


19 ноября 2019 smart-lab.ru
Если вы посмотрите на выступление какого то гуру ML или разработчика софта под это дело, то высокий шанс увидеть мекающее и бекающее существо, рассуждающее в духе «ну мы точно не знаем как это работает, но эмпирически мы получили что вот если взять куриную косточку смешать ее с пеплом единорога и трижды ударить в бубен, то результат получится очень даже ничего...». ML новая область и многим фишкам применяемым там, нет какого то четкого математического обоснования.
Я само собой тоже шаманю, бью в бубны. Например-стоил ли взять максимально большой набор данных для train или лучше брать последние как наиболее актуальные. Или например работа с фичами-допустим посчитал я модельку для первых 2 лет, оказалось что так и так наиболее актуальны из них 10. Стоит ли в следующий train брать только их, или стоит опять брать полный набор фичей. Как насчет порога вероятности? Для модельки с одними параметрами, порог в 55% будет самое то, для другой лучшим будет 57,5%. Я не говорю о гиперпараметрах в самих модельках. То есть если прикинуть все возможные комбинации, то мы получим сотни если не тысячи вариантов, и сразу возникает вопрос о подгонке. Впору забить на все эти ML и вернуться к старомы доброму надра… ию в WealthhLab.
Вот например берем те же данные, но решает задачу прогнозирования в xgboost которая считается развитием RF. Опять не паримся по поводу гиперпараметров (хотя они конечно очень важны), а просто смотрим что у ней на train, что на test, а что на out.
Сразу бросается в глаза, что показатели accuracy у ней гораздо выше, если в предыдущем примере RF показывал на train что то вроде 60%-65%, то xgboost легко выбивает под 70% (если усложнить можно нарисовать и 99%). Но при выборе условия на out для входа в сделку порога в 55%, мы получаем много много сделок (что похвально) с весьма низкими значениями средней профитности (что понятно иначе чем пачалькой не назвать).
Ну что такое средний профит в 0,23%? Половину сожрет комиссия, половину проскальзывание. Зато в некоторые годы сделок очевидно слишком много, впору повышать порог входа. Вопрос как об этом знать заранее?! Ну допустим на основе accuracy на test периоде-начинаю бить в бубны, что в ML называют словом «эвристика». Когда нет четкого обоснования data scientists прикрывают свою голую жопу этим словом. Вот входы с порогом в 57,5%:
Если сравнить xgboost с RF то увидим одно очень неприятное явление, xgboost рулит на test, но когда приходится показывать себя в боевых условиях то говоря словами Леонова в фильме Афоня: «стабильности нет». Глядя по годам — то мало сделок, то много, то приличная средняя доходность то так себе. Классический пример overfittinga, когда лучше попроще.
ML - to be or not to be
Когда мы используем методы ML, получая унылые результаты при прогнозе, мы точно не знаем кто в этом виноват и что делать. Ведь вариантов может быть несколько:
1. ML говно
2. Данные говно
3. Рынок говно
4. Все вместе или попарно говно
5. Ты говно
6. Весь мир говно
Последние варианты рассматривать не будет, конструктивно остановимся на первых. «Данные не те». Ну правда, метод может быть хорошим, рынок может по устойчиво демонстрировать прежние тенденции, но так как мы модель скормили мусором, то ничего кроме мусора не могли получить при прогнозе. Под мусором я понимаю размер данных и бессмысленные фичи. «Рынок не тот». Не в том смысле, что я весь такой Д`Артаньян, а вот рынок подкачал, а в том что тенденции сменились, ну вот 10 лет была одна манера поведения рынка, а потом в силу геополитики или макроэкономике или каких то институциональных изменений рынок изменился, и то что раньше было вкусно, питательно и сытно, нынче конкурирует с подбрасыванием монетки. «Метод не тот». А тут у нас типа руки растут из жопы и мы не понимаем как вообще все это работает, что такое валидация, тесты, подгонки, метрики качества. Где надо нейросети мы использует бустинг, где надо бустинг используем нейросети. Меня интересует больше ответ на вопрос «а этот ML вообще что то на фондовом рынке может?!» и чтобы ответить на него я сделаю так, чтобы не было никаких проблем ни с данными ни с рынком, то есть чтобы виновник сразу был очевиден.
Я уже писал об этом так что просто вставлю копипаст на самого себя:
Я сгенерировал DataFrame в 50 тысяч строк, где в качестве таргета использовал 1 или 0, а в качестве 100 фичей ряды из совершенно рандомных значений от 1 до 10. Но что я зверь какой то, чтобы предлагать спрогнозировать 1 или 0 на основе белого шума?! Нет, я сгенерировал один ряд осмысленный — день недели (Week). И когда тяпница я задал, что вероятность наступления события 1 равно 60%, а 2-40%. То есть классическая задача которую я решаю, под мое виденье что такое рынок: 80% времени белый шум, а в 20% случаях есть некоторая неффективность в размере 60 против 40 на получение конкретного значения.
Что мы ожидаем от ML если это нормальный инструмент а не танцы с бубнами?! Во первых мы должны получить то значение accuracy что и заложена в ряд. А это 60%*0,2+50%*0,8=52%. Вот наш реальный предел к которому мы и должны стремится, все что выше это «танцы с бубнами». Кроме того мы должны получить четкое указание на особую ценность фичи Week, и на близкую к нулю значимость всех остальных фичей.
Сыпь гармоника!… То есть запускаю свой RF.
У меня показатели accuracy по трем типам данных-Train, Test, Out. Out это прогноз. Первая закавыка возникала когда использовал глубину RF в 20. Тут Train accuracy подскакивала до 57%, то есть в ряде где осмысленность на 52%, она находила все 57%. Вот вам первый ответ почему у многих не получается в ML. ML такая штука что может найти черную кошку в черной комнате даже если ее там нет.
Как такое возможно спросите вы, вот попробую обьяснить на пальцах:
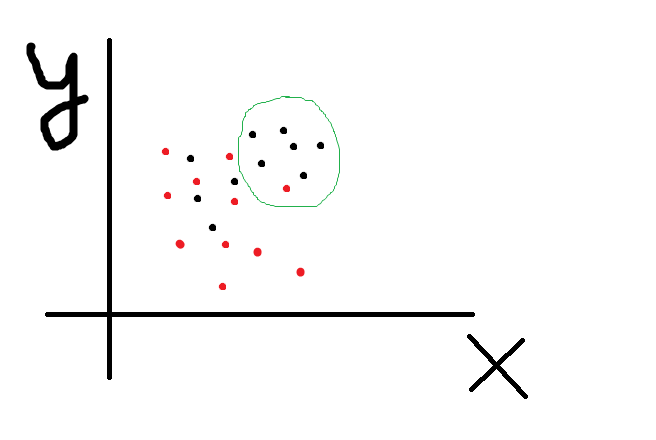
X и Y это 2 наши фичи, черные точки событие 1, а красные событие 2. Вот мы хотим с помощью комбинации фичей разделить множество точек так чтобы по одну сторону линии было как можно больше красных, а по другую черных. То есть решаем задачу классификации. Зеленым я обозначил ту область где черные явно кучкуются, то есть можно предположить что при бОльших значениях X и Y вероятность черноты выше. А извращенцы из ML могут построить какую угодно сложную линию, например так что вообще все черные отделятся от красных:
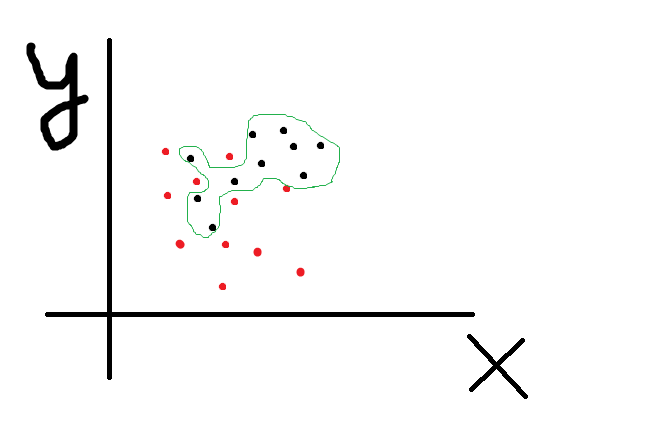
Accuracy 100%. Но вот мы полученную формочку пробуем натянуть на новые данные и получаем что то вроде
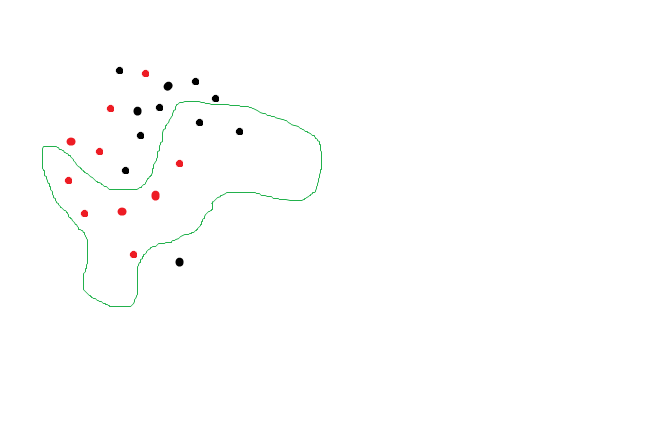
Ой, мы пытались спрогнозировать черноту а нашли красноту! Очевидно что тенденция сохраняется, черные точки кучкуются где то наверху, но так как мы переусложнили модель, то при прогнозе получили ерунду. И RF с глубиной деревьев 20 нарисовал изощренно сложные линии которые разделили точки с accuracy 57% то есть нашли то чего там и нет. А нейросеть позволяет достичь 100% accuracy на трейне и даже на тесте, ибо может, даже если фичи случайны. Таки дела.
Part 2
Ну вот значит мы получили, что если переусложнить модель, то можем найти черную кошку в черной комнате, даже если ее там нет. Но RF позволяет еще и оценить значимость той или иной фичи, и даже получить пороговые значения, по которым RF и принимает решения. Напомню что в качестве смысловой фичи у нас выступает Week. Когда Week от 1 до 4 (что символизирует дни от понедельника до четверга), то вероятность события 1 и 2 50/50. То есть белый шум. А вот когда 5 (пятница), то с вероятностью 60% наступит событие 1, то есть вот та самая неэффективность которую мы и ищем на рынке.
С помощью команды feat_importances = round(feat_importances.nlargest(10), 3) выводим самые важные по мнению RF фичи. Сначала выводим по итогам трейни на первых 10 тысяч данных и… о ужас:
Week у нас всего лишь на 6 месте с ничем не примечательными коеффами важности, а во главе фича «46», которая между нами говоря никакого смысла и не имеет, ибо случайно сгенерированный ряд. Обьяснить это можно только одним-фича week детерминирует наш таргет на 52%, что совсем не густо, а фича 46, была сгенерированна так что ее ценность случайно оказалась выше. Ну то есть мы все понимаем что если посадить макаку торговать, то будет она торговать в ноль, но если посадить 1 млн макак и каждой дать по терминалу, то наверняка среди 1 млн окажется парочку «макак-гуру», которые в силу случайности покажут длинную серию успешных трейдов (я кстати думаю что также обьясняется появление гуру среди людей), а если посадить за комп 1 млрд макак, то наверняка парочка вообще не совершит неправильных кликов, и это будет «макака-Баффет», все будут смотреть ей в рот, удивляться ее гениальности, а «макака Баффет» откроет блог и начнет давать советы как торговать правильно. Ну вот и в нашем пример, так получилось, что макака под номером «46» случайно понажимала кнопки правильней и RF назвал ее особо ценной.
Само собой случайность она на то и случайность, что взяв тестовый переиод уже за два года мы «макаку 46» уже и не увидим:
У нас «макака 39» в лидерах. Ну и бес с ней, главное что та единственная, действительно разумная фича скаканула на 2 место.
Трейн за три года:
За 4:
За 5
Но хотя по мере роста выборки все вроде встает на свои круги, однако по прежнему RF считает что помимо week есть другие фичи с далеко не нулевой ценностью. Так что если вы вдруг нашли чудесный индикатор который чего то там предсказывает, или нашли гуру, «который никогда не ошибается» то может все дело в… макаке. Точно могу сказать что для RF такие макаки не нужны, они скрывают за своим шумом истинные фичи, так что если кто то думает «загоню побольше фичей а дальше и так сойдет» — то не сойдет.
А теперь глянем под капот RF чтобы понять, правильно ли наша моделька определила пороговое значение фичи week. Вуаля:
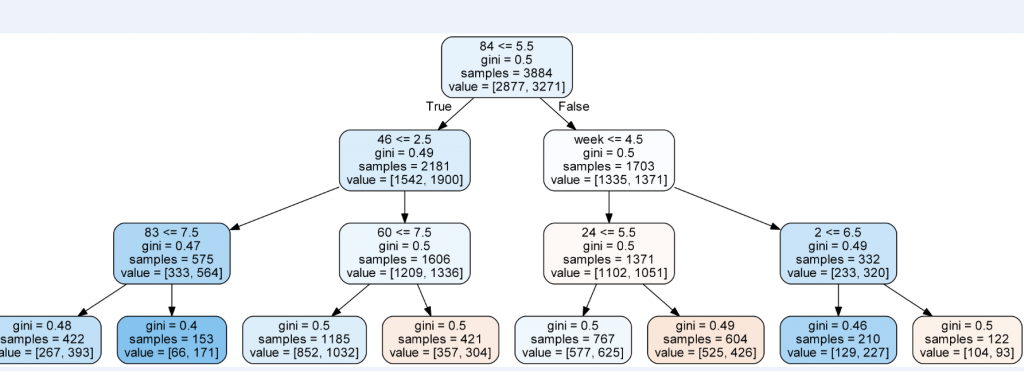
На втором уровне справа видим Week с порогом 4.5, то есть RF все сделал правильно.
Part 3
Оценки для RF получили, под капот заглянули, хотелось бы теперь и ручками все проверить-посмотреть. Тем более что косяк у RF есть, он единственную смысловую фичу ставил не в вершине дерева, а только второй а порой и третьей после случайно сгенерированной. То есть примерно половина событий сразу криво отсекалось.
Выгрузил в excell сгруппировал и получил примерно такое:

А это, кто не понял-крах! Это как нейросетка которая в качестве прогноза завтрашней цены показывает последнюю цену из теста. Вот и здесь та же история-RF просто 40861 раз из 41216 (99% случаев) спрогнозировал 1, потому что единица в выборке встречалась в 52% случаях. То есть RF поступил как поц на рынке, который увидел что рынок в среднем чаще растет и решил постоянно ставить на рост, при том что у меня был зашита вполне конкретная зависимость.
Но горевать не будем, потому что насколько убого себя показал RF, настолько блестяще показал себя GradientBoostingClassifier:

Сразу видно что GradientBoosting тупо не ставит постоянно на единичку, он явно что то нащупал. С дополнительной разбивкой по дням недели:

Видно что GradientBoosting четко отнес все пятницы к событиям 1 (8224 раза против 7), а все остальные дни недели оценил как 60 на 40 в пользу события 1. Верно было бы если он оценил 50 на 50, но по сравнению с идиотом RF это огромный прогресс. Если взять порог в >55%, то получится еще красивей:

То есть с таким порогом у нас точность прогноза составит 99,5% пр полноте 85,72%. То есть мы выловили 85,72% осмысленных событий, и при этом делая прогноз, были точны в 99,5% случаев. Можно констатировать что GradientBoosting без особых настроек выловил практически все. А вот RF запутался в 100 случайных фичах и делал наивные прогнозы. Думаю именно в этом причина того что RF, на реальных данных и с осмысленными фичами, показавший себя лучше GradientBoosting, при засланных казачках потерялся и не смог решить заданную ему головоломку. Если помочь RF, и уменьшить число рандомных фичей и использовать порог, то он оживает и показывает вразумительные результаты.
Part 4
Напомню был сгенерирован DateFrame со 100 бессмысленными фичами и одной осмысленной, для проверки могет ML или не могет. Как оказалось GradientalBoosting могет и еще как, RF могет, но хуже. Что покажут нейросети? Нейросетей много, архитектур много, настраивать их не просто, я предложил решить задачу нейросети со следующей архитектурой:
Тут все как положено — сверточная нейросеть, модная функция активации ReLU, широкой рукой накиданные Dropoutы и BatchNormalization, несколько слоев чтобы похвастаться не просто об обучении, а о глубоком обучении. Обучал на 100, 500 и 1500 эпохах. При увеличении числа эпох росла accuracy на train и на test, далеко превосходя заложенную accuracy ряда. При попытках использовать обученную нейросетку для прогноз получался один большой пфук.
По табличке:

кажется что нейросеть не безнадежна, то где она указывала в прогнозе на событие 1, это событие происходило в 56% случаях, там где предсказала что событие 1 не произойдет, точность составила 55%. Кажется ничего так. Но как мы помним единственная осмысленная фича это Week, и весь юмор ситуации в том что нейросеть строили прогноз на основе махинация с рандомными рядами.

Вот прогноз события 1 с разбивой по Week. Если бы нейросеть сообразила что все дело в этой фиче а остальные просто мусор, то число прогнозов события 1 для week=5 значительно превосходила бы то же самое для остальных значений week, но как мы видим это не так, да их побольше но разве что на чуть чуть. Использование порога в 55% принципиально ничего не поменяло:

Вывод очень простой-мы скормили нейросетке 100 фальшивых фич и 1 реальную. Нейросеть не смогла найти настоящую, вместо этого она с упоением придумала липовые зависимости между фальшивками (причем каким то образом стругая эти зависимости, прогнозы каким то образом оказывались лучше чем простое подбрасывание монетки). То есть можно предположить, что если вы попробуете закинуть в нейросетку много много фичей для прогноза на фондовом рынке, из которых многие не имеют никакого значения, в надежде что нейросетка то разберется, что стоящее, а что мусор, то ничего подобного-нейросетка из многих многих бессмыслиц способна найти псевдо связи, а до той или тех стоящих фичей дало даже не дойдет! Вот вам и наглядная демонстрация почему нейсросетки на фондовом рынке не могут.
Part 5
Продолжу изучение нейросетей. Для тех кто случайно наткнулся на этот пост, но не хочет ковырять предшествующие поясняю.
Был сгенерирована табличка в 50 тысяч строк и 103 столбцов. Один столбец это даты, еще один — таргет, который мы пытаемся предсказать (событие 1 и событие 0). 101 столбец изображают фичи, из которых 100 случайные величины от 1 до 10, а одна осмысленная (Week) принимает значение от 1 до 5. Для week от 1 до 4 равновероятно событие 1 и 2, для Week = 5 вероятность события 1 = 60%, 2 = 40%.
«Шо за фигня аффтор?!». Фигня не фигня, а я моделирую свое виденье рынка и своего подхода к поиску рабочих стратегий. Виденье рынка предполагает что рынок рандомно блуждает значительную часть времени (в моему случаи 80% времени), а оставшееся его можно описать несколькими хорошими фичами. Ну как описать? Не на 100%, ну а где то процентов на 60. Сравните с детерминированным подходом ученых столетней давности — «если нам дать все фичи и много много вычислительных мощностей мы вам все посчитаем, с точностью в 100% и для любого мгновения времени!». Понятно что после этого появилось много других идей, нелинейная динамика к примеру, которая именно предполагает принципиальную невозможность прогнозирования, а не потому что нам чего то в данных недодали. Ну и наконец постановка задачи: у нас есть 101 фича, и нам с помощью инструментов ML надо получить такой прогноз события 1, который бы бился с заложенной нами неэффектиностью. И тут не помогут завывания нейросетей-что мы «фичи кривые заложили, на которых совершенно невозможно работать!», что «просто рынок изменился!, не имезнился мы бы огого!». Нам совершенно плевать на accuracy на трейне и даже на тесте. Мы как тот глупый учитель, который может не очень то и соображает зато у которого на клочке бумажки записан правильный ответ, а напротив него ученик, в очечках, но у которого почему то при всех сплетнях что он в уме может перемножить трехзначные цифры, при сложения 1+1, получается то 5, то 6 то -32. Не, конечно вариант что мальчик в очечках не так уж и не прав возможен, может он считал в невклидовых метриках к примеру, или перемножать он умеет а вот что такое складывание ему просто не сказали.
Ну минута лирики закончилась, что у нас в итоге? В итоге у нас нейросеть совершеннейшим образом облажалась, запутавшись в 100 рандомных фичах и совершенно не заметив ту самую единственную стоящую. Что мы можем? Можем облегчить задачу уменьшив число рандомных фичей со 100 до 10 (10+1) а затем до 2 (2+1), а можно оставить нейросеть наедине со стоящей фичей (0+1), для смеха. А можем дать нейросетке работать не 50 тысячах примерах, а на нескольких миллионах.
Правильный ответ по Week:

Напомню нейросетка 100+1 предсказала событие 1 (с разбивкой по Week) так:

Нейросеть 10+1:

2+1

0+1

По мере уменьшения числа рандомных фичей, результаты типа улучшаются. Уменьшая число рандомных фичей, мы ограничиваем нейросеть в возможности фантазировать в поисках фальшивых закономерностей, и одновременно тыкаем ее носом в правильный ответ. Апофеоз наступает в последним примере. Я не разу не специалист в нейросеть, все это досужие фантазии от меня, но в ироническом стиле опишу как скрипит мозгами нейросеть: «так, мне чего то сунули. таргет, а вот фичи… ой, фича! почему то 1 фича… хмм… к чему бы это?! ну ладно, таргет у нас принимает два значения, причем на выборке событие 1 в 52% случаях. То есть если мы будем постоянно предсказывать событие 1, то у нас будет точность 52%. Ура! ну ладно попробуем что то выжать из фичи чтобы повысить точность....». Вот так я очеловечил рассуждения нейросети, то есть придал ей способность мыслить. А все потому что я заметил одну очень интересную штуку-в последнем примере нейросеть правильно отнесла все Week=5 к событию 1. Но после этого остались week от 1 от 4, и нейросеть могла поровну каждому варианту накидать по событию 1 и событию 2. Но она так не сделала. Она «поняв» что Week=5 дает повышенную вероятность события 1, стала повышать вероятность события 1 для Week=4 и Week=3, как ближе стоящему к Week=5, и уменьшать для Week=1 и Week=2. RF (бустинг) не может экстраполировать, она может только брать примеры из трейни, и осуществлять разбивку, а если на тесте встретить неизвестное из трейни значение фичи, то тупик-с. И разбивку Бустинг осуществил так:

он правильно указал на Week=5, но для него что Week=1, что Week=2, что Week=3, что Week=4 это все одна равновероятная каша, он их не отличает, поэтому он раскидал событие 1 ровненько. А нейросеть так:

и возможно я фантазирую, но тут нейросеть демонстрирует возможности экстраполяции, то есть рассудочной деятельности. Так что получается что бустинг это как калькулятор, который точно посчитает что вам надо, но никаких шаг вправо шаг влево, а нейросети как это как человек-гуманитарий которого попросили на экзамене что то там посчитать. Считать он не умеет, поэтому если ему накидают кучу цифр он запутается, и получит ответ кривой и косой, но так зато у него есть какая никакая логика, суждения, мыслительный процесс, и жизненный опыт он может прикинуться больным или может предположить что «если 5 это хорошо, о все что рядом с 5 тоже неплохо, а вот все что далеко от 5 это не очень». Так что покачиваясь в кресле можно порассуждать на тему «а что то в этих нейросетях есть».
И я опять попробую изобразить как нейросеть рассуждала после того как обнаружила что в week=5 что то есть: «оке, при пятере че то там есть. оке, когда week=5, кинем туда все события 1. ну вот у нас осталось еще куча других примеров, с ними то что делать?! как как раскидать по week&! ааа… ну понятно, что ближе к week=5?! week=4! вот и кинем все оcтальные события 1 в week-4! сколько еще остается событий 1?! 1715 штук! оке, кинем их все в week=3!» Впрочем очень может быть что все это мои больные фантазии
Чувствительность методов ML к размеру обучающей выборки. Part 6
В прошлом тексте я пробовал «помочь», нейросете уменьшив число рандомных фичей. Сейчас попробую помочь увеличив число примеров. Может наша сверточная сеть покажет что то вменяемое если увеличить число примеров до миллиона? Это задача на моем компьютере требует совершенно других затрат времени, так что я вчера запустил машинку обучаться, а сам пошел спать. Обучался на 50 эпохах, увеличивая данные от 10 тысяч до 50 тысяч (увеличивая обьем на 10 тысяч), и от 100 тысяч до 900 тысяч (с шагом +100 тысяч).
Результаты порадовали. Я не буду в 5 раз пересказывать логику «исследования», но убрав week=5 мы должны (ну как должны!? вообще то нам никто ничего не должен) получить равновероятный прогноз события 1 и события 0. Ниже на графике эту норму в 50% изображает серая линия. Красная это прогноз события=1, синяя событие=0, ось Х число примеров на обучающей выборке в тысячах.

И пусть девочка кинет в меня камне если тут нет сходимости.
Но это динамика при увеличении обучающей выборки от 100 тысяч до 900 тысяч, а вот если сюда присовокупить от 10 тысяч до 50, тут все не так очевидно:
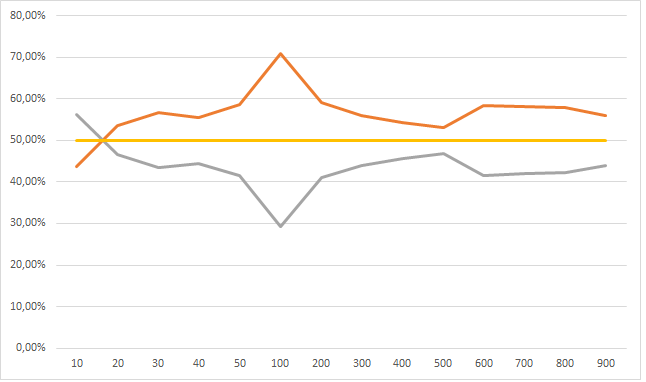
У меня следующее обьяснение: нейросеть большая фантазерка, в том смысле что способна найти в числах даже то чего там и нет. Но с другой стороны нельзя сложить из букв «п», «ж», «о», «а» слово вечность, поэтому когда обучающая выборка очень маленькая фантазии нейросети ограниченны. По мере роста обучающей выборки, нейросеть начинает находить все больше и больше черных кошек в черной комнате, которых там нет, и так до размера выборки в 100 тысяч примеров. По мере дальнейшего размера выборки фантазию нейросети начинает ограничивать реальность-сложно аппроксимировать 101 фичей данные размером в сотни тысяч. Ну это ИМХО.
Поставив week = 5 мы должны получить другой тип сходимости. Пробую обьяснить-если нейросеть правильно все разобрала, а именно поняла что единственная значимая фиxа это week и именно при week = 5, то число событий 1 она должна как можно чаще закидывать в week = 5. Смотрим:
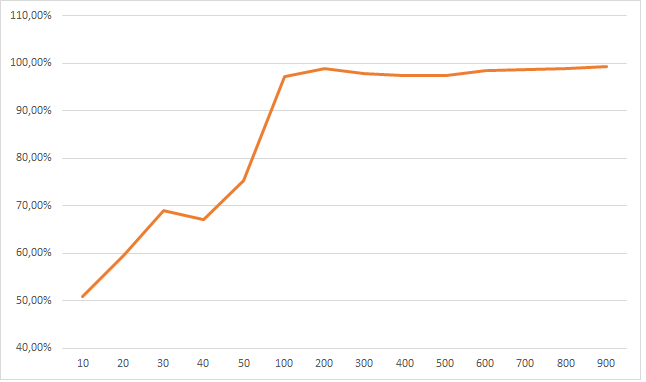
Линия обозначает как часто прогнозировалось событие 1 при week=5, видим как по мере увеличения обучающей выборки нейросеть все уверенней делает правильный выбор. Опять зовем девочку готовую кинуть камень, если тут нет сходимости к 100%.
Впрочем у нас есть еще один трюк. Ведь можно с разной долей уверенности делать прогноз. Нейросеть нам одинаково спрогнозирует событие 1, даже если его вероятность она оценивает в 50,0000001% и 55%, но степени уверенности разные. Если поработать не с абсолютными прогнозами а вероятностными вылазит очень много интересных вещей.
Что на 2 таблицах ниже: вероятность это уверенности с какой нейросеть предсказывает событие 1, а столбцы 1,2 ..5 это дни недели. Данные в процентах по строкам. Давайте подумаем. Если нейросетка раскусила что при week=5, вероятность события 1 выше, большей уверенностью предсказывать событие 1 при week=5, а при прочих week она будет сигнализировать о своей неуверенности низкими процентами вероятности.


Первая таблица прогнозы полученные при обучении от 100 тысяч примеров, ниже до 50 тысяч. Видим что размер опять решает-чем лучше мы накормили свою нейросетку, тем лучше она вычленяет week=5. Вверху сеть четко указывает что при уверенности в 50% в своем прогнозе события 1, нейросеть 98% (100% -2%) относит их на week от 1 до 4, в то время как в нижней таблице размытая каша, нейросеть четко не отличает что где, когда и зачем. И если смотреть с другого конца таблиц, например уверенность в 60%: вверху нейросеть уже относит такой уверенный прогноз для week=5 в 90,69% случаях, в то время как скудно обученная нейросеть, опять мнется-у ней week=5 составляет долю всего в 29%.
Как мы можем это использовать? А очень просто, мы говорим-нам не нужны прогнозы если нейросеть сама в них уверенна только на 50% с хвостиком. Мы хотим рассматривать прогнозы только начиная от 55% уверенности. Оке. Выкидываем, получаем для нейросети обученной на выборках от 100 тысяч:

Так какой можно сделать вывод? Нейросети оказались вовсе не так безнадежны, и если им дать обучиться на выборке где то начиная от 200 тысяч примеров, то они начинают сносно выделяют верную фичу из 100 рандомных, показывая при пороге в 55% precision (точность) где то в 57% (при максимуме в 60%) и recall (наполненность) в 90%. До GB не дотягивает, но можно пофантазировать что если взять 2, 3, 10 млн примеров, то нейросеть наконец то все разложит по полочкам.
Для GB я тоже потестил при обучении от 100 до 900 тысяч примеров и сравнил с нейросеткой:

Ну тут все понятно. GB начиная с выборки в 300 тысяч примеров показывает 100% результат: все события 1 кидает в week=5, а для всех остальных раскидывает события поровну, в то время как нейросетка чего то пытается нащупать.
Таки дела
P.S. Отвечая на вопрос в чем вывод: я в процессе, но пока получается вывод такой-для моей постановки задач в трейдинге, нейросети вообще нафиг не нужны. Им нужно кучу данных, они путаются, они нервные как барышни, они фантазерки, придумывают чего нет. А вот RF и GB просты и надежны как калькуляторы. При этом нейросети (теоретически!) не нуждаются в предварительной и очень утомительной работе с фичами, а RF/GB без этого ну никак. И если нейросети реально имеют какой то рассудок, они могут сделать прогноз на основе «творческой» работы с данными, то RF/GB работают в рамках примеров, ни шаг влево ни шаг вправо, никаких экстраполяций. Так что нейросетки действительно могут творить, то чего мы даже не предполагаем и не задумываем… и как знать, может то что нейросетки показывают нам фигу при попытке внедрить их на фондовом рынке, это их сигнал-«бегите безумцы, тут ловить нечего!»
Я само собой тоже шаманю, бью в бубны. Например-стоил ли взять максимально большой набор данных для train или лучше брать последние как наиболее актуальные. Или например работа с фичами-допустим посчитал я модельку для первых 2 лет, оказалось что так и так наиболее актуальны из них 10. Стоит ли в следующий train брать только их, или стоит опять брать полный набор фичей. Как насчет порога вероятности? Для модельки с одними параметрами, порог в 55% будет самое то, для другой лучшим будет 57,5%. Я не говорю о гиперпараметрах в самих модельках. То есть если прикинуть все возможные комбинации, то мы получим сотни если не тысячи вариантов, и сразу возникает вопрос о подгонке. Впору забить на все эти ML и вернуться к старомы доброму надра… ию в WealthhLab.
Вот например берем те же данные, но решает задачу прогнозирования в xgboost которая считается развитием RF. Опять не паримся по поводу гиперпараметров (хотя они конечно очень важны), а просто смотрим что у ней на train, что на test, а что на out.
Сразу бросается в глаза, что показатели accuracy у ней гораздо выше, если в предыдущем примере RF показывал на train что то вроде 60%-65%, то xgboost легко выбивает под 70% (если усложнить можно нарисовать и 99%). Но при выборе условия на out для входа в сделку порога в 55%, мы получаем много много сделок (что похвально) с весьма низкими значениями средней профитности (что понятно иначе чем пачалькой не назвать).
2011<br />count 2112.00
mean -0.01
2012<br />count 211.00
mean 0.72
2013<br />count 928.00
mean 0.18
2014<br />count 1182.00
mean 0.33
2015<br />count 341.00
mean 0.86
2016<br />count 172.00
mean 0.83
2017<br />count 458.00
mean 0.22
2018<br />count 87.00
mean 0.23 Ну что такое средний профит в 0,23%? Половину сожрет комиссия, половину проскальзывание. Зато в некоторые годы сделок очевидно слишком много, впору повышать порог входа. Вопрос как об этом знать заранее?! Ну допустим на основе accuracy на test периоде-начинаю бить в бубны, что в ML называют словом «эвристика». Когда нет четкого обоснования data scientists прикрывают свою голую жопу этим словом. Вот входы с порогом в 57,5%:
2011<br />count 1340.00
mean 0.02
2012<br />count 79.00
mean 0.88
2013<br />count 505.00
mean 0.24
2014<br />count 655.00
mean 0.49
2015<br />count 143.00
mean 1.02
2016<br />count 35.00
mean 0.72
2017<br />count 148.00
mean 0.31
2018<br />count 23.00
mean 0.61 Если сравнить xgboost с RF то увидим одно очень неприятное явление, xgboost рулит на test, но когда приходится показывать себя в боевых условиях то говоря словами Леонова в фильме Афоня: «стабильности нет». Глядя по годам — то мало сделок, то много, то приличная средняя доходность то так себе. Классический пример overfittinga, когда лучше попроще.
ML - to be or not to be
Когда мы используем методы ML, получая унылые результаты при прогнозе, мы точно не знаем кто в этом виноват и что делать. Ведь вариантов может быть несколько:
1. ML говно
2. Данные говно
3. Рынок говно
4. Все вместе или попарно говно
5. Ты говно
6. Весь мир говно
Последние варианты рассматривать не будет, конструктивно остановимся на первых. «Данные не те». Ну правда, метод может быть хорошим, рынок может по устойчиво демонстрировать прежние тенденции, но так как мы модель скормили мусором, то ничего кроме мусора не могли получить при прогнозе. Под мусором я понимаю размер данных и бессмысленные фичи. «Рынок не тот». Не в том смысле, что я весь такой Д`Артаньян, а вот рынок подкачал, а в том что тенденции сменились, ну вот 10 лет была одна манера поведения рынка, а потом в силу геополитики или макроэкономике или каких то институциональных изменений рынок изменился, и то что раньше было вкусно, питательно и сытно, нынче конкурирует с подбрасыванием монетки. «Метод не тот». А тут у нас типа руки растут из жопы и мы не понимаем как вообще все это работает, что такое валидация, тесты, подгонки, метрики качества. Где надо нейросети мы использует бустинг, где надо бустинг используем нейросети. Меня интересует больше ответ на вопрос «а этот ML вообще что то на фондовом рынке может?!» и чтобы ответить на него я сделаю так, чтобы не было никаких проблем ни с данными ни с рынком, то есть чтобы виновник сразу был очевиден.
Я уже писал об этом так что просто вставлю копипаст на самого себя:
Я сгенерировал DataFrame в 50 тысяч строк, где в качестве таргета использовал 1 или 0, а в качестве 100 фичей ряды из совершенно рандомных значений от 1 до 10. Но что я зверь какой то, чтобы предлагать спрогнозировать 1 или 0 на основе белого шума?! Нет, я сгенерировал один ряд осмысленный — день недели (Week). И когда тяпница я задал, что вероятность наступления события 1 равно 60%, а 2-40%. То есть классическая задача которую я решаю, под мое виденье что такое рынок: 80% времени белый шум, а в 20% случаях есть некоторая неффективность в размере 60 против 40 на получение конкретного значения.
Что мы ожидаем от ML если это нормальный инструмент а не танцы с бубнами?! Во первых мы должны получить то значение accuracy что и заложена в ряд. А это 60%*0,2+50%*0,8=52%. Вот наш реальный предел к которому мы и должны стремится, все что выше это «танцы с бубнами». Кроме того мы должны получить четкое указание на особую ценность фичи Week, и на близкую к нулю значимость всех остальных фичей.
Сыпь гармоника!… То есть запускаю свой RF.
У меня показатели accuracy по трем типам данных-Train, Test, Out. Out это прогноз. Первая закавыка возникала когда использовал глубину RF в 20. Тут Train accuracy подскакивала до 57%, то есть в ряде где осмысленность на 52%, она находила все 57%. Вот вам первый ответ почему у многих не получается в ML. ML такая штука что может найти черную кошку в черной комнате даже если ее там нет.
Как такое возможно спросите вы, вот попробую обьяснить на пальцах:
X и Y это 2 наши фичи, черные точки событие 1, а красные событие 2. Вот мы хотим с помощью комбинации фичей разделить множество точек так чтобы по одну сторону линии было как можно больше красных, а по другую черных. То есть решаем задачу классификации. Зеленым я обозначил ту область где черные явно кучкуются, то есть можно предположить что при бОльших значениях X и Y вероятность черноты выше. А извращенцы из ML могут построить какую угодно сложную линию, например так что вообще все черные отделятся от красных:
Accuracy 100%. Но вот мы полученную формочку пробуем натянуть на новые данные и получаем что то вроде
Ой, мы пытались спрогнозировать черноту а нашли красноту! Очевидно что тенденция сохраняется, черные точки кучкуются где то наверху, но так как мы переусложнили модель, то при прогнозе получили ерунду. И RF с глубиной деревьев 20 нарисовал изощренно сложные линии которые разделили точки с accuracy 57% то есть нашли то чего там и нет. А нейросеть позволяет достичь 100% accuracy на трейне и даже на тесте, ибо может, даже если фичи случайны. Таки дела.
Part 2
Ну вот значит мы получили, что если переусложнить модель, то можем найти черную кошку в черной комнате, даже если ее там нет. Но RF позволяет еще и оценить значимость той или иной фичи, и даже получить пороговые значения, по которым RF и принимает решения. Напомню что в качестве смысловой фичи у нас выступает Week. Когда Week от 1 до 4 (что символизирует дни от понедельника до четверга), то вероятность события 1 и 2 50/50. То есть белый шум. А вот когда 5 (пятница), то с вероятностью 60% наступит событие 1, то есть вот та самая неэффективность которую мы и ищем на рынке.
С помощью команды feat_importances = round(feat_importances.nlargest(10), 3) выводим самые важные по мнению RF фичи. Сначала выводим по итогам трейни на первых 10 тысяч данных и… о ужас:
46 0.134
67 0.095
4 0.090
60 0.071
15 0.069
week 0.068
26 0.067
2 0.065
53 0.065
84 0.058Week у нас всего лишь на 6 месте с ничем не примечательными коеффами важности, а во главе фича «46», которая между нами говоря никакого смысла и не имеет, ибо случайно сгенерированный ряд. Обьяснить это можно только одним-фича week детерминирует наш таргет на 52%, что совсем не густо, а фича 46, была сгенерированна так что ее ценность случайно оказалась выше. Ну то есть мы все понимаем что если посадить макаку торговать, то будет она торговать в ноль, но если посадить 1 млн макак и каждой дать по терминалу, то наверняка среди 1 млн окажется парочку «макак-гуру», которые в силу случайности покажут длинную серию успешных трейдов (я кстати думаю что также обьясняется появление гуру среди людей), а если посадить за комп 1 млрд макак, то наверняка парочка вообще не совершит неправильных кликов, и это будет «макака-Баффет», все будут смотреть ей в рот, удивляться ее гениальности, а «макака Баффет» откроет блог и начнет давать советы как торговать правильно. Ну вот и в нашем пример, так получилось, что макака под номером «46» случайно понажимала кнопки правильней и RF назвал ее особо ценной.
Само собой случайность она на то и случайность, что взяв тестовый переиод уже за два года мы «макаку 46» уже и не увидим:
39 0.185
week 0.161
51 0.116
89 0.098
24 0.086
56 0.083
15 0.066
47 0.065
52 0.053
72 0.044У нас «макака 39» в лидерах. Ну и бес с ней, главное что та единственная, действительно разумная фича скаканула на 2 место.
Трейн за три года:
week 0.263
96 0.123
9 0.091
29 0.062
74 0.059
67 0.059
83 0.057
11 0.055
84 0.049
75 0.047За 4:
week 0.188
82 0.089
23 0.083
65 0.074
51 0.069
59 0.065
71 0.065
53 0.063
26 0.058
74 0.057За 5
week 0.314
15 0.155
39 0.104
82 0.083
51 0.077
53 0.073
70 0.069
74 0.045
47 0.034
30 0.024Но хотя по мере роста выборки все вроде встает на свои круги, однако по прежнему RF считает что помимо week есть другие фичи с далеко не нулевой ценностью. Так что если вы вдруг нашли чудесный индикатор который чего то там предсказывает, или нашли гуру, «который никогда не ошибается» то может все дело в… макаке. Точно могу сказать что для RF такие макаки не нужны, они скрывают за своим шумом истинные фичи, так что если кто то думает «загоню побольше фичей а дальше и так сойдет» — то не сойдет.
А теперь глянем под капот RF чтобы понять, правильно ли наша моделька определила пороговое значение фичи week. Вуаля:
На втором уровне справа видим Week с порогом 4.5, то есть RF все сделал правильно.
Part 3
Оценки для RF получили, под капот заглянули, хотелось бы теперь и ручками все проверить-посмотреть. Тем более что косяк у RF есть, он единственную смысловую фичу ставил не в вершине дерева, а только второй а порой и третьей после случайно сгенерированной. То есть примерно половина событий сразу криво отсекалось.
Выгрузил в excell сгруппировал и получил примерно такое:
А это, кто не понял-крах! Это как нейросетка которая в качестве прогноза завтрашней цены показывает последнюю цену из теста. Вот и здесь та же история-RF просто 40861 раз из 41216 (99% случаев) спрогнозировал 1, потому что единица в выборке встречалась в 52% случаях. То есть RF поступил как поц на рынке, который увидел что рынок в среднем чаще растет и решил постоянно ставить на рост, при том что у меня был зашита вполне конкретная зависимость.
Но горевать не будем, потому что насколько убого себя показал RF, настолько блестяще показал себя GradientBoostingClassifier:
Сразу видно что GradientBoosting тупо не ставит постоянно на единичку, он явно что то нащупал. С дополнительной разбивкой по дням недели:
Видно что GradientBoosting четко отнес все пятницы к событиям 1 (8224 раза против 7), а все остальные дни недели оценил как 60 на 40 в пользу события 1. Верно было бы если он оценил 50 на 50, но по сравнению с идиотом RF это огромный прогресс. Если взять порог в >55%, то получится еще красивей:
То есть с таким порогом у нас точность прогноза составит 99,5% пр полноте 85,72%. То есть мы выловили 85,72% осмысленных событий, и при этом делая прогноз, были точны в 99,5% случаев. Можно констатировать что GradientBoosting без особых настроек выловил практически все. А вот RF запутался в 100 случайных фичах и делал наивные прогнозы. Думаю именно в этом причина того что RF, на реальных данных и с осмысленными фичами, показавший себя лучше GradientBoosting, при засланных казачках потерялся и не смог решить заданную ему головоломку. Если помочь RF, и уменьшить число рандомных фичей и использовать порог, то он оживает и показывает вразумительные результаты.
Part 4
Напомню был сгенерирован DateFrame со 100 бессмысленными фичами и одной осмысленной, для проверки могет ML или не могет. Как оказалось GradientalBoosting могет и еще как, RF могет, но хуже. Что покажут нейросети? Нейросетей много, архитектур много, настраивать их не просто, я предложил решить задачу нейросети со следующей архитектурой:
model = Sequential()
model.add(Convolution1D(input_shape = (101, 1),
nb_filter=16,
filter_length=4,
border_mode='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
model.add(Dropout(0.5))
model.add(Convolution1D(nb_filter=8,
filter_length=4,
border_mode='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(64))
model.add(BatchNormalization())
model.add(LeakyReLU())
model.add(Dense(2))
model.add(Activation('softmax'))Тут все как положено — сверточная нейросеть, модная функция активации ReLU, широкой рукой накиданные Dropoutы и BatchNormalization, несколько слоев чтобы похвастаться не просто об обучении, а о глубоком обучении. Обучал на 100, 500 и 1500 эпохах. При увеличении числа эпох росла accuracy на train и на test, далеко превосходя заложенную accuracy ряда. При попытках использовать обученную нейросетку для прогноз получался один большой пфук.
По табличке:
кажется что нейросеть не безнадежна, то где она указывала в прогнозе на событие 1, это событие происходило в 56% случаях, там где предсказала что событие 1 не произойдет, точность составила 55%. Кажется ничего так. Но как мы помним единственная осмысленная фича это Week, и весь юмор ситуации в том что нейросеть строили прогноз на основе махинация с рандомными рядами.
Вот прогноз события 1 с разбивой по Week. Если бы нейросеть сообразила что все дело в этой фиче а остальные просто мусор, то число прогнозов события 1 для week=5 значительно превосходила бы то же самое для остальных значений week, но как мы видим это не так, да их побольше но разве что на чуть чуть. Использование порога в 55% принципиально ничего не поменяло:
Вывод очень простой-мы скормили нейросетке 100 фальшивых фич и 1 реальную. Нейросеть не смогла найти настоящую, вместо этого она с упоением придумала липовые зависимости между фальшивками (причем каким то образом стругая эти зависимости, прогнозы каким то образом оказывались лучше чем простое подбрасывание монетки). То есть можно предположить, что если вы попробуете закинуть в нейросетку много много фичей для прогноза на фондовом рынке, из которых многие не имеют никакого значения, в надежде что нейросетка то разберется, что стоящее, а что мусор, то ничего подобного-нейросетка из многих многих бессмыслиц способна найти псевдо связи, а до той или тех стоящих фичей дало даже не дойдет! Вот вам и наглядная демонстрация почему нейсросетки на фондовом рынке не могут.
Part 5
Продолжу изучение нейросетей. Для тех кто случайно наткнулся на этот пост, но не хочет ковырять предшествующие поясняю.
Был сгенерирована табличка в 50 тысяч строк и 103 столбцов. Один столбец это даты, еще один — таргет, который мы пытаемся предсказать (событие 1 и событие 0). 101 столбец изображают фичи, из которых 100 случайные величины от 1 до 10, а одна осмысленная (Week) принимает значение от 1 до 5. Для week от 1 до 4 равновероятно событие 1 и 2, для Week = 5 вероятность события 1 = 60%, 2 = 40%.
«Шо за фигня аффтор?!». Фигня не фигня, а я моделирую свое виденье рынка и своего подхода к поиску рабочих стратегий. Виденье рынка предполагает что рынок рандомно блуждает значительную часть времени (в моему случаи 80% времени), а оставшееся его можно описать несколькими хорошими фичами. Ну как описать? Не на 100%, ну а где то процентов на 60. Сравните с детерминированным подходом ученых столетней давности — «если нам дать все фичи и много много вычислительных мощностей мы вам все посчитаем, с точностью в 100% и для любого мгновения времени!». Понятно что после этого появилось много других идей, нелинейная динамика к примеру, которая именно предполагает принципиальную невозможность прогнозирования, а не потому что нам чего то в данных недодали. Ну и наконец постановка задачи: у нас есть 101 фича, и нам с помощью инструментов ML надо получить такой прогноз события 1, который бы бился с заложенной нами неэффектиностью. И тут не помогут завывания нейросетей-что мы «фичи кривые заложили, на которых совершенно невозможно работать!», что «просто рынок изменился!, не имезнился мы бы огого!». Нам совершенно плевать на accuracy на трейне и даже на тесте. Мы как тот глупый учитель, который может не очень то и соображает зато у которого на клочке бумажки записан правильный ответ, а напротив него ученик, в очечках, но у которого почему то при всех сплетнях что он в уме может перемножить трехзначные цифры, при сложения 1+1, получается то 5, то 6 то -32. Не, конечно вариант что мальчик в очечках не так уж и не прав возможен, может он считал в невклидовых метриках к примеру, или перемножать он умеет а вот что такое складывание ему просто не сказали.
Ну минута лирики закончилась, что у нас в итоге? В итоге у нас нейросеть совершеннейшим образом облажалась, запутавшись в 100 рандомных фичах и совершенно не заметив ту самую единственную стоящую. Что мы можем? Можем облегчить задачу уменьшив число рандомных фичей со 100 до 10 (10+1) а затем до 2 (2+1), а можно оставить нейросеть наедине со стоящей фичей (0+1), для смеха. А можем дать нейросетке работать не 50 тысячах примерах, а на нескольких миллионах.
Правильный ответ по Week:
Напомню нейросетка 100+1 предсказала событие 1 (с разбивкой по Week) так:
Нейросеть 10+1:
2+1
0+1
По мере уменьшения числа рандомных фичей, результаты типа улучшаются. Уменьшая число рандомных фичей, мы ограничиваем нейросеть в возможности фантазировать в поисках фальшивых закономерностей, и одновременно тыкаем ее носом в правильный ответ. Апофеоз наступает в последним примере. Я не разу не специалист в нейросеть, все это досужие фантазии от меня, но в ироническом стиле опишу как скрипит мозгами нейросеть: «так, мне чего то сунули. таргет, а вот фичи… ой, фича! почему то 1 фича… хмм… к чему бы это?! ну ладно, таргет у нас принимает два значения, причем на выборке событие 1 в 52% случаях. То есть если мы будем постоянно предсказывать событие 1, то у нас будет точность 52%. Ура! ну ладно попробуем что то выжать из фичи чтобы повысить точность....». Вот так я очеловечил рассуждения нейросети, то есть придал ей способность мыслить. А все потому что я заметил одну очень интересную штуку-в последнем примере нейросеть правильно отнесла все Week=5 к событию 1. Но после этого остались week от 1 от 4, и нейросеть могла поровну каждому варианту накидать по событию 1 и событию 2. Но она так не сделала. Она «поняв» что Week=5 дает повышенную вероятность события 1, стала повышать вероятность события 1 для Week=4 и Week=3, как ближе стоящему к Week=5, и уменьшать для Week=1 и Week=2. RF (бустинг) не может экстраполировать, она может только брать примеры из трейни, и осуществлять разбивку, а если на тесте встретить неизвестное из трейни значение фичи, то тупик-с. И разбивку Бустинг осуществил так:
он правильно указал на Week=5, но для него что Week=1, что Week=2, что Week=3, что Week=4 это все одна равновероятная каша, он их не отличает, поэтому он раскидал событие 1 ровненько. А нейросеть так:
и возможно я фантазирую, но тут нейросеть демонстрирует возможности экстраполяции, то есть рассудочной деятельности. Так что получается что бустинг это как калькулятор, который точно посчитает что вам надо, но никаких шаг вправо шаг влево, а нейросети как это как человек-гуманитарий которого попросили на экзамене что то там посчитать. Считать он не умеет, поэтому если ему накидают кучу цифр он запутается, и получит ответ кривой и косой, но так зато у него есть какая никакая логика, суждения, мыслительный процесс, и жизненный опыт он может прикинуться больным или может предположить что «если 5 это хорошо, о все что рядом с 5 тоже неплохо, а вот все что далеко от 5 это не очень». Так что покачиваясь в кресле можно порассуждать на тему «а что то в этих нейросетях есть».
И я опять попробую изобразить как нейросеть рассуждала после того как обнаружила что в week=5 что то есть: «оке, при пятере че то там есть. оке, когда week=5, кинем туда все события 1. ну вот у нас осталось еще куча других примеров, с ними то что делать?! как как раскидать по week&! ааа… ну понятно, что ближе к week=5?! week=4! вот и кинем все оcтальные события 1 в week-4! сколько еще остается событий 1?! 1715 штук! оке, кинем их все в week=3!» Впрочем очень может быть что все это мои больные фантазии
Чувствительность методов ML к размеру обучающей выборки. Part 6
В прошлом тексте я пробовал «помочь», нейросете уменьшив число рандомных фичей. Сейчас попробую помочь увеличив число примеров. Может наша сверточная сеть покажет что то вменяемое если увеличить число примеров до миллиона? Это задача на моем компьютере требует совершенно других затрат времени, так что я вчера запустил машинку обучаться, а сам пошел спать. Обучался на 50 эпохах, увеличивая данные от 10 тысяч до 50 тысяч (увеличивая обьем на 10 тысяч), и от 100 тысяч до 900 тысяч (с шагом +100 тысяч).
Результаты порадовали. Я не буду в 5 раз пересказывать логику «исследования», но убрав week=5 мы должны (ну как должны!? вообще то нам никто ничего не должен) получить равновероятный прогноз события 1 и события 0. Ниже на графике эту норму в 50% изображает серая линия. Красная это прогноз события=1, синяя событие=0, ось Х число примеров на обучающей выборке в тысячах.
И пусть девочка кинет в меня камне если тут нет сходимости.
Но это динамика при увеличении обучающей выборки от 100 тысяч до 900 тысяч, а вот если сюда присовокупить от 10 тысяч до 50, тут все не так очевидно:
У меня следующее обьяснение: нейросеть большая фантазерка, в том смысле что способна найти в числах даже то чего там и нет. Но с другой стороны нельзя сложить из букв «п», «ж», «о», «а» слово вечность, поэтому когда обучающая выборка очень маленькая фантазии нейросети ограниченны. По мере роста обучающей выборки, нейросеть начинает находить все больше и больше черных кошек в черной комнате, которых там нет, и так до размера выборки в 100 тысяч примеров. По мере дальнейшего размера выборки фантазию нейросети начинает ограничивать реальность-сложно аппроксимировать 101 фичей данные размером в сотни тысяч. Ну это ИМХО.
Поставив week = 5 мы должны получить другой тип сходимости. Пробую обьяснить-если нейросеть правильно все разобрала, а именно поняла что единственная значимая фиxа это week и именно при week = 5, то число событий 1 она должна как можно чаще закидывать в week = 5. Смотрим:
Линия обозначает как часто прогнозировалось событие 1 при week=5, видим как по мере увеличения обучающей выборки нейросеть все уверенней делает правильный выбор. Опять зовем девочку готовую кинуть камень, если тут нет сходимости к 100%.
Впрочем у нас есть еще один трюк. Ведь можно с разной долей уверенности делать прогноз. Нейросеть нам одинаково спрогнозирует событие 1, даже если его вероятность она оценивает в 50,0000001% и 55%, но степени уверенности разные. Если поработать не с абсолютными прогнозами а вероятностными вылазит очень много интересных вещей.
Что на 2 таблицах ниже: вероятность это уверенности с какой нейросеть предсказывает событие 1, а столбцы 1,2 ..5 это дни недели. Данные в процентах по строкам. Давайте подумаем. Если нейросетка раскусила что при week=5, вероятность события 1 выше, большей уверенностью предсказывать событие 1 при week=5, а при прочих week она будет сигнализировать о своей неуверенности низкими процентами вероятности.
Первая таблица прогнозы полученные при обучении от 100 тысяч примеров, ниже до 50 тысяч. Видим что размер опять решает-чем лучше мы накормили свою нейросетку, тем лучше она вычленяет week=5. Вверху сеть четко указывает что при уверенности в 50% в своем прогнозе события 1, нейросеть 98% (100% -2%) относит их на week от 1 до 4, в то время как в нижней таблице размытая каша, нейросеть четко не отличает что где, когда и зачем. И если смотреть с другого конца таблиц, например уверенность в 60%: вверху нейросеть уже относит такой уверенный прогноз для week=5 в 90,69% случаях, в то время как скудно обученная нейросеть, опять мнется-у ней week=5 составляет долю всего в 29%.
Как мы можем это использовать? А очень просто, мы говорим-нам не нужны прогнозы если нейросеть сама в них уверенна только на 50% с хвостиком. Мы хотим рассматривать прогнозы только начиная от 55% уверенности. Оке. Выкидываем, получаем для нейросети обученной на выборках от 100 тысяч:
Так какой можно сделать вывод? Нейросети оказались вовсе не так безнадежны, и если им дать обучиться на выборке где то начиная от 200 тысяч примеров, то они начинают сносно выделяют верную фичу из 100 рандомных, показывая при пороге в 55% precision (точность) где то в 57% (при максимуме в 60%) и recall (наполненность) в 90%. До GB не дотягивает, но можно пофантазировать что если взять 2, 3, 10 млн примеров, то нейросеть наконец то все разложит по полочкам.
Для GB я тоже потестил при обучении от 100 до 900 тысяч примеров и сравнил с нейросеткой:
Ну тут все понятно. GB начиная с выборки в 300 тысяч примеров показывает 100% результат: все события 1 кидает в week=5, а для всех остальных раскидывает события поровну, в то время как нейросетка чего то пытается нащупать.
Таки дела
P.S. Отвечая на вопрос в чем вывод: я в процессе, но пока получается вывод такой-для моей постановки задач в трейдинге, нейросети вообще нафиг не нужны. Им нужно кучу данных, они путаются, они нервные как барышни, они фантазерки, придумывают чего нет. А вот RF и GB просты и надежны как калькуляторы. При этом нейросети (теоретически!) не нуждаются в предварительной и очень утомительной работе с фичами, а RF/GB без этого ну никак. И если нейросети реально имеют какой то рассудок, они могут сделать прогноз на основе «творческой» работы с данными, то RF/GB работают в рамках примеров, ни шаг влево ни шаг вправо, никаких экстраполяций. Так что нейросетки действительно могут творить, то чего мы даже не предполагаем и не задумываем… и как знать, может то что нейросетки показывают нам фигу при попытке внедрить их на фондовом рынке, это их сигнал-«бегите безумцы, тут ловить нечего!»
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба