


14 февраля 2020 smart-lab.ru
R — один из популярных языков программирования, используемых алготрейдерами для поиска рыночных закономерностей и разработки торговых стратегий. В настоящее время для него доступно более 15000 пакетов, реализующих самые разнообразные методы статистики и машинного обучения.
Эта статья предназначена для тех, кто уже знаком с языком R, но хочет научиться выжимать из него больше производительности. К сожалению, скорость работы R может быть очень низкой, если вы не знаете некоторые нюансы. В основе статьи лежит мой опыт использования этого языка.
Начинающие же могут глянуть инфу в википедии, скачать дистрибутив и удобную среду для разработки.
1. Измеряем время, требуемое для выполнения некоторого куска кода
Начинать надо с самого простого :)

2. Следим за деятельностью Garbage Collector'а
Управление памятью в R осуществляется автоматически. Чрезмерно частое срабатывание сборки мусора может быть свидетельством того, что код плодит множество промежуточных объектов, что может значительно ухудшать производительность.
Чтобы включить вывод информации при срабатывании GC, нужно выполнить команду gcinfo(verbose=TRUE).

Расшифровку формата см. в справке: ?base::gc
3. Как найти части кода с наихудшей производительностью
В языке R есть встроенный профилировщик: ?utils::Rprof, ?utils::summaryRprof.
Что про него можно сказать? Он просто работает, хотя иногда бывает непросто разобраться в том, откуда взялась какая-нибудь анонимная функция.
Создатели IDE RStudio разработали пакет profvis, который упрощает задачу анализа результатов Rprof:
https://rstudio.github.io/profvis/
https://support.rstudio.com/hc/en-us/articles/218221837-Profiling-with-RStudio
4. Ускоряем чтение CSV файлов
Для примера возьмём минутные данные, скачанные с сайта Финама, а именно, данные по обыкновенным акциям Сбербанка.
Чтение этого файла размером 105 мегабайт с SSD-диска Samsung 850 Pro занимает 7.8 секунд. Тут явно что-то не так!

Посмотрим внимательно на файл...

… и избавимся от лишних преобразований в процессе чтения файла:

Чуть лучше, но не идеально!
5. Экономим место на дисках и ускоряем чтение маркетдаты из сетевых папок и других медленных хранилищ
При командной работе над стратегиями зачастую нет смысла дублировать данные на каждом из используемых компьютеров. Кроме того, некоторые типы данных (full order log) сами по себе могут занимать немало места, поэтому иногда имеет смысл немного оптимизировать их размер.
Данные в формате CSV зачастую очень хорошо сжимаются gzip и xz. В частности, файл из предыдущего примера можно сжать со 105 МБ до 11 МБ.
R может читать данные из различных источников и разжимать их на лету:

Более подробно — см. справку по команде ?base::connections
6. Пересохраняем данные в бинарном формате со сжатием
Если данные изменяются редко, а читать их нужно часто — есть смысл сохранить данные в бинарном формате RData вместо текстового CSV. Формат поддерживает сжатие (gzip, bzip2, xz) и имеет весьма неплохую совместимость между различными версиями R.

Экономия времени по сравнению с CSV — почти 75%. Размер сжатого файла составляет 8.6 МБ, что на 92% лучше оригинального CSV, и на 23% лучше, чем CSV + сжатие при помощи XZ.
7. Ускоряем XZ сжатие при сохранении данных в формате RData
Начиная с версии 5.2 утилита xz поддерживает распараллеливание при сжатии файлов. Соответственно, можно сохранить данные в формате RData без сжатия, сжать полученный файл с распараллеливанием и сменить расширение файла на ".RData". R сумеет прочитать полученный файл.

Для обеспечения надежности и кросс-платформенности кода рекомендую также добавить:
1. Вызов команды "xz --robot --version" с проверкой успешности выполнения (установлен ли xz?);
2. Разбор атрибута "XZ_VERSION" (поддерживает ли установленная версия сжатие? описание вывода с ключом --robot можно посмотреть в man xz);
3. Оценку потребления памяти для выбранного кол-ва потоков и степени сжатия (man xz? man xz!).
8. Как скормить всю свободную память линейной регрессии
Воспользуемся ранее считанными данными, чтобы построить линейную регрессию (иллюстративный пример, не ищите в модели глубокого смысла):

И сравним размер исходного набора данных с размером модели:

К встроенной функции расчёта линейной регрессии вопросов нет — она считает всё и сразу. Но если вы попробуете использовать её в бэктесте парного трейдинга — я вам не завидую.
Выход? В некоторых случаях лучше вручную сосчитать то, что вам реально нужно. Например, коэффициенты и остатки линейной регрессии.

Таким образом, вместо 320 МБ памяти нам потребовалось всего 11 МБ.
9. Заглядываем внутрь объекта...
Иногда возникает необходимость заглянуть внутрь объекта, чтобы выявить причины чрезмерного расхода памяти, либо чтобы получить доступ к какому-то атрибуту, до которого иначе не добраться. Для этого можно воспользоваться функцией str(). Посмотрим на примере линейной регрессии, сосчитанной в предыдущем пункте:

10.… и находим вовсе не драгоценные минералы :(
Обратите внимание на значения типа "environment" на предыдущей картинке. Это ссылки, что может быть очень важно в некоторых случаях.
Дело в том, что при сериализации объектов (вызов функции serialize(); сохранение в файл Rdata функцией save(); передача на кластер, созданный при помощи пакета parallel), содержимое таких ссылок захватывается в большинстве случаев. Последствия? Гигантские RData файлы, излишние затраты времени на передачу объектов на кластер, нехватка памяти и т.д.
Разумеется, если вы не сохраняете объект с множеством ссылок на диск и не передаёте его на кластер — проблем со ссылками на environment'ы не будет. Всё-таки R написан весьма умными людьми, и не будет лишний раз копировать данные, когда это не нужно.

Вот так одна маленькая ссылка на environment может превратить объект размером 168 байт в объект размером 123 мегабайта (при сериализации). А ещё этого не видно при помощи функции object.size().
Если вы используете функцию new.env() или возвращаете функцию из функции — можно очень легко захватить ссылку на environment, содержащую какую-нибудь большую переменную. Иногда есть смысл убрать лишние ссылки, присваивая им значение, возвращаемое emptyenv().
11. Об environment'ах, list'ах и присваиваниях
Объекты большинства типов в R являются неизменяемыми. Что это означает на практике? Если вы присваиваете значение элементу большого объекта — происходит создание измененной копии объекта.
Есть несколько исключений из правила неизменяемости объектов, одним из которых являются переменные типа environment.
Допустим, мы накапливаем результаты расчётов и складываем их переменную:

В случае с переменной типа list будет происходить копирование набора ссылок на элементы списка, а в случае с переменной типа environment этого происходить не будет. Если списки, с которыми вы имеете дело, содержат большое количество элементов — постоянное копирование будет бить по производительности.
12. Циклы, *apply() и здравый смысл
R показывает невысокую производительность, если в коде содержится большое количество циклов и операторов ветвления. Это нужно принять как данность и стараться писать код в функциональном стиле, а также максимально использовать векторизацию вычислений.
Плохо:

Хорошо:

«Мы научим мир тормозить»:

Во многих случаях циклы можно заменить на вызов функций:
1. lapply(): обрабатывает vector или list, возвращает list (см. часть 10: накапливать результаты в list самостоятельно — медленно);
2. sapply(): обрабатывает vector или list, и может упростить результат до вектора или матрицы;
3. mapply(): аналог sapply(), пригодный для функций нескольких переменных;
4. eapply(): обрабатывает environment, возвращает list (см. часть 10);
5. Vectorize(): векторизует функцию по выбранному аргументу;
6. Map(), Reduce(), …: см. map, reduce.

13. Вновь о линейных регрессиях
Вернёмся к коду из части 8:

Посмотрите внимательно на расчёт коэффициентов регрессии. Два транспонирования, три умножения, одно обращение.
К счастью, в R есть функции, быстро вычисляющие t(x) %*% y и x %*% t(y): crossprod() и tcrossprod(). С их помощью код можно переписать следующим образом:

Также можно сосчитать псевдоинверсию матрицы regr.x через SVD-разложение:

В некоторых случаях это может дать огромный прирост производительности (в разы), если ваша экземпляр R собран с использованием быстрых библиотек численной линейной алгебры. Ищите способы свернуть операции в вызовы внутренних функций R, которые практически напрямую транслируются в обращения к BLAS и LAPACK.
14. Быстрые сборки R
Компания Revolution Analytics, впоследствии купленная Microsoft, проделала огромную работу по оптимизации R. Их продукт Revolution R теперь известен как Microsoft R Open.
Одним из преимуществ этой сборки является использование библиотеки Intel Math Kernel Library, которое значительно ускоряет матричные операции (заметно при работе с большими матрицами).
Где скачать: https://mran.microsoft.com/download
Инструкция по установке: https://mran.microsoft.com/documents/rro/installation
Если всё сделано правильно, после установки вы увидите нечто подобное:

Бенчмарки: https://mran.microsoft.com/documents/rro/multithread

15. JIT-компилятор
Во времена версии 2.13 интерпретатора R один из его ведущих разработчиков создал пакет compiler, который значительно улучшил производительность R при исполнении кода с циклами. Эффект от его использования порой настолько ощутим, что в настоящее время пакет включен в стандартную поставку R, а для всех стандартных функций байткод генерируется на этапе сборки соответствующих пакетов.

Если вы запускаете скрипты с большим кол-вом циклов и ветвлений — попробуйте включить JIT-компиляцию командами:

Подробнее о функциях пакета можно посмотреть в справке: ?compiler::cmpfun.
Функция, которая подверглась компиляции, приобретает дополнительный атрибут «bytecode»:

Если вы оформляете свой код в виде пакетов — включить генерацию байткода при сборке пакета можно добавив строчку "ByteCompile: yes" в файл "DESCRIPTION".
16. Невыполненные обещания
Интерпретатор языка R предпочитает не выполнять обещания, если это не имеет последствий. О чём я вообще? Да об объектах типа "promise".
Изобразим подобие логгера:
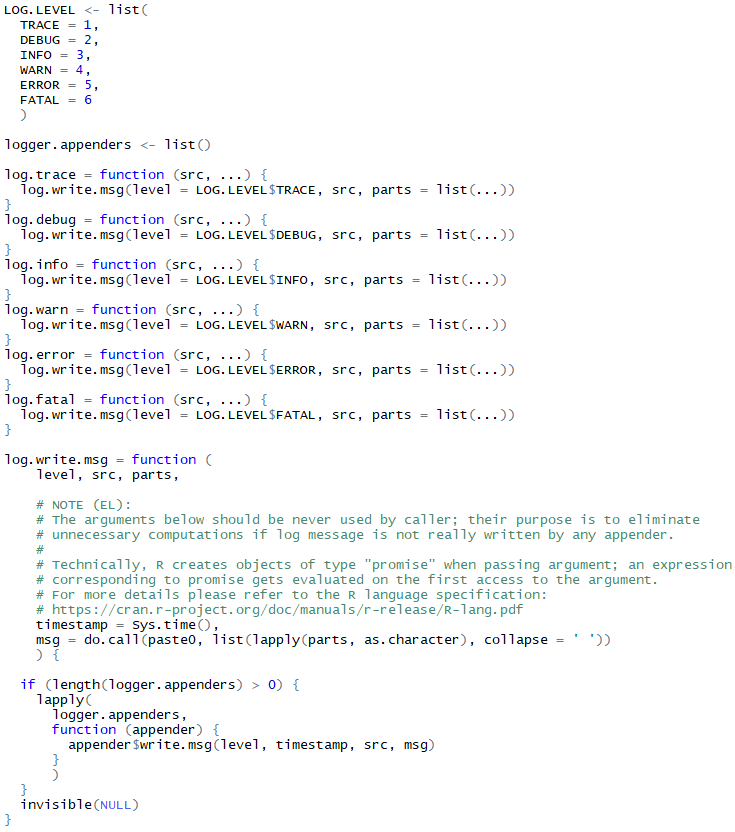
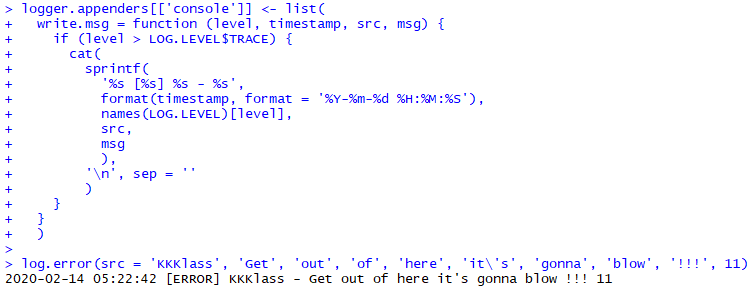
Логгер этот не имеет ни малейшего понятия о том, будет ли реально записано сообщение, или же можно даже не надрываться, склеивая его кусочки. Поэтому я прибегнул к хитрости, выполнив склеивание кусочков сообщения в значении по умолчанию одного из аргументов функции log.write.msg(). И если реального обращения к этому аргументу не произойдет — значение по умолчанию вычислено не будет.
Можете мне поверить: если ваш код пишет многие миллионы записей уровня TRACE в лог, а в продакшене вы используете уровень сообщений DEBUG, под который попадает пара тысяч строчек лога — экономия на склеивании кусочков сообщений составит десятки минут, если не часы.
17. Объектно-ориентированное программирование в R
Язык R содержит несколько встроенных моделей для ООП, и ещё большее их количество реализовано в различных пакетах.
Итак:
1-3: S3, S4, reference classes;
4: Эмуляция объектов на основе замыканий (closures);
5: R.oo;
6: R6.
(это только то, что с ходу вспомнилось и нашлось)
На мой взгляд, ни одна из встроенных моделей (1-3) не отличается ни хорошим быстродействием, ни удобством.
Если вам не требуется наследование — можно реализовывать объекты на основе замыканий:

В остальных случаях — мой выбор за R6. Быстрый, удобный, с минимальными накладными расходами. Возможностей поменьше, чем в C++, но это даже хорошо! :)

Но есть и нюансы, обусловленные тем, что было изложено в части 10.
1. Желательно отключать клонирование объектов. Оно реально редко нужно, но увеличивает memory footprint мелких объектов в 5 раз.
2. Нужно аккуратно подходить к выбору environment'а в котором создаются генераторы объектов (результат деятельности функции R6Class; экземпляры класса создаются путём вызова метода $new() у генератора). Идеальный случай — когда генераторы размещены внутри пакета, тогда они почти наверняка ничего лишнего не захватят из global environment.
18. Распараллеливание вычислений между несколькими экземплярами интерпретатора
Ядро интерпретатора R (core и унаследованные от него версии, такие как Microsoft R Open) является однопоточным, поэтому для простейшего распараллеливания требуется запуск нескольких его экземпляров, а также механизм для взаимодействия между процессами.
Задачу написания удобного механизма для параллельных вычислений в R пыталось решать немало людей (поищите слово «parallel» в списке пакетов), однако наиболее качественное (на мой взгляд) решение получилось у Revolution Analytics. Их пакет foreach способен работать с несколькими бэкендами:
1. предоставляемым стандартным пакетом parallel;
2. предоставляемым пакетом doSNOW (он был взят за основу при создании пакета parallel);
3. предоставляемым пакетом doParallel;
4. предоставляемым пакетом doMC.
В целом сочетание parallel+foreach можно использовать из коробки и получать ускорение вычислений.
parallel позволяет создавать кластер двумя способами — fork'ом процессов (?parallel::makeForkCluster) или запуском экземпляров Rscript (?parallel::makePSOCKcluster). Плюсы и минусы этих вариантов:
1. Fork cluster:
+ Мгновенный запуск;
+ Все данные с мастер-ноды сразу после запуска присутствуют на всех нодах кластера;
+ Не нужно тратить время на загрузку пакетов на нодах кластера;
— При срабатывании GC на нодах кластера существенно растет расход памяти в системе; если память закончится — кластер упадёт (или мастер-нода, как повезёт);
— Не работает под Windows;
2. PSOCK cluster:
+ Работает на всех ОС;
+ Максимальная гибкость в раздаче данных на ноды кластера и в подгрузке пакетов;
— Расходуется время на запуск кластера, раздачу данных и подгрузку пакетов;
— «Из коробки» нестабильно запускает кластер более чем из 16 нод; требуется специальная обёртка вокруг Rscript, которая будет ожидать появления слушателя у порта, прежде чем дать мастер-ноде к нему коннектиться;
— Требуется доработка напильником для распараллеливания раздачи данных (скинуть данные во временный файл и прочитать его параллельно на всех нодах).
И о других способах.
1. doMPI + Rmpi: из коробки не удалось заставить работать достаточно быстро.
2. SparkR: сложен в установке, модель вычислений подойдет не для всякой задачи.
19. Распараллеливание вычислений внутри интерпретатора
Вот как выглядел вызов кода на C++ из R лет 10 назад. Залезаешь в чёрную-чёрную консоль, колдуешь "R CMD SHLIB bla-bla-bla", делаешь dyn.load() полученного бинарника, и пытаешься чего-нибудь повызывать функциями .C(), .Call(), .External(). А чтобы взаимодействовать с R'овскими объектами — приходилось лезть в исходники интерпретатора и читать R Internals.
Теперь это всё практически не нужно, потому что появился пакет Rcpp. Для работы этого пакета потребуется установить Rtools — тулчейн, используемый для сборки интерпретатора R.
Для распараллеливания кода удобно использовать пакет RcppParallel, в основе которого лежит библиотека Intel Thread Building Blocks. К сожалению, к ядру интерпретатора R нельзя обращаться из разных потоков, поэтому в определенных случаях вам потребуется самостоятельно реализовывать некоторые функции или подключать сторонние библиотеки. Для работы с векторами и матрицами я рекомендую использовать RcppArmadillo (документация к Armadillo); в некоторых случаях сгодится RcppEigen.
Разумеется, скорость разработки на C++ получается ниже, чем на R, однако в вычислительных задачах сочетание библиотек Rcpp+RcppParallel+RcppArmadillo позволяет выжать из железа практически всё.
20. Переупаковка объектов
Этот вопрос я рассмотрю на примере класса timeSeries из пакета timeSeries.
Допустим, у нас есть экземпляр такого класса, в столбцах которого содержатся цены некоторых инструментов, и мы хотим к каждому столбцу применить 100 раз экспоненциальную среднюю скользящую. Записать это можно примерно таким образом:

Если вы обратили внимание на часть 3, то рано или поздно вы обнаружите, что немало времени уходит на создание объектов типа timeSeries. Но ведь объект создается один раз, в самом начале — спросите вы. А вот и нет. Заглянем в вариант функции apply(), который будет вызываться для класса timeSeries:
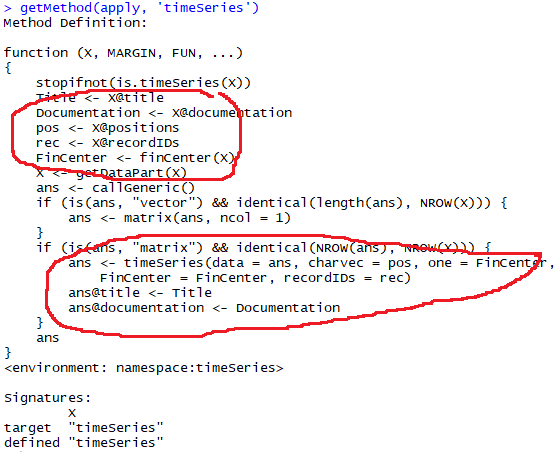
Видим, что объект разбирается на атрибуты, преобразуется в матрицу (?timeSeries::getDataPart), обрабатывается, а затем преобразуется обратно в объект класса timeSeries. Если избавиться от лишних преобразований типов — код будет работать быстрее:

Пока что на этом всё. Если я вспомню ещё какие-то интересные детали, а также увижу интерес к теме — будет продолжение.
Эта статья предназначена для тех, кто уже знаком с языком R, но хочет научиться выжимать из него больше производительности. К сожалению, скорость работы R может быть очень низкой, если вы не знаете некоторые нюансы. В основе статьи лежит мой опыт использования этого языка.
Начинающие же могут глянуть инфу в википедии, скачать дистрибутив и удобную среду для разработки.
1. Измеряем время, требуемое для выполнения некоторого куска кода
Начинать надо с самого простого :)
2. Следим за деятельностью Garbage Collector'а
Управление памятью в R осуществляется автоматически. Чрезмерно частое срабатывание сборки мусора может быть свидетельством того, что код плодит множество промежуточных объектов, что может значительно ухудшать производительность.
Чтобы включить вывод информации при срабатывании GC, нужно выполнить команду gcinfo(verbose=TRUE).
Расшифровку формата см. в справке: ?base::gc
3. Как найти части кода с наихудшей производительностью
В языке R есть встроенный профилировщик: ?utils::Rprof, ?utils::summaryRprof.
Что про него можно сказать? Он просто работает, хотя иногда бывает непросто разобраться в том, откуда взялась какая-нибудь анонимная функция.
Создатели IDE RStudio разработали пакет profvis, который упрощает задачу анализа результатов Rprof:
https://rstudio.github.io/profvis/
https://support.rstudio.com/hc/en-us/articles/218221837-Profiling-with-RStudio
4. Ускоряем чтение CSV файлов
Для примера возьмём минутные данные, скачанные с сайта Финама, а именно, данные по обыкновенным акциям Сбербанка.
Чтение этого файла размером 105 мегабайт с SSD-диска Samsung 850 Pro занимает 7.8 секунд. Тут явно что-то не так!
Посмотрим внимательно на файл...
… и избавимся от лишних преобразований в процессе чтения файла:
Чуть лучше, но не идеально!
5. Экономим место на дисках и ускоряем чтение маркетдаты из сетевых папок и других медленных хранилищ
При командной работе над стратегиями зачастую нет смысла дублировать данные на каждом из используемых компьютеров. Кроме того, некоторые типы данных (full order log) сами по себе могут занимать немало места, поэтому иногда имеет смысл немного оптимизировать их размер.
Данные в формате CSV зачастую очень хорошо сжимаются gzip и xz. В частности, файл из предыдущего примера можно сжать со 105 МБ до 11 МБ.
R может читать данные из различных источников и разжимать их на лету:
Более подробно — см. справку по команде ?base::connections
6. Пересохраняем данные в бинарном формате со сжатием
Если данные изменяются редко, а читать их нужно часто — есть смысл сохранить данные в бинарном формате RData вместо текстового CSV. Формат поддерживает сжатие (gzip, bzip2, xz) и имеет весьма неплохую совместимость между различными версиями R.
Экономия времени по сравнению с CSV — почти 75%. Размер сжатого файла составляет 8.6 МБ, что на 92% лучше оригинального CSV, и на 23% лучше, чем CSV + сжатие при помощи XZ.
7. Ускоряем XZ сжатие при сохранении данных в формате RData
Начиная с версии 5.2 утилита xz поддерживает распараллеливание при сжатии файлов. Соответственно, можно сохранить данные в формате RData без сжатия, сжать полученный файл с распараллеливанием и сменить расширение файла на ".RData". R сумеет прочитать полученный файл.
Для обеспечения надежности и кросс-платформенности кода рекомендую также добавить:
1. Вызов команды "xz --robot --version" с проверкой успешности выполнения (установлен ли xz?);
2. Разбор атрибута "XZ_VERSION" (поддерживает ли установленная версия сжатие? описание вывода с ключом --robot можно посмотреть в man xz);
3. Оценку потребления памяти для выбранного кол-ва потоков и степени сжатия (man xz? man xz!).
8. Как скормить всю свободную память линейной регрессии
Воспользуемся ранее считанными данными, чтобы построить линейную регрессию (иллюстративный пример, не ищите в модели глубокого смысла):
И сравним размер исходного набора данных с размером модели:
К встроенной функции расчёта линейной регрессии вопросов нет — она считает всё и сразу. Но если вы попробуете использовать её в бэктесте парного трейдинга — я вам не завидую.
Выход? В некоторых случаях лучше вручную сосчитать то, что вам реально нужно. Например, коэффициенты и остатки линейной регрессии.
Таким образом, вместо 320 МБ памяти нам потребовалось всего 11 МБ.
9. Заглядываем внутрь объекта...
Иногда возникает необходимость заглянуть внутрь объекта, чтобы выявить причины чрезмерного расхода памяти, либо чтобы получить доступ к какому-то атрибуту, до которого иначе не добраться. Для этого можно воспользоваться функцией str(). Посмотрим на примере линейной регрессии, сосчитанной в предыдущем пункте:
10.… и находим вовсе не драгоценные минералы :(
Обратите внимание на значения типа "environment" на предыдущей картинке. Это ссылки, что может быть очень важно в некоторых случаях.
Дело в том, что при сериализации объектов (вызов функции serialize(); сохранение в файл Rdata функцией save(); передача на кластер, созданный при помощи пакета parallel), содержимое таких ссылок захватывается в большинстве случаев. Последствия? Гигантские RData файлы, излишние затраты времени на передачу объектов на кластер, нехватка памяти и т.д.
Разумеется, если вы не сохраняете объект с множеством ссылок на диск и не передаёте его на кластер — проблем со ссылками на environment'ы не будет. Всё-таки R написан весьма умными людьми, и не будет лишний раз копировать данные, когда это не нужно.
Вот так одна маленькая ссылка на environment может превратить объект размером 168 байт в объект размером 123 мегабайта (при сериализации). А ещё этого не видно при помощи функции object.size().
Если вы используете функцию new.env() или возвращаете функцию из функции — можно очень легко захватить ссылку на environment, содержащую какую-нибудь большую переменную. Иногда есть смысл убрать лишние ссылки, присваивая им значение, возвращаемое emptyenv().
11. Об environment'ах, list'ах и присваиваниях
Объекты большинства типов в R являются неизменяемыми. Что это означает на практике? Если вы присваиваете значение элементу большого объекта — происходит создание измененной копии объекта.
Есть несколько исключений из правила неизменяемости объектов, одним из которых являются переменные типа environment.
Допустим, мы накапливаем результаты расчётов и складываем их переменную:
В случае с переменной типа list будет происходить копирование набора ссылок на элементы списка, а в случае с переменной типа environment этого происходить не будет. Если списки, с которыми вы имеете дело, содержат большое количество элементов — постоянное копирование будет бить по производительности.
12. Циклы, *apply() и здравый смысл
R показывает невысокую производительность, если в коде содержится большое количество циклов и операторов ветвления. Это нужно принять как данность и стараться писать код в функциональном стиле, а также максимально использовать векторизацию вычислений.
Плохо:
Хорошо:
«Мы научим мир тормозить»:
Во многих случаях циклы можно заменить на вызов функций:
1. lapply(): обрабатывает vector или list, возвращает list (см. часть 10: накапливать результаты в list самостоятельно — медленно);
2. sapply(): обрабатывает vector или list, и может упростить результат до вектора или матрицы;
3. mapply(): аналог sapply(), пригодный для функций нескольких переменных;
4. eapply(): обрабатывает environment, возвращает list (см. часть 10);
5. Vectorize(): векторизует функцию по выбранному аргументу;
6. Map(), Reduce(), …: см. map, reduce.
13. Вновь о линейных регрессиях
Вернёмся к коду из части 8:
Посмотрите внимательно на расчёт коэффициентов регрессии. Два транспонирования, три умножения, одно обращение.
К счастью, в R есть функции, быстро вычисляющие t(x) %*% y и x %*% t(y): crossprod() и tcrossprod(). С их помощью код можно переписать следующим образом:
Также можно сосчитать псевдоинверсию матрицы regr.x через SVD-разложение:
В некоторых случаях это может дать огромный прирост производительности (в разы), если ваша экземпляр R собран с использованием быстрых библиотек численной линейной алгебры. Ищите способы свернуть операции в вызовы внутренних функций R, которые практически напрямую транслируются в обращения к BLAS и LAPACK.
14. Быстрые сборки R
Компания Revolution Analytics, впоследствии купленная Microsoft, проделала огромную работу по оптимизации R. Их продукт Revolution R теперь известен как Microsoft R Open.
Одним из преимуществ этой сборки является использование библиотеки Intel Math Kernel Library, которое значительно ускоряет матричные операции (заметно при работе с большими матрицами).
Где скачать: https://mran.microsoft.com/download
Инструкция по установке: https://mran.microsoft.com/documents/rro/installation
Если всё сделано правильно, после установки вы увидите нечто подобное:
Бенчмарки: https://mran.microsoft.com/documents/rro/multithread
15. JIT-компилятор
Во времена версии 2.13 интерпретатора R один из его ведущих разработчиков создал пакет compiler, который значительно улучшил производительность R при исполнении кода с циклами. Эффект от его использования порой настолько ощутим, что в настоящее время пакет включен в стандартную поставку R, а для всех стандартных функций байткод генерируется на этапе сборки соответствующих пакетов.
Если вы запускаете скрипты с большим кол-вом циклов и ветвлений — попробуйте включить JIT-компиляцию командами:
Подробнее о функциях пакета можно посмотреть в справке: ?compiler::cmpfun.
Функция, которая подверглась компиляции, приобретает дополнительный атрибут «bytecode»:
Если вы оформляете свой код в виде пакетов — включить генерацию байткода при сборке пакета можно добавив строчку "ByteCompile: yes" в файл "DESCRIPTION".
16. Невыполненные обещания
Интерпретатор языка R предпочитает не выполнять обещания, если это не имеет последствий. О чём я вообще? Да об объектах типа "promise".
Изобразим подобие логгера:
Логгер этот не имеет ни малейшего понятия о том, будет ли реально записано сообщение, или же можно даже не надрываться, склеивая его кусочки. Поэтому я прибегнул к хитрости, выполнив склеивание кусочков сообщения в значении по умолчанию одного из аргументов функции log.write.msg(). И если реального обращения к этому аргументу не произойдет — значение по умолчанию вычислено не будет.
Можете мне поверить: если ваш код пишет многие миллионы записей уровня TRACE в лог, а в продакшене вы используете уровень сообщений DEBUG, под который попадает пара тысяч строчек лога — экономия на склеивании кусочков сообщений составит десятки минут, если не часы.
17. Объектно-ориентированное программирование в R
Язык R содержит несколько встроенных моделей для ООП, и ещё большее их количество реализовано в различных пакетах.
Итак:
1-3: S3, S4, reference classes;
4: Эмуляция объектов на основе замыканий (closures);
5: R.oo;
6: R6.
(это только то, что с ходу вспомнилось и нашлось)
На мой взгляд, ни одна из встроенных моделей (1-3) не отличается ни хорошим быстродействием, ни удобством.
Если вам не требуется наследование — можно реализовывать объекты на основе замыканий:
В остальных случаях — мой выбор за R6. Быстрый, удобный, с минимальными накладными расходами. Возможностей поменьше, чем в C++, но это даже хорошо! :)
Но есть и нюансы, обусловленные тем, что было изложено в части 10.
1. Желательно отключать клонирование объектов. Оно реально редко нужно, но увеличивает memory footprint мелких объектов в 5 раз.
2. Нужно аккуратно подходить к выбору environment'а в котором создаются генераторы объектов (результат деятельности функции R6Class; экземпляры класса создаются путём вызова метода $new() у генератора). Идеальный случай — когда генераторы размещены внутри пакета, тогда они почти наверняка ничего лишнего не захватят из global environment.
18. Распараллеливание вычислений между несколькими экземплярами интерпретатора
Ядро интерпретатора R (core и унаследованные от него версии, такие как Microsoft R Open) является однопоточным, поэтому для простейшего распараллеливания требуется запуск нескольких его экземпляров, а также механизм для взаимодействия между процессами.
Задачу написания удобного механизма для параллельных вычислений в R пыталось решать немало людей (поищите слово «parallel» в списке пакетов), однако наиболее качественное (на мой взгляд) решение получилось у Revolution Analytics. Их пакет foreach способен работать с несколькими бэкендами:
1. предоставляемым стандартным пакетом parallel;
2. предоставляемым пакетом doSNOW (он был взят за основу при создании пакета parallel);
3. предоставляемым пакетом doParallel;
4. предоставляемым пакетом doMC.
В целом сочетание parallel+foreach можно использовать из коробки и получать ускорение вычислений.
parallel позволяет создавать кластер двумя способами — fork'ом процессов (?parallel::makeForkCluster) или запуском экземпляров Rscript (?parallel::makePSOCKcluster). Плюсы и минусы этих вариантов:
1. Fork cluster:
+ Мгновенный запуск;
+ Все данные с мастер-ноды сразу после запуска присутствуют на всех нодах кластера;
+ Не нужно тратить время на загрузку пакетов на нодах кластера;
— При срабатывании GC на нодах кластера существенно растет расход памяти в системе; если память закончится — кластер упадёт (или мастер-нода, как повезёт);
— Не работает под Windows;
2. PSOCK cluster:
+ Работает на всех ОС;
+ Максимальная гибкость в раздаче данных на ноды кластера и в подгрузке пакетов;
— Расходуется время на запуск кластера, раздачу данных и подгрузку пакетов;
— «Из коробки» нестабильно запускает кластер более чем из 16 нод; требуется специальная обёртка вокруг Rscript, которая будет ожидать появления слушателя у порта, прежде чем дать мастер-ноде к нему коннектиться;
— Требуется доработка напильником для распараллеливания раздачи данных (скинуть данные во временный файл и прочитать его параллельно на всех нодах).
И о других способах.
1. doMPI + Rmpi: из коробки не удалось заставить работать достаточно быстро.
2. SparkR: сложен в установке, модель вычислений подойдет не для всякой задачи.
19. Распараллеливание вычислений внутри интерпретатора
Вот как выглядел вызов кода на C++ из R лет 10 назад. Залезаешь в чёрную-чёрную консоль, колдуешь "R CMD SHLIB bla-bla-bla", делаешь dyn.load() полученного бинарника, и пытаешься чего-нибудь повызывать функциями .C(), .Call(), .External(). А чтобы взаимодействовать с R'овскими объектами — приходилось лезть в исходники интерпретатора и читать R Internals.
Теперь это всё практически не нужно, потому что появился пакет Rcpp. Для работы этого пакета потребуется установить Rtools — тулчейн, используемый для сборки интерпретатора R.
Для распараллеливания кода удобно использовать пакет RcppParallel, в основе которого лежит библиотека Intel Thread Building Blocks. К сожалению, к ядру интерпретатора R нельзя обращаться из разных потоков, поэтому в определенных случаях вам потребуется самостоятельно реализовывать некоторые функции или подключать сторонние библиотеки. Для работы с векторами и матрицами я рекомендую использовать RcppArmadillo (документация к Armadillo); в некоторых случаях сгодится RcppEigen.
Разумеется, скорость разработки на C++ получается ниже, чем на R, однако в вычислительных задачах сочетание библиотек Rcpp+RcppParallel+RcppArmadillo позволяет выжать из железа практически всё.
20. Переупаковка объектов
Этот вопрос я рассмотрю на примере класса timeSeries из пакета timeSeries.
Допустим, у нас есть экземпляр такого класса, в столбцах которого содержатся цены некоторых инструментов, и мы хотим к каждому столбцу применить 100 раз экспоненциальную среднюю скользящую. Записать это можно примерно таким образом:
Если вы обратили внимание на часть 3, то рано или поздно вы обнаружите, что немало времени уходит на создание объектов типа timeSeries. Но ведь объект создается один раз, в самом начале — спросите вы. А вот и нет. Заглянем в вариант функции apply(), который будет вызываться для класса timeSeries:
Видим, что объект разбирается на атрибуты, преобразуется в матрицу (?timeSeries::getDataPart), обрабатывается, а затем преобразуется обратно в объект класса timeSeries. Если избавиться от лишних преобразований типов — код будет работать быстрее:
Пока что на этом всё. Если я вспомню ещё какие-то интересные детали, а также увижу интерес к теме — будет продолжение.
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба