даже предположу как это получается. Вот допустим много негативного в отчете, что обьекетивно — компания не на высоте, или рыночная ситуация аховая, понятно что по законам маркетинга такое никто не купит, поэтому в лучшем стиле манипулирования, негатив обильно разбавляется позитивными словечками и на выходе потенциальный инвестор получает некую сбалансированную баланду. Вот вам и положительная корреляция долей позитивных и негативных слов в тексте.
А вот тут мы видим доходность по каждой эмоции с разбивкой:

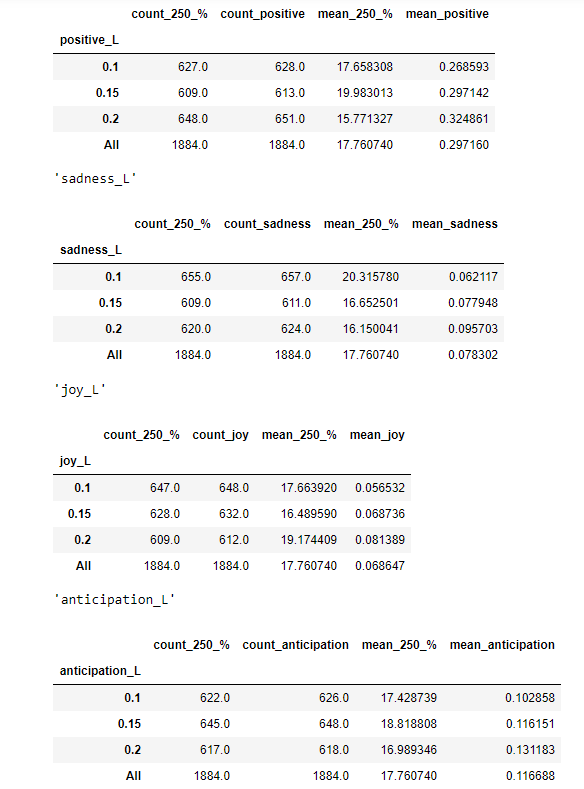

Как видим чем меньше доли negative, fear, sadness, disgust, anger, тем на больший процент вырастает компания за год. И наоборот чем больше доли trust joy тем доходность выше. А вот с positive четкой картинки не получилось. Нейтральные термины как surprise, antisipation имеют такое же нейтральное значение. В общем все логичненько.
Но самое четкое разделение с точки зрения доходности получилось если разбить размер текста на длинные, короткие и средние:
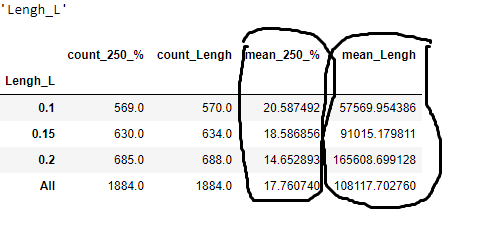
Как видим компании сподобившиеся на отчеты с 50К+- количеством символов, вырастают в среднем на 20%, а вот те что 165К+-, на 14%.
Можно заняться комбинаторикой на коленкой и взять какое то сочетание. Ну например размер текста и trust, первого поменьше, второго побольше и получить такое разбиение
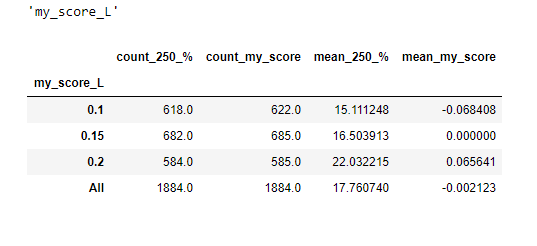
Тут разрывчик еще больше.
Для меня важно чтобы тенденция была стабильна по годам, берем trust и смотрим:
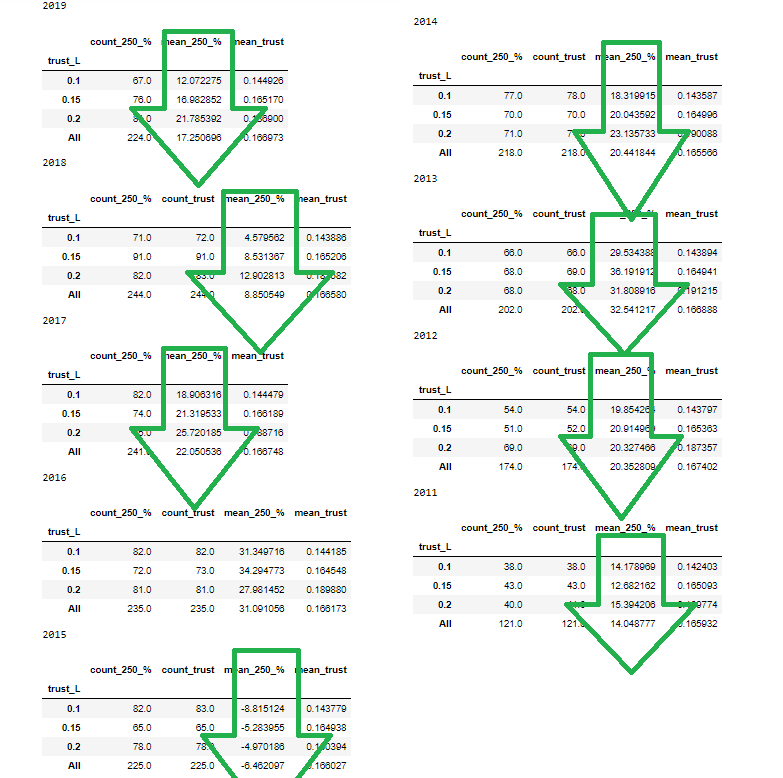
Видим что по годам довольно стабильненько, только в 2016 году из 9 других, зависимость была обратной, причем тенденция сильней выраженна именно в последние годы.
И по другим эмоциям прослеживается такая стабильность.
Как я писал самое четкое разделение получается когда мы берем не эмоцию, а размер отчета. Как это обьяснить?! Кто торгует может предположить что это связанно с тем что отчеты меньше у более мелких компаний, а мелкие компании более волатильны, а так как рынок в основном рос, то волатильные росли больше, «а вот наступит обвальный рынок и мелкие компании посыпят сильней». Логично, такое вполне может быть. Но вот взял я разбивку по длине текста для 2015 года, когда рынок падал и:
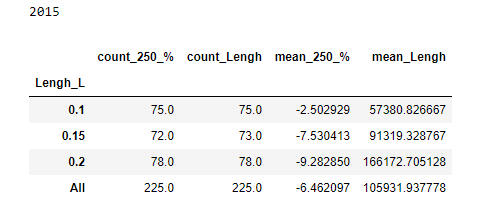
Как видим и тут лучше. Да и трудно предположить что в SP500 есть какие то мелкие компании, которые сдают мелкие отчеты только потому что в их бухгалтерии мало народа.
Представляет ли это какой то интерес для трейдинга?! Ну такое… Но приятно сознавать что при всей сырости подхода, в отчете удалось обнаружить лингвистические конструкции, которые могут давать дополнительную информацию о будущей динамике, которая стабильно прослеживалась на протяжении последних 10 лет. То есть как бы не пытались пудрить голову составители отчетов, но получается им не удается скрыть всю истину, какие то ушки все так же торчат. Так что, если кто то вдруг захочет купить на год в американские фишки на основе 7 радела отчета 10-К, то рекомендации следующие:
1. Ищите отчеты поменьше.
2. Ищите отчеты где доля эмоциональных словечек поменьше (позитивных, негативных — без разницы)
3. Где побольше доля словечек из разряда trust
4. Поменьше неприятных слов из разряда negative, fear, sadness итп.
И соответственно для шорта нужны отчеты многословные, эмоциональные, не уверенные.
Вот вам лайхак как быстро что то сделать (про качество мы ничего не говорим, просто как вообще начать эту тему). Ну раз так, то начнем с англоязычного сегмента, ибо там информации и готовых скриптов завались. Да, как известно в любой теме можно потонуть, если копать очень глубоко. Но мы же трейдеры нас в общем интересует не программирование, а извлечение профита с помощью программирования. Так что к черту NLP и давайте не будем морочить голову слишком погружаясь в теорию.
Какие пункты я вижу:
1.
Первая задача это достать данные для анализа. Сначала я подумал о твитах. Популярная тема, наверняка много готовых кодов по выкачке, поисковики наверно есть неплохие, готовых баз на все случаи жизни итп итд. И главное — мы ведь используем железного болвана там где человеческий мозг может утонуть в потоке информации, ну так вот ам и твиттер. Но начав копать, очень скоро обнаружилось что твиттер это такая большая пребольшая куча… эээ… мусора, а не какой то источник информации. Кстати забавно, когда я регился на твиттер, то в качестве рекомендуемых твиттеров мне предлагали исключительно твиттеры так скажем оппозиционные, если это можно так назвать. Та же история кстати в ютубе, я все больше и больше чувствую себя в каком то интернет концлагере, где тебе пихают строго определенные каналы, авторов, видение. Ну да ладно. Твиттер помойка, так откуда качнуть новости? Есть openblender, оттуда можно что то качнуть более качественное, ну там разворотики WallStreet, а вот тут выложены (не переходите по ссылке, там фигня!) базы данных новостей Reddit, да еще и ранжированное. Спасибо Kaggle! Первые новости от 08.08.08. Ну помните — Цхинвал, миротворцы, стремительное наступление грузин,… затем стремительно отступление, галстук. Понимает насколько не пригодные данные для анализа влияние сантиментов там собраны? Ну вот как эта новость влияла на рынок? Те кто торгует отлично понимают что для рынка такая информация ценности не представляет. Я еще глянул на notebooks по этой базе, понятно дело никто никаких успехов не достиг. И они еще удивляются. Вообще поражает насколько часто люди пытающиеся использовать ML слабо представляют что такое биржа, пытаясь из букв ж, о п, а, сложить слово «вечность».
Да, еще есть stocktweet, где так называемые «розничные трейдеры» в перерывах своего обогащения, делятся своим виденьем рынке. Тоже куча твитов, тоже сомнительная ценность
Если говорим о более серьезных материалах, это отчеты, которые публичные компании должны предоставлять, это всякие 10-K, 10-Q, 8-Q итд. На сайте SEC они выложены в свободном доступе и воспользовавшись Edgar + Python (или что то другое по своему желанию) мы спокойно все это можем скачать. Так как нас интересуют сантименты, то нам нужен какой то текстовый блок, где важные директора компании рассуждали о перспективах и о том насколько хороша их компания. Это в отчете 10-К раздел 'Item 7. managements discussion and analysis of financial condition and results of operation'. Осталось только его вытащить, по айтишному — распарсить. Проблема в том что задача не тривиальная, тем более с моим весьма начальным уровнем знаний в этой области. Не тривиальна она, потому что отчеты всех компаний оформлены по разному, где то есть гиперссылки, где то нет, где то пробел, где то 5, где то точка, где то ее нет, одним словом какие регулярные шаблоны не создавай, а всего не учтешь. GeneralMotors вообще сдает этот отчет по своим личным хотелкам, и только где то в конце дает оглавление как требует комиссия. Бардак одним словом и какой то универсальный скрипт который вытаскивал нужный мне раздел для все 500 компаний входящий в индекс SP500 у меня не получилось написать. Но я не сдаюсь, не не.
Ну допустим с горем пополам нашли мы 100 компаний чей 7 раздел мы можем вытащить.
2.
Дальше стоит задача получения какие то циферок характеризующих сантимент. Самый простой способ это использовать библиотеки тональностей Лофрана-Макдональда или Саифа Мохаммада. Техника проста — у вас есть како то csv файлик где собраны слова которые характеризуют те или иные эмоции, и вам нужно в тексте посчитать сколько раз встречалось слово характеризующее к примеру позитив, или удивление или еще чего то там (у Муххамеда 8 эмоций). Как говорится «всего делоф». Ни о каком ML тут понимаете речи вообще не идет. Тут чисто лексический анализ, довольно наивный. Вот например слово debt относится к negative и sadness, хотя ребенку ясно что важен контекст, может там речь о уменьшении debt. Поэтому нет ничего удивительного что полученные мною оценки из года в год и от компании к компании имели примерно одни те же циферки:
{'fear': 0.04884576781532285,
'anger': 0.03379056540649047,
'anticip': 0.0,
'trust': 0.164938106390097,
'surprise': 0.015724322515891603,
'positive': 0.29541652726664436,
'negative': 0.1448645031783205,
'sadness': 0.08698561391769823,
'disgust': 0.010036801605888258,
'joy': 0.07862161257945802,
'anticipation': 0.12077617932418869}
'anger': 0.03379056540649047,
'anticip': 0.0,
'trust': 0.164938106390097,
'surprise': 0.015724322515891603,
'positive': 0.29541652726664436,
'negative': 0.1448645031783205,
'sadness': 0.08698561391769823,
'disgust': 0.010036801605888258,
'joy': 0.07862161257945802,
'anticipation': 0.12077617932418869}
«На базе позитива в 30% намешаем 15% доверия, подсолим 15% негатива, поперчим печали 10%, каплю страха, и щепотку удивления» — блюдо готово. Думаю все дело в том что из года в год в этих отчетах встречаются все те же шаблонные слова, поэтому и результаты одинаковые. Я специально глянул на 2020 год, ну там Ковид, кризис, все дела. Ну и да, неуверенности добавилось, было условно 5%, стало 5,5%, или если измерять в словах было 200, стало 220.
Конечно можно по другому сделать, есть word2vec или finBERT, но тут нужны уже размеченные данные. И тут есть некий финт ушами. Все эти приблуды учатся на основе размеченных данных, ну так можно просто взять размеченные данные (размечали их типа крутые фундаменталисты) и глянуть дают ли они что то для извлечения прибыли, потому что все эти word2vec или finBERT просто заменяют собой аналитиков, и вся их продвинутость это достичь 100% сходства с тем как оценивает текст аналитик — хомосапиенс. А вы пробовали торговать по рекомендациям аналитиков, и как успехи?! Кстати можно по другому сделать — пометить отчеты на основе выросли акции в следующем году, упали или болтались в ноль. Кстати такого подхода не видел, это опять к вопросу что машингленингом на фондовых биржах занимаются не трейдеры-практики, а розовые пони и мечтатели — теоретики. И так мы плавно переходим к 3 пункту
3.
Надо попробовать связать полученные циферки с котировочками. 10-К выходят примерно в феврале-марте, так что можно глянуть на динамику после. И тут можно прикрутить какие то регрессии, но можно и проще — например взять 100 самых позитивных отчета и 100 самых негативных и глянуть выливался ли оптимизм/негатив директоров на динамику фишки. Ну или взять одну компанию и отследить по годам как менялись сантименты.
Итого:
Если кто то хочет научиться парсить, узнать что такое Edgar, XBRL, какой поток инфы бесплатно вы можете получить (хотя по идее за это берут денюжку), или вы какой то фундаменталист торгующий на американских биржах и вам нужно получить какие то циферки по деятельности фирмы, или кто то хочет начать изучать NLP, то вполне можно начать с сантиментов на финансовых рынках. Улучшения для своих торговых систем вы почти наверняка не получите, зато все остальное вполне так.
Делюсь результатами. Напомню что я создал базу американских фишек входящих в SP500, выкачал для них отчеты 10-К с 2010 года, из которых достал 7 пункт «managements discussion and analysis of financial condition and results of operation». По идее должен был получить около 5000 текстов, но в парсинге 7 пункта и заключалась самая большая заковыка. В общем на финишную прямую вырулилось только около 2000 отчетов.
Для каждого отчета я получил оценку сантиментов, по 10 эмоциям и по каждой из них, разбил свои 2000 отчетов на три ровных группы — с максимальными значениями, минимальными и средними. И для каждой из этой группы глянул на сколько изменилась цена акции через 250 торговых дней, после опубликования отчета.
Вот корреляционна матрица между эмоциями (+ длина отчета).
Как видим между позитивными и негативными эмоциями корреляция +0,4. Что может показаться странным, если предположить что они противостоят друг другу. Однако, тут видимо другая логика — есть отчеты где составившие их буквально сыпят эмоциями, и отчеты выдержанные в более строгом стиле. Даже предположу как это получается. Вот допустим много негативного в отчете, что обьекетивно — компания не на высоте, или рыночная ситуация аховая, понятно что по законам маркетинга такое никто не купит, поэтому в лучшем стиле манипулирования, негатив обильно разбавляется позитивными словечками и на выходе потенциальный инвестор получает некую сбалансированную баланду. Вот вам и положительная корреляция долей позитивных и негативных слов в тексте.
А вот тут мы видим доходность по каждой эмоции с разбивкой:
Как видим чем меньше доли negative, fear, sadness, disgust, anger, тем на больший процент вырастает компания за год. И наоборот чем больше доли trust joy тем доходность выше. А вот с positive четкой картинки не получилось. Нейтральные термины как surprise, antisipation имеют такое же нейтральное значение. В общем все логичненько.
Но самое четкое разделение с точки зрения доходности получилось если разбить размер текста на длинные, короткие и средние:
Как видим компании сподобившиеся на отчеты с 50К+- количеством символов, вырастают в среднем на 20%, а вот те что 165К+-, на 14%.
Можно заняться комбинаторикой на коленкой и взять какое то сочетание. Ну например размер текста и trust, первого поменьше, второго побольше и получить такое разбиение
Тут разрывчик еще больше.
Для меня важно чтобы тенденция была стабильна по годам, берем trust и смотрим:
Видим что по годам довольно стабильненько, только в 2016 году из 9 других, зависимость была обратной, причем тенденция сильней выраженна именно в последние годы.
И по другим эмоциям прослеживается такая стабильность.
Как я писал самое четкое разделение получается когда мы берем не эмоцию, а размер отчета. Как это обьяснить?! Кто торгует может предположить что это связанно с тем что отчеты меньше у более мелких компаний, а мелкие компании более волатильны, а так как рынок в основном рос, то волатильные росли больше, «а вот наступит обвальный рынок и мелкие компании посыпят сильней». Логично, такое вполне может быть. Но вот взял я разбивку по длине текста для 2015 года, когда рынок падал и:
Как видим и тут лучше. Да и трудно предположить что в SP500 есть какие то мелкие компании, которые сдают мелкие отчеты только потому что в их бухгалтерии мало народа.
Представляет ли это какой то интерес для трейдинга?! Ну такое… Но приятно сознавать что при всей сырости подхода, в отчете удалось обнаружить лингвистические конструкции, которые могут давать дополнительную информацию о будущей динамике, которая стабильно прослеживалась на протяжении последних 10 лет. То есть как бы не пытались пудрить голову составители отчетов, но получается им не удается скрыть всю истину, какие то ушки все так же торчат. Так что, если кто то вдруг захочет купить на год в американские фишки на основе 7 радела отчета 10-К, то рекомендации следующие:
1. Ищите отчеты поменьше.
2. Ищите отчеты где доля эмоциональных словечек поменьше (позитивных, негативных — без разницы)
3. Где побольше доля словечек из разряда trust
4. Поменьше неприятных слов из разряда negative, fear, sadness итп.
И соответственно для шорта нужны отчеты многословные, эмоциональные, не уверенные.
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба