


8 ноября 2021 giovanni1313
Несмотря на десятилетие ярких побед в области искусственного интеллекта, у скептиков всегда есть неотразимый аргумент. И звучит он так: «прошлые результаты не гарантируют будущий успех».
Всё верно — будущее развитие какой угодно технологии невозможно предугадать заранее, и рано или поздно оно тормозится, упираясь в разного рода ограничения. Отталкиваясь от этого, скептики гнут свою линию: глубокое обучение уже сорвало большинство «низковисящих плодов», и скоро, очень скоро нас ждёт очередная ИИ-зима, тупик, разочарование и безысходность.
Сама по себе эта вариация на тему «стакан наполовину пуст» вряд ли заслуживает большого внимания, если вы не придерживаетесь аналогичных взглядов (если придерживаетесь, в игру вступает предвзятость подтверждения). Но среди скептиков есть и те, кто готов подтвердить свою позицию цифрами и фактами. И тут всё становится намного интереснее. Если те самые ограничения в развитии уже можно разглядеть, у нас появляются важные ориентиры того, на что способно и на что неспособно глубокое обучение.
Одна из попыток обосновать свою позицию принадлежит группе американских ученых, Н. Томпсону, К. Гринволду, К. Ли и Г. Мансо. Летом прошлого года они опубликовали статью со своими выкладками на arxiv.org. И недавно решили изложить свои взляды более доступным языком в публикации в IEEE Spectrum.
Одна из главных проблем глубоких нейросетей, которую видят исследователи — их зашкаливающая сложность. Конкретнее, число параметров в модели, которое очень велико. (Тут надо сделать очевидную оговорку, что искусственный интеллект вряд ли возможно уместить в программу той же длины, что и какой-нибудь физзбазз. Сложность — это, скорее всего, необходимое, но недостаточное условие для ИИ).

Ученые отмечают, что гигантское число параметров модели позволяют сделать ее очень гибкой. А гибкость — это неотъемлемое свойство интеллекта. Но у всего этого есть и обратная сторона. Если в активе — мощные, гибкие модели, то в пассиве — гигантские вычислительные затраты.
Все модели машинного обучения основаны на статистических правилах. А статистика неумолима: чтобы улучшить точность модели в n раз, мы должны увеличить обучающую выборку как минимум в n^2 раза.
Однако даже квадратическая зависимость для нейросетей была бы очень оптимистичной оценкой. Увы, гигантское число относительно «свободных» параметров делают ее очень зависимой от большого объема вычислений. Исследователи рассчитали, что для нейросетей теоретическая закономерность выглядит так: чтобы улучшить точность модели в n раз, мы должны увеличить объем вычислений в n^4 раза. Это очень, _очень_ быстрый рост потребности в вычислениях.
Но то статистическая теория. А что мы имеем на практике? Чтобы ответить на этот вопрос, исследователи проштудировали более 1000 научных публикаций, выделяя вычислительные затраты на создание машинных моделей. Например, в бенчмарке на распознавание изображений в 2012 лучшая модель, AlexNet, потребовала в 1000 раз меньше вычислений, чем нейросеть NASNet-A в 2018. При этом точность за 6 лет выросла в 2 раза.
Пример вроде бы очевидный — но по одному примеру выводы делать рано. Собрав данные по всем моделям, исследователи получили не слишком вразумительные диаграммы:
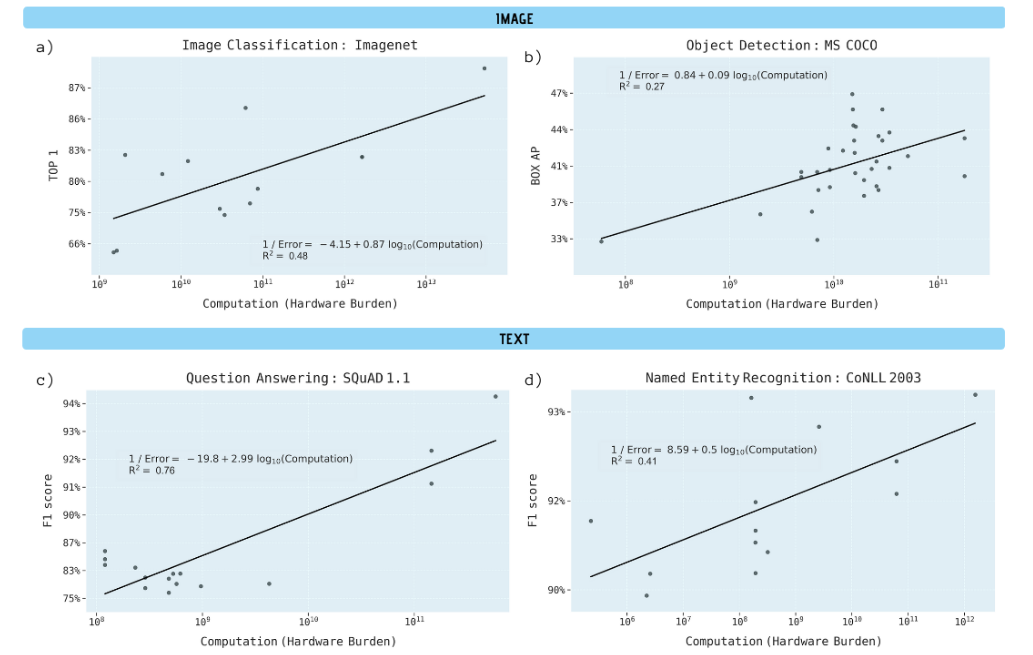
...в которых, тем не менее, удалось найти какой-то статистически значимый тренд. Из тренда следовало, что теоретическая зависимость роста вычислений в n^4 – это очень оптимистичная оценка. В реальности в среднем получалась зависимость n^9 – объём вычислений рос пропорционально девятой степени улучшения точности. Скажем, чтобы точность модели выросла в 2 раза, объем вычислений должен увеличиться в 512 раз.
Это не просто очень много — это _запредельно_ много. Впрочем, исследователи находят здесь небольшой повод для оптимизма. Скорее всего, эта дикая неэффективность означает, что существует определенный резерв для улучшения точности без роста вычислений, за счет каких-то альтернативных техник.
Может быть, нас спасет закон Мура с его экспоненциально увеличивающейся доступностью вычислений? К сожалению, Муру сложно угнаться за аппетитами нейросетей. С 2012 по 2018 эффективность «железа» выросла в 6 раз — по сравнению с 1000-кратным ростом от AlexNet до NASNet-A.
Получается весьма неустойчивая картина, верно? И чтобы понять, куда приведет эта неустойчивость, исследователи начинают экстраполировать найденный тренд.
Шутки шутками, но экстраполяция функций с девятой степенью на самом деле не слишком далеко уходит от этого комикса. Да еще и объект для экстраполяций выбран своеобразный — бенчмарк машинного зрения ImageNet, один из самых популярных в области машинного обучения.
Чтобы снизить ошибку модели (точность категоризации топ-1) в этом бенчмарке до 5%, согласно расчетам, на обучение нужно 10^28 операций с плавающей точкой. Наверняка это число со множеством нулей ничего не скажет рядовому читателю, поэтому авторы кладут на стол климатический аргумент: выбросы СО2 от обучения такой модели эквивалентны выбросам г. Нью-Йорк за месяц. Ну а если даже углекислым газом пронять читателя не удалось, озвучиваются затраты в твердой валюте: 100 миллиардов долларов.
И это действительно запредельно много. Настолько, что ставит крест на практической осуществимости таких моделей. Но не всё так однозначно, как пытаются обрисовать скептики. Давайте добавим в эту картину немножко нюансов.
Самый неоднозначный пункт — выбор экстраполируемой метрики. О том, что бенчмарки машинного обучения являются «вещью-в-себе» и успехи в этих бенчмарках мало что говорят о способностях модели за пределами обучающего датасета, известно уже давно. Проблема считается одной из самых серьезных для области машинного обучения. Степень оптимизации модели под конкретный бенчмарк и масштаб падения точности за его пределами удручающе велики.
Если говорить конкретно про ImageNet, эта любопытная работа показывает глубину проблемы. В ней, в числе прочего, оценивается точность популярных моделей машинного зрения на датасете ImageNetV2 – датасете, созданном с целью репликации оригинального набора изображений, по той же самой методологии. Казалось бы, пошаговая репликация должна создать набор картинок, которые нейросети будут классифицировать ровно с той же точностью, что и оригинальный датасет. Увы, это не так. Модели резко теряют «навыки» во второй версии датасета. У топовой нейросети число ошибок вырастает более чем в 2 раза.

Серая штриховая линия соответствует одинаковой точности в ImageNet и ImageNetV2. У всех нейросетей (обозначены синими и красными кружками) точность в ImageNet существенно выше
В том же исследовании наравне с нейросетями тестируются и люди. Их результаты показывают, что между первой и второй версиями ImageNet на самом деле нет разницы — точность классификации для обоих примерно одинаковая. Но люди дают нам еще одну важную точку отсчета: у 2 из 5 испытуемых точность классификации была ниже 5%. А ведь именно эту «100-миллиардную» цель и пытаются заэкстраполировать Н. Томпсон с коллегами.
Более того, при оценке принималось, что картинка может принадлежать к нескольким классам — важное расхождение с оригинальным форматом ImageNet, где считается, что корректным ответом для каждой картинки является один-единственный класс. Вручную проверив все изображения, эксперты пришли к выводу, что это очень неадекватная предпосылка — 18% изображений можно отнести сразу к нескольким классам.
Что в итоге? Корректность бенчмарка под вопросом. Результат топовой модели в более корректной версии уже составил 95,5% — больше, чем задумывали Томпсон и др. Но этот результат кратно ухудшается, если мы пытаемся поменять датасет на абсолютно аналогичный. Соответственно, точность в ImageNet выглядит как абсолютно оторванная от реальности задача, «сферический бенчмарк в вакууме», который слабо соотносится с настоящим прогрессом в сфере ИИ.

У бенчмарков есть привлекательная сторона: по определению, они дают наглядную и четкую количественную характеристику, которой очень удобно пользоваться. Это удобство и предрасположенность машинного обучения к количественным методам поставили бенчмарки в центр внимания научного сообщества. Но, с учетом перечисленных выше недостатков, они вряд ли годятся на роль значимого ориентира. Особенно если речь идёт о долгосрочных прогнозах.
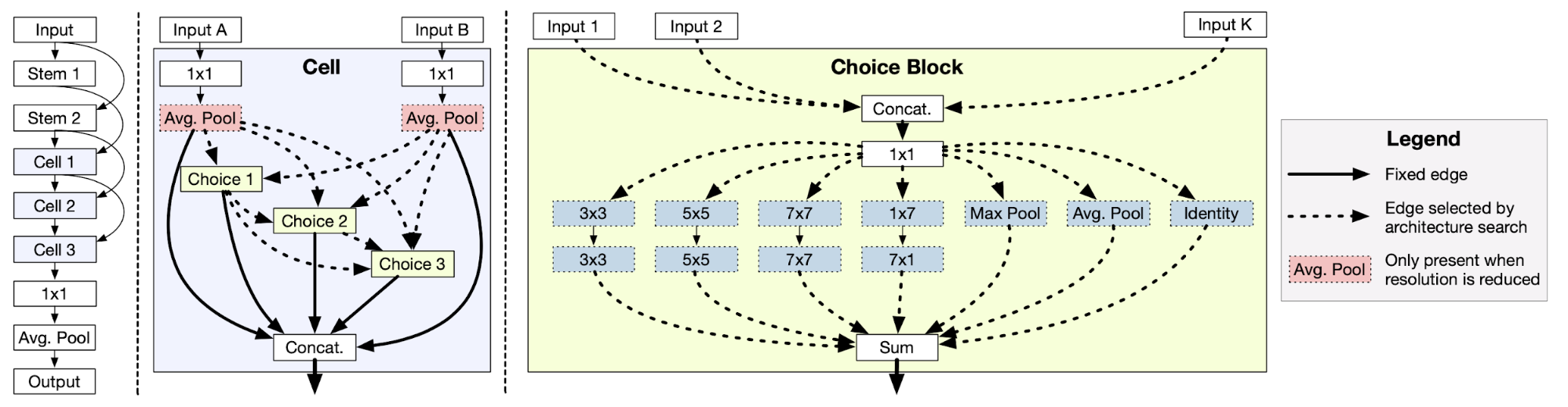
А вот с качественными характеристиками всё выглядит намного интереснее. Хотя, по понятным причинам, неопределенности в интерпретации здесь куда больше, и экстраполяторам они мало что дают. Начнем с NASNet-A, 1000-кратным раздуванием вычислений в которой нас пытаются напугать скептики. NAS в ее названии расшифровывается как Neural Architecture Search – поиск архитектуры нейронной сети.
Важнейшее свойство этого подхода к глубокому обучению — модель самостоятельно создаёт свою структуру. Эта выросшая самостоятельность (и соответствующая ей гибкость) является качественным скачком вперед в создании самообучающихся моделей. И сосредоточенность на количественном бенчмарке (точности работы) игнорирует этот ключевой момент. Поскольку модель создаёт свою структуру методом проб и ошибок, значительно выросший объем вычислений является вполне закономерным «побочным эффектом».
Аналогичный пример — нейросеть AlphaGo Zero. C количественной точки зрения мы увидим, что ее рейтинг ELO вырос на 327 очков по сравнению с предыдущим лидером AlphaGo Master. Но эти цифры игнорируют качественное отличие AlphaGo Zero: нейросеть научилась играть в го самостоятельно, с «чистого листа», без доступа к каким-либо сыгранным человеческим партиям и без прописанной «вручную» эвристики.
Хорошо, пускай качественные прорывы в средствах и методах действительно могут не так бросаться в глаза. Но как можно пропустить качественно новые результаты применения машинных моделей? Возьмем такое важное направление, как алгоритмический поиск лекарственных препаратов. За последние 2 года здесь появилось более десятка перспективных стартапов.
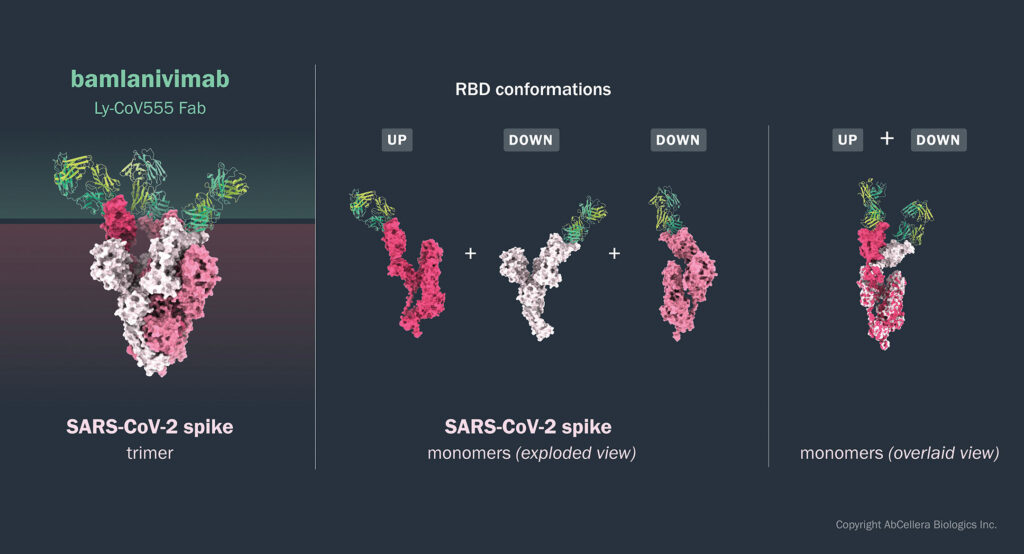
Один из них, «AbCellera» в партнерстве с «Eli Lilly» создал препарат бамланивимаб, ставший первым зарегистрированным средством от COVID-19 с высокой эффективностью. За неполный год он спас около 10 тысяч человек. И вряд ли стоит приводить эти спасенные жизни к тоннам СО2 и куда-то их экстраполировать.
Другой пример качественно новой системы, не укладывающейся в бенчмарки — GPT-3. Её феноменальная универсальность буквально ломает барьеры на пути от глубокого обучения к общему ИИ. GPT-3 – это как раз тот случай, когда модель «аршином общим не измерить»: её способности настолько богаты и глубоки, что любой отдельно взятый тест охватит лишь мизерную их часть.
Так что точность моделей в тесте ImageNet хороша разве что для экстраполяций — но эти экстраполяции мало что скажут о развитии сферы глубокого обучения и о том, как сильно это развитие отразится на нашей жизни.
Тем не менее, покритиковав выбранную скептиками цель, мы не можем оспорить выделенный ими тренд. Действительно, создание моделей глубокого обучения требует всё больше ресурсов — вычислительных и финансовых. Аппетиты нейросетей растут. Работа вычислительных устройств для создания упомянутой выше AlphaGo Zero стоила примерно 35 млн. долларов. Для создания GPT-3 — более 4 млн. долларов.

Десятки миллионов долларов — это уже та планка, которую трудно преодолеть большинству исследовательских университетов и стартапов. И даже для топовых лабораторий ценник становится «кусачим». Когда в алгоритме для GPT-3 уже после обучения обнаружилась ошибка, команда решила не переделывать всё по новой: удвоение расходов уже не вписывалось в бюджет.
Тот факт, что большое число исследователей оказываются отрезанными от “bleeding edge” высокими финансовыми издержками, уже должен негативно повлиять на количество прорывных находок. Происходит анти-демократизация этого направления: помимо светлой головы и смелых идей для прорывов нужно всё больше и больше ресурсов.
Возможно, этот негативный тренд отчасти компенсируется растущей коммерциализацией глубокого обучения. Расширяющееся принятие технологии бизнесом увеличивает и число специалистов, работающих над теми или иными проблемами, и бюджеты на создание машинных моделей.
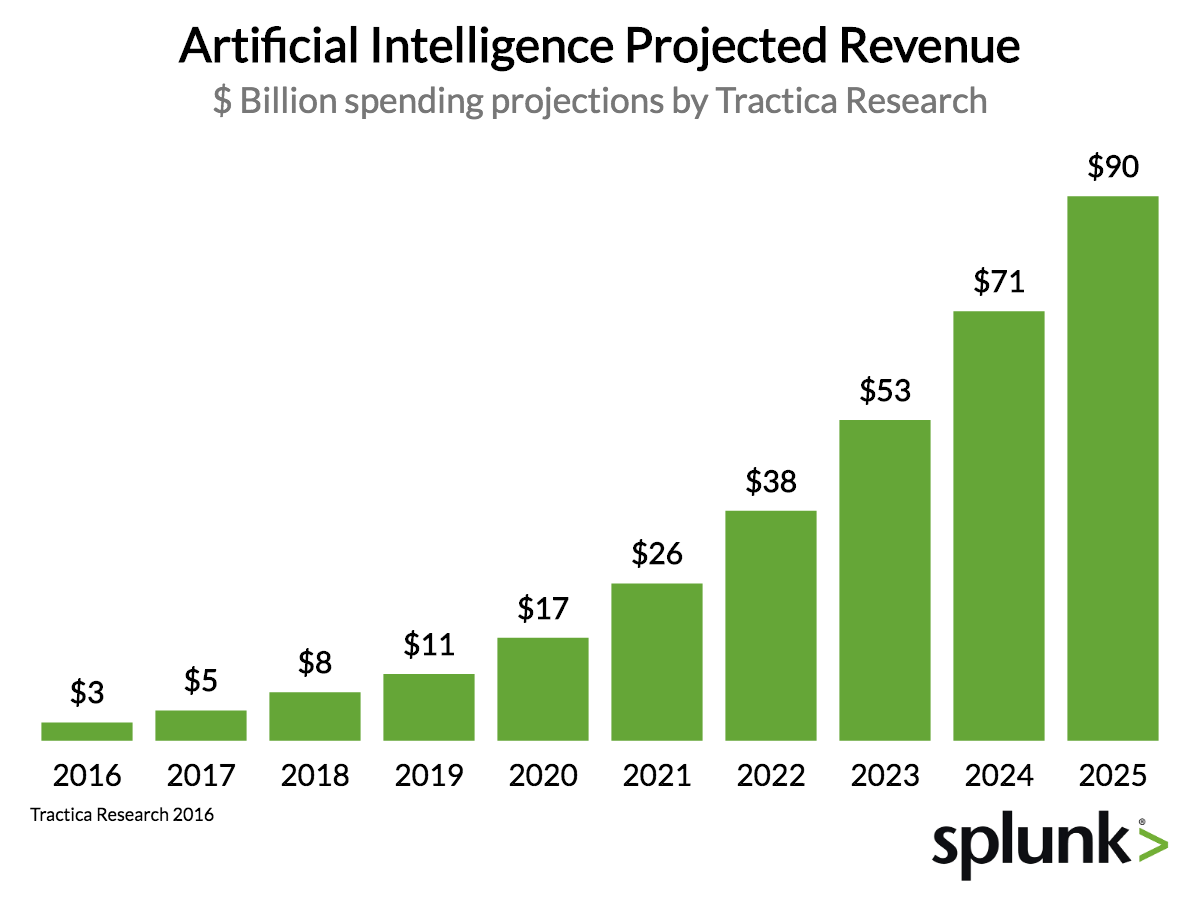
В бизнесе еще остается пространство для роста расходов на отдельный проект. Десятки миллионов долларов — это не самые большие деньги по меркам нынешних корпораций. Если мы посмотрим на предельные размеры бюджета для создания того или иного продукта, то они достигают нескольких миллиардов долларов. Например, на американском фармацевтическом рынке средняя стоимость разработки нового препарата составляет 1,3 млрд. долларов. Изредка мы можем видеть и более крупные суммы — например, разработка 787 «Боинга» стоила компании 15 млрд. долларов — но это скорее исключения, характерные для стабильных низкоконкурентных рынков и усугубленные непредвиденными проблемами.
И здесь нам стоит опять вернуться к экстраполяциям. Исследователи постулируют, что вычислительные «аппетиты» моделей растут со скоростью примерно х10 в год. С поправкой на выигрыш, который давал в последние годы закон Мура, стоимость вычислений будет расти со скоростью х8 в год.
Если мы предположим, что в 2021 году обучение топовой модели стоит 10 млн. долларов, то с таким разрастанием аппетитов затраты на ”state-of-the-art” уже на рубеже 2023/24 годов превысят миллиард долларов! Другими словами, прежний — сногсшибательный — темп прогресса, где прорывы следовали за прорывами, мы можем поддерживать еще 2-3 года. Дальше возможностей для экстенсивного роста уже не будет. По крайней мере, если экстраполировать сегодняшние возможности.
И это означает тупик? В какой-то степени. Скорее правильно сравнить это со стеной, в которую упрется нынешний подход к глубокому обучению. Стеной, которую так или иначе надо преодолеть. И здесь возможны различные варианты.
Сначала посмотрим на те, что кажутся неперспективными. Один из них — фокус на вычислительных затратах, возникающих в процессе работы нейросети (в противоположность затратам, возникающим на этапе обучения). Безусловно, это даст большую экономию, если созданная нейросеть будет интенсивно эксплуатироваться. Но оптимизация сама по себе может быть вычислительно затратным процессом. И фундаментального снижения это не даст. Более того, такой подход ориентирован на создание моделей-«рабочих лошадок», а не на прорывные результаты.
Другой подход, в теории обещающий грандиозные возможности и путь к общему ИИ — мета-обучение. Говоря простым языком, такие модели учатся учиться: приобретают способность извлекать новые знания и подстраиваться под новые задачи. Красивая идея — но на практике нынешний уровень таких алгоритмов очень слаб. И перед этим направлением стоит своя стена, которая может оказаться еще выше, чем в случае вычислительных лимитов глубокого обучения.
Еще одно направление — оптимизация «хардвера», вычислительных устройств. На открытом рынке до сих пор доминируют ускорители компании «Нвидиа», которая за 9 лет развития глубокого обучения так и не удосужилась создать глубоко оптимизированное устройство для дата-центров.
Здесь есть некоторый резерв — но в рамках классических полупроводниковых технологий этот резерв исчерпается довольно быстро. Тем не менее, на «хардверном» направлении всё-таки светит лучик надежды. Он связан с новыми типами устройств, среди которых я бы хотел особо выделить аналоговые оптические вычисления. Здесь мы можем найти приёмы, которые исключительно хорошо сочетаются с вычислительными потребностями нейросетей. Более того, в теории эти приёмы масштабируются гораздо лучше, чем традиционные логические кремниевые микросхемы.
Это даёт нам шанс ускорить бонус от закона Мура. Вернее, получить новый закон, который назовут именем уже современного инженера. Если закон Мура в лучшие годы удешевлял вычисления вдвое за 18 месяцев, то фотоника для нейросетей вполне может дать квадратическое улучшение: в 4 раза за те же 1,5 года.
Ключевой вопрос: успеют ли наиболее перспективные концепты фотоники выйти из лабораторий к тому моменту, как глубокое обучение упрется в стену? Единственный близкий к коммерциализации стартап в этой сфере - ”Lightmatter”. Он обещает выпустить свой сервер, готовый побороться с доминированием «Нвидиа», в 2022 году. Однако, несмотря на то, что по характеристикам ускоритель ”Lightmatter” превосходит решение «Нвидиа», в нем используются далеко не самые прорывные идеи.
Производительность чипа ”Lightmatter” находится примерно на уровне лучших кремниевых ИИ-ускорителей. Но для того, чтобы запустить новый аналог закона Мура, фотоника должна продемонстрировать безусловное преимущество над транзисторами. Удастся ли ей это сделать в ближайшие несколько лет? Пока на этот вопрос не могут ответить даже сами разработчики.
Если на этом пути возникнут проблемы, у нас остается еще несколько вариантов: мемристоры, квантовые вычисления, аналоговые вычисления на неоптических принципах, нейроморфные архитектуры и некоторые другие. Все они выглядят не такими сильными по сравнению с фотоникой: где-то (как в квантовых вычислениях) технологии делают только первые шаги, где-то (как с нейроморфными архитектурами) красивая теория не даёт никакой практической выгоды. Шансы, что в ближайшие годы какое-то из этих направлений спасёт глубокое обучение, не так велики — впрочем, в более далеком будущем и здесь есть потенциал для революционных прорывов.
Но главный потенциал для прорывов заключен всё-таки в смене самой парадигмы глубокого обучения. В том, что на смену этому прожорливому и неэффективному методу придут другие, более изящные, быстрые и мощные.
Метод обратного распространения ошибок, являющийся фундаментальной основой глубокого обучения, укладывается в 6 строчек кода и, с позиций сегодняшнего дня, кажется чуть ли не самоочевидным. Но за 36 лет, прошедшие с того момента, как мы начали его использовать, мы так и не смогли найти лучшей альтернативы — несмотря на всю его примитивность. Тем не менее, эта примитивность говорит о том, что планка довольно низка и что лучшие альтернативы, скорее всего, достижимы.

Прогресс в ИИ не заканчивается с торможением в области глубокого обучения. Это та ступенька, на которой мы стоим сейчас — но она ведёт к новым методам и новым высотам.
Невозможно проэкстраполировать, когда будут открыты новые пути. И здесь мы можем развернуть «скептический» тезис на 180 градусов: прошлые бесплодные результаты не гарантируют, что мы потерпим неудачу. Тем более, поиск явно активизируется, когда глубокое обучение упрется в «стену». В числе перспективных методов Н. Томпсон с коллегами называет нейросимволическе модели; есть и другие интересные идеи.
Но разговор о новых путях возвращает нас к вопросу о качественном росте в самом направлении глубокого обучения. Его тоже невозможно проэкстраполировать — однако до сих пор он радовал, удивлял и даже восхищал нас гораздо больше, чем количественный прогресс в бенчмарках. Узкая специализация нейросетей позволяет неожиданно оптимистичную интерпретацию: даже достижение «потолка» в количестве параметров не отменяет нахождения новых ниш и новых решений в самых разнообразных областях.
Пожалуй, на сегодня это является самым надежным «козырем» глубокого обучения, самым мощным источником его потенциала. Ограничений для роста «вширь» гораздо меньше, чем для роста «вверх». А значит, хоронить глубокое обучение еще рано. Пока мы не найдём ему достойную замену.
Всё верно — будущее развитие какой угодно технологии невозможно предугадать заранее, и рано или поздно оно тормозится, упираясь в разного рода ограничения. Отталкиваясь от этого, скептики гнут свою линию: глубокое обучение уже сорвало большинство «низковисящих плодов», и скоро, очень скоро нас ждёт очередная ИИ-зима, тупик, разочарование и безысходность.
Сама по себе эта вариация на тему «стакан наполовину пуст» вряд ли заслуживает большого внимания, если вы не придерживаетесь аналогичных взглядов (если придерживаетесь, в игру вступает предвзятость подтверждения). Но среди скептиков есть и те, кто готов подтвердить свою позицию цифрами и фактами. И тут всё становится намного интереснее. Если те самые ограничения в развитии уже можно разглядеть, у нас появляются важные ориентиры того, на что способно и на что неспособно глубокое обучение.
Одна из попыток обосновать свою позицию принадлежит группе американских ученых, Н. Томпсону, К. Гринволду, К. Ли и Г. Мансо. Летом прошлого года они опубликовали статью со своими выкладками на arxiv.org. И недавно решили изложить свои взляды более доступным языком в публикации в IEEE Spectrum.
Одна из главных проблем глубоких нейросетей, которую видят исследователи — их зашкаливающая сложность. Конкретнее, число параметров в модели, которое очень велико. (Тут надо сделать очевидную оговорку, что искусственный интеллект вряд ли возможно уместить в программу той же длины, что и какой-нибудь физзбазз. Сложность — это, скорее всего, необходимое, но недостаточное условие для ИИ).
Ученые отмечают, что гигантское число параметров модели позволяют сделать ее очень гибкой. А гибкость — это неотъемлемое свойство интеллекта. Но у всего этого есть и обратная сторона. Если в активе — мощные, гибкие модели, то в пассиве — гигантские вычислительные затраты.
Все модели машинного обучения основаны на статистических правилах. А статистика неумолима: чтобы улучшить точность модели в n раз, мы должны увеличить обучающую выборку как минимум в n^2 раза.
Однако даже квадратическая зависимость для нейросетей была бы очень оптимистичной оценкой. Увы, гигантское число относительно «свободных» параметров делают ее очень зависимой от большого объема вычислений. Исследователи рассчитали, что для нейросетей теоретическая закономерность выглядит так: чтобы улучшить точность модели в n раз, мы должны увеличить объем вычислений в n^4 раза. Это очень, _очень_ быстрый рост потребности в вычислениях.
Но то статистическая теория. А что мы имеем на практике? Чтобы ответить на этот вопрос, исследователи проштудировали более 1000 научных публикаций, выделяя вычислительные затраты на создание машинных моделей. Например, в бенчмарке на распознавание изображений в 2012 лучшая модель, AlexNet, потребовала в 1000 раз меньше вычислений, чем нейросеть NASNet-A в 2018. При этом точность за 6 лет выросла в 2 раза.
Пример вроде бы очевидный — но по одному примеру выводы делать рано. Собрав данные по всем моделям, исследователи получили не слишком вразумительные диаграммы:
...в которых, тем не менее, удалось найти какой-то статистически значимый тренд. Из тренда следовало, что теоретическая зависимость роста вычислений в n^4 – это очень оптимистичная оценка. В реальности в среднем получалась зависимость n^9 – объём вычислений рос пропорционально девятой степени улучшения точности. Скажем, чтобы точность модели выросла в 2 раза, объем вычислений должен увеличиться в 512 раз.
Это не просто очень много — это _запредельно_ много. Впрочем, исследователи находят здесь небольшой повод для оптимизма. Скорее всего, эта дикая неэффективность означает, что существует определенный резерв для улучшения точности без роста вычислений, за счет каких-то альтернативных техник.
Может быть, нас спасет закон Мура с его экспоненциально увеличивающейся доступностью вычислений? К сожалению, Муру сложно угнаться за аппетитами нейросетей. С 2012 по 2018 эффективность «железа» выросла в 6 раз — по сравнению с 1000-кратным ростом от AlexNet до NASNet-A.
Получается весьма неустойчивая картина, верно? И чтобы понять, куда приведет эта неустойчивость, исследователи начинают экстраполировать найденный тренд.
Шутки шутками, но экстраполяция функций с девятой степенью на самом деле не слишком далеко уходит от этого комикса. Да еще и объект для экстраполяций выбран своеобразный — бенчмарк машинного зрения ImageNet, один из самых популярных в области машинного обучения.
[img]https://spectrum.ieee.org/media-library/a-chart-with-an-arrow-going-down-to-the-right.png?id=27527417&width=768&quality=80[/img]
Чтобы снизить ошибку модели (точность категоризации топ-1) в этом бенчмарке до 5%, согласно расчетам, на обучение нужно 10^28 операций с плавающей точкой. Наверняка это число со множеством нулей ничего не скажет рядовому читателю, поэтому авторы кладут на стол климатический аргумент: выбросы СО2 от обучения такой модели эквивалентны выбросам г. Нью-Йорк за месяц. Ну а если даже углекислым газом пронять читателя не удалось, озвучиваются затраты в твердой валюте: 100 миллиардов долларов.
[img]https://spectrum.ieee.org/media-library/a-chart-showing-computations-billions-of-floating-point-operations.png?id=27527446&width=768&quality=80[/img]
И это действительно запредельно много. Настолько, что ставит крест на практической осуществимости таких моделей. Но не всё так однозначно, как пытаются обрисовать скептики. Давайте добавим в эту картину немножко нюансов.
Самый неоднозначный пункт — выбор экстраполируемой метрики. О том, что бенчмарки машинного обучения являются «вещью-в-себе» и успехи в этих бенчмарках мало что говорят о способностях модели за пределами обучающего датасета, известно уже давно. Проблема считается одной из самых серьезных для области машинного обучения. Степень оптимизации модели под конкретный бенчмарк и масштаб падения точности за его пределами удручающе велики.
Если говорить конкретно про ImageNet, эта любопытная работа показывает глубину проблемы. В ней, в числе прочего, оценивается точность популярных моделей машинного зрения на датасете ImageNetV2 – датасете, созданном с целью репликации оригинального набора изображений, по той же самой методологии. Казалось бы, пошаговая репликация должна создать набор картинок, которые нейросети будут классифицировать ровно с той же точностью, что и оригинальный датасет. Увы, это не так. Модели резко теряют «навыки» во второй версии датасета. У топовой нейросети число ошибок вырастает более чем в 2 раза.
Серая штриховая линия соответствует одинаковой точности в ImageNet и ImageNetV2. У всех нейросетей (обозначены синими и красными кружками) точность в ImageNet существенно выше
В том же исследовании наравне с нейросетями тестируются и люди. Их результаты показывают, что между первой и второй версиями ImageNet на самом деле нет разницы — точность классификации для обоих примерно одинаковая. Но люди дают нам еще одну важную точку отсчета: у 2 из 5 испытуемых точность классификации была ниже 5%. А ведь именно эту «100-миллиардную» цель и пытаются заэкстраполировать Н. Томпсон с коллегами.
Более того, при оценке принималось, что картинка может принадлежать к нескольким классам — важное расхождение с оригинальным форматом ImageNet, где считается, что корректным ответом для каждой картинки является один-единственный класс. Вручную проверив все изображения, эксперты пришли к выводу, что это очень неадекватная предпосылка — 18% изображений можно отнести сразу к нескольким классам.
Что в итоге? Корректность бенчмарка под вопросом. Результат топовой модели в более корректной версии уже составил 95,5% — больше, чем задумывали Томпсон и др. Но этот результат кратно ухудшается, если мы пытаемся поменять датасет на абсолютно аналогичный. Соответственно, точность в ImageNet выглядит как абсолютно оторванная от реальности задача, «сферический бенчмарк в вакууме», который слабо соотносится с настоящим прогрессом в сфере ИИ.
У бенчмарков есть привлекательная сторона: по определению, они дают наглядную и четкую количественную характеристику, которой очень удобно пользоваться. Это удобство и предрасположенность машинного обучения к количественным методам поставили бенчмарки в центр внимания научного сообщества. Но, с учетом перечисленных выше недостатков, они вряд ли годятся на роль значимого ориентира. Особенно если речь идёт о долгосрочных прогнозах.
А вот с качественными характеристиками всё выглядит намного интереснее. Хотя, по понятным причинам, неопределенности в интерпретации здесь куда больше, и экстраполяторам они мало что дают. Начнем с NASNet-A, 1000-кратным раздуванием вычислений в которой нас пытаются напугать скептики. NAS в ее названии расшифровывается как Neural Architecture Search – поиск архитектуры нейронной сети.
Важнейшее свойство этого подхода к глубокому обучению — модель самостоятельно создаёт свою структуру. Эта выросшая самостоятельность (и соответствующая ей гибкость) является качественным скачком вперед в создании самообучающихся моделей. И сосредоточенность на количественном бенчмарке (точности работы) игнорирует этот ключевой момент. Поскольку модель создаёт свою структуру методом проб и ошибок, значительно выросший объем вычислений является вполне закономерным «побочным эффектом».
Аналогичный пример — нейросеть AlphaGo Zero. C количественной точки зрения мы увидим, что ее рейтинг ELO вырос на 327 очков по сравнению с предыдущим лидером AlphaGo Master. Но эти цифры игнорируют качественное отличие AlphaGo Zero: нейросеть научилась играть в го самостоятельно, с «чистого листа», без доступа к каким-либо сыгранным человеческим партиям и без прописанной «вручную» эвристики.
Хорошо, пускай качественные прорывы в средствах и методах действительно могут не так бросаться в глаза. Но как можно пропустить качественно новые результаты применения машинных моделей? Возьмем такое важное направление, как алгоритмический поиск лекарственных препаратов. За последние 2 года здесь появилось более десятка перспективных стартапов.
Один из них, «AbCellera» в партнерстве с «Eli Lilly» создал препарат бамланивимаб, ставший первым зарегистрированным средством от COVID-19 с высокой эффективностью. За неполный год он спас около 10 тысяч человек. И вряд ли стоит приводить эти спасенные жизни к тоннам СО2 и куда-то их экстраполировать.
Другой пример качественно новой системы, не укладывающейся в бенчмарки — GPT-3. Её феноменальная универсальность буквально ломает барьеры на пути от глубокого обучения к общему ИИ. GPT-3 – это как раз тот случай, когда модель «аршином общим не измерить»: её способности настолько богаты и глубоки, что любой отдельно взятый тест охватит лишь мизерную их часть.
Так что точность моделей в тесте ImageNet хороша разве что для экстраполяций — но эти экстраполяции мало что скажут о развитии сферы глубокого обучения и о том, как сильно это развитие отразится на нашей жизни.
Тем не менее, покритиковав выбранную скептиками цель, мы не можем оспорить выделенный ими тренд. Действительно, создание моделей глубокого обучения требует всё больше ресурсов — вычислительных и финансовых. Аппетиты нейросетей растут. Работа вычислительных устройств для создания упомянутой выше AlphaGo Zero стоила примерно 35 млн. долларов. Для создания GPT-3 — более 4 млн. долларов.
Десятки миллионов долларов — это уже та планка, которую трудно преодолеть большинству исследовательских университетов и стартапов. И даже для топовых лабораторий ценник становится «кусачим». Когда в алгоритме для GPT-3 уже после обучения обнаружилась ошибка, команда решила не переделывать всё по новой: удвоение расходов уже не вписывалось в бюджет.
Тот факт, что большое число исследователей оказываются отрезанными от “bleeding edge” высокими финансовыми издержками, уже должен негативно повлиять на количество прорывных находок. Происходит анти-демократизация этого направления: помимо светлой головы и смелых идей для прорывов нужно всё больше и больше ресурсов.
Возможно, этот негативный тренд отчасти компенсируется растущей коммерциализацией глубокого обучения. Расширяющееся принятие технологии бизнесом увеличивает и число специалистов, работающих над теми или иными проблемами, и бюджеты на создание машинных моделей.
В бизнесе еще остается пространство для роста расходов на отдельный проект. Десятки миллионов долларов — это не самые большие деньги по меркам нынешних корпораций. Если мы посмотрим на предельные размеры бюджета для создания того или иного продукта, то они достигают нескольких миллиардов долларов. Например, на американском фармацевтическом рынке средняя стоимость разработки нового препарата составляет 1,3 млрд. долларов. Изредка мы можем видеть и более крупные суммы — например, разработка 787 «Боинга» стоила компании 15 млрд. долларов — но это скорее исключения, характерные для стабильных низкоконкурентных рынков и усугубленные непредвиденными проблемами.
И здесь нам стоит опять вернуться к экстраполяциям. Исследователи постулируют, что вычислительные «аппетиты» моделей растут со скоростью примерно х10 в год. С поправкой на выигрыш, который давал в последние годы закон Мура, стоимость вычислений будет расти со скоростью х8 в год.
Если мы предположим, что в 2021 году обучение топовой модели стоит 10 млн. долларов, то с таким разрастанием аппетитов затраты на ”state-of-the-art” уже на рубеже 2023/24 годов превысят миллиард долларов! Другими словами, прежний — сногсшибательный — темп прогресса, где прорывы следовали за прорывами, мы можем поддерживать еще 2-3 года. Дальше возможностей для экстенсивного роста уже не будет. По крайней мере, если экстраполировать сегодняшние возможности.
И это означает тупик? В какой-то степени. Скорее правильно сравнить это со стеной, в которую упрется нынешний подход к глубокому обучению. Стеной, которую так или иначе надо преодолеть. И здесь возможны различные варианты.
Сначала посмотрим на те, что кажутся неперспективными. Один из них — фокус на вычислительных затратах, возникающих в процессе работы нейросети (в противоположность затратам, возникающим на этапе обучения). Безусловно, это даст большую экономию, если созданная нейросеть будет интенсивно эксплуатироваться. Но оптимизация сама по себе может быть вычислительно затратным процессом. И фундаментального снижения это не даст. Более того, такой подход ориентирован на создание моделей-«рабочих лошадок», а не на прорывные результаты.
Другой подход, в теории обещающий грандиозные возможности и путь к общему ИИ — мета-обучение. Говоря простым языком, такие модели учатся учиться: приобретают способность извлекать новые знания и подстраиваться под новые задачи. Красивая идея — но на практике нынешний уровень таких алгоритмов очень слаб. И перед этим направлением стоит своя стена, которая может оказаться еще выше, чем в случае вычислительных лимитов глубокого обучения.
Еще одно направление — оптимизация «хардвера», вычислительных устройств. На открытом рынке до сих пор доминируют ускорители компании «Нвидиа», которая за 9 лет развития глубокого обучения так и не удосужилась создать глубоко оптимизированное устройство для дата-центров.
Здесь есть некоторый резерв — но в рамках классических полупроводниковых технологий этот резерв исчерпается довольно быстро. Тем не менее, на «хардверном» направлении всё-таки светит лучик надежды. Он связан с новыми типами устройств, среди которых я бы хотел особо выделить аналоговые оптические вычисления. Здесь мы можем найти приёмы, которые исключительно хорошо сочетаются с вычислительными потребностями нейросетей. Более того, в теории эти приёмы масштабируются гораздо лучше, чем традиционные логические кремниевые микросхемы.
[img]https://i1.wp.com/silvertonconsulting.com/blog/wp-content/uploads/2019/06/Screen-Shot-2019-06-11-at-9.52.52-AM.png?w=640&ssl=1[/img]
Это даёт нам шанс ускорить бонус от закона Мура. Вернее, получить новый закон, который назовут именем уже современного инженера. Если закон Мура в лучшие годы удешевлял вычисления вдвое за 18 месяцев, то фотоника для нейросетей вполне может дать квадратическое улучшение: в 4 раза за те же 1,5 года.
Ключевой вопрос: успеют ли наиболее перспективные концепты фотоники выйти из лабораторий к тому моменту, как глубокое обучение упрется в стену? Единственный близкий к коммерциализации стартап в этой сфере - ”Lightmatter”. Он обещает выпустить свой сервер, готовый побороться с доминированием «Нвидиа», в 2022 году. Однако, несмотря на то, что по характеристикам ускоритель ”Lightmatter” превосходит решение «Нвидиа», в нем используются далеко не самые прорывные идеи.
Производительность чипа ”Lightmatter” находится примерно на уровне лучших кремниевых ИИ-ускорителей. Но для того, чтобы запустить новый аналог закона Мура, фотоника должна продемонстрировать безусловное преимущество над транзисторами. Удастся ли ей это сделать в ближайшие несколько лет? Пока на этот вопрос не могут ответить даже сами разработчики.
Если на этом пути возникнут проблемы, у нас остается еще несколько вариантов: мемристоры, квантовые вычисления, аналоговые вычисления на неоптических принципах, нейроморфные архитектуры и некоторые другие. Все они выглядят не такими сильными по сравнению с фотоникой: где-то (как в квантовых вычислениях) технологии делают только первые шаги, где-то (как с нейроморфными архитектурами) красивая теория не даёт никакой практической выгоды. Шансы, что в ближайшие годы какое-то из этих направлений спасёт глубокое обучение, не так велики — впрочем, в более далеком будущем и здесь есть потенциал для революционных прорывов.
Но главный потенциал для прорывов заключен всё-таки в смене самой парадигмы глубокого обучения. В том, что на смену этому прожорливому и неэффективному методу придут другие, более изящные, быстрые и мощные.
Метод обратного распространения ошибок, являющийся фундаментальной основой глубокого обучения, укладывается в 6 строчек кода и, с позиций сегодняшнего дня, кажется чуть ли не самоочевидным. Но за 36 лет, прошедшие с того момента, как мы начали его использовать, мы так и не смогли найти лучшей альтернативы — несмотря на всю его примитивность. Тем не менее, эта примитивность говорит о том, что планка довольно низка и что лучшие альтернативы, скорее всего, достижимы.
Прогресс в ИИ не заканчивается с торможением в области глубокого обучения. Это та ступенька, на которой мы стоим сейчас — но она ведёт к новым методам и новым высотам.
Невозможно проэкстраполировать, когда будут открыты новые пути. И здесь мы можем развернуть «скептический» тезис на 180 градусов: прошлые бесплодные результаты не гарантируют, что мы потерпим неудачу. Тем более, поиск явно активизируется, когда глубокое обучение упрется в «стену». В числе перспективных методов Н. Томпсон с коллегами называет нейросимволическе модели; есть и другие интересные идеи.
Но разговор о новых путях возвращает нас к вопросу о качественном росте в самом направлении глубокого обучения. Его тоже невозможно проэкстраполировать — однако до сих пор он радовал, удивлял и даже восхищал нас гораздо больше, чем количественный прогресс в бенчмарках. Узкая специализация нейросетей позволяет неожиданно оптимистичную интерпретацию: даже достижение «потолка» в количестве параметров не отменяет нахождения новых ниш и новых решений в самых разнообразных областях.
Пожалуй, на сегодня это является самым надежным «козырем» глубокого обучения, самым мощным источником его потенциала. Ограничений для роста «вширь» гораздо меньше, чем для роста «вверх». А значит, хоронить глубокое обучение еще рано. Пока мы не найдём ему достойную замену.
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба