


18 марта 2022 ForkLog
Компания Google и Калифорнийский университет в Беркли создали алгоритм глубокого обучения PRIME, помогающий разрабатывать быстрые и компактные процессоры для обработки задач искусственного интеллекта.
Новый подход создает архитектуру ИИ-чипов на основе существующих чертежей и показателей производительности.
Команда заявила, что сделанные по методу PRIME-конструкции чипы имеют задержку до 50% меньше, чем созданные с использованием классических подходов. Глубокое обучение также позволило сократить время для создания чертежей до 99%.
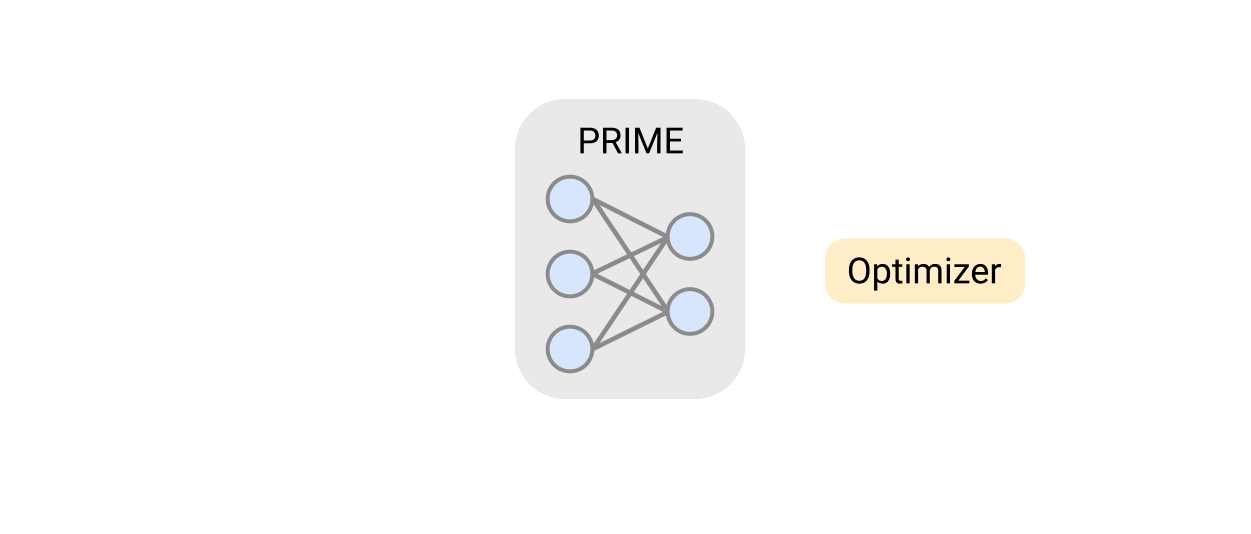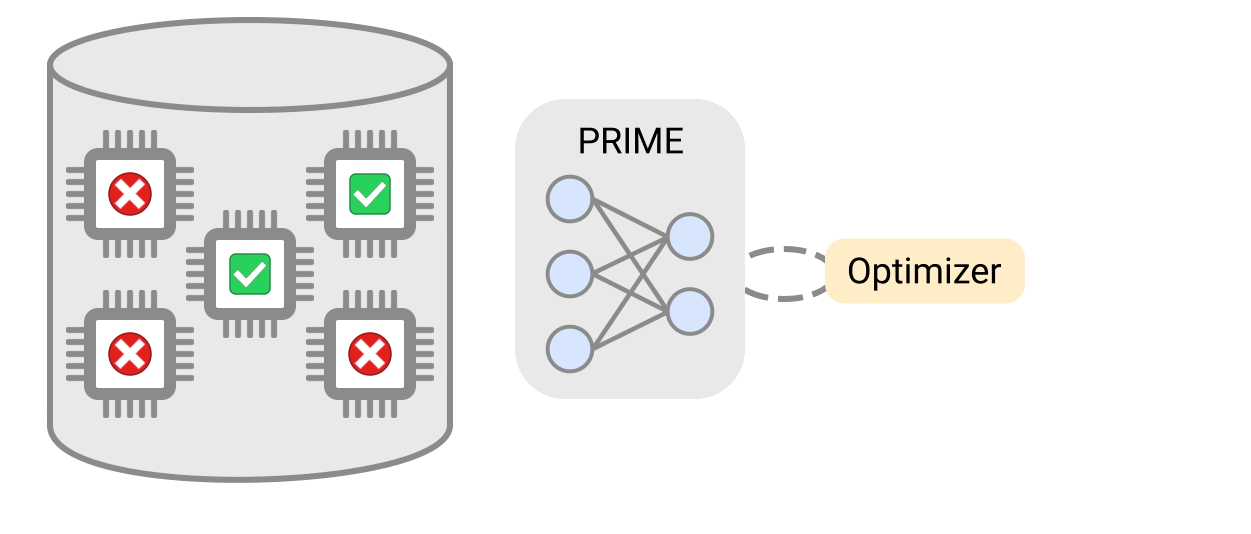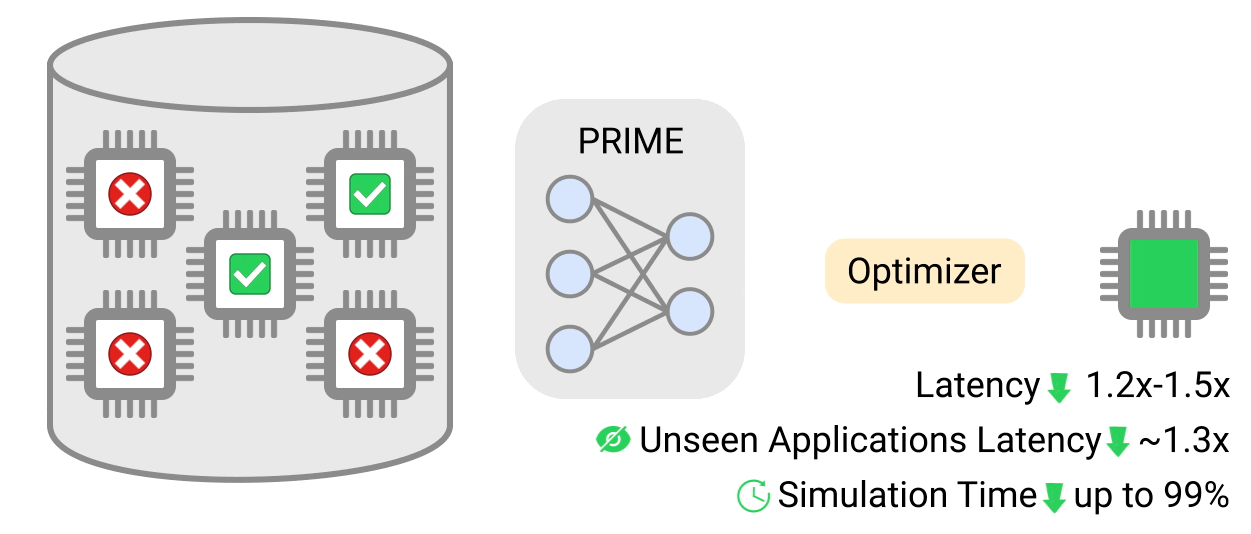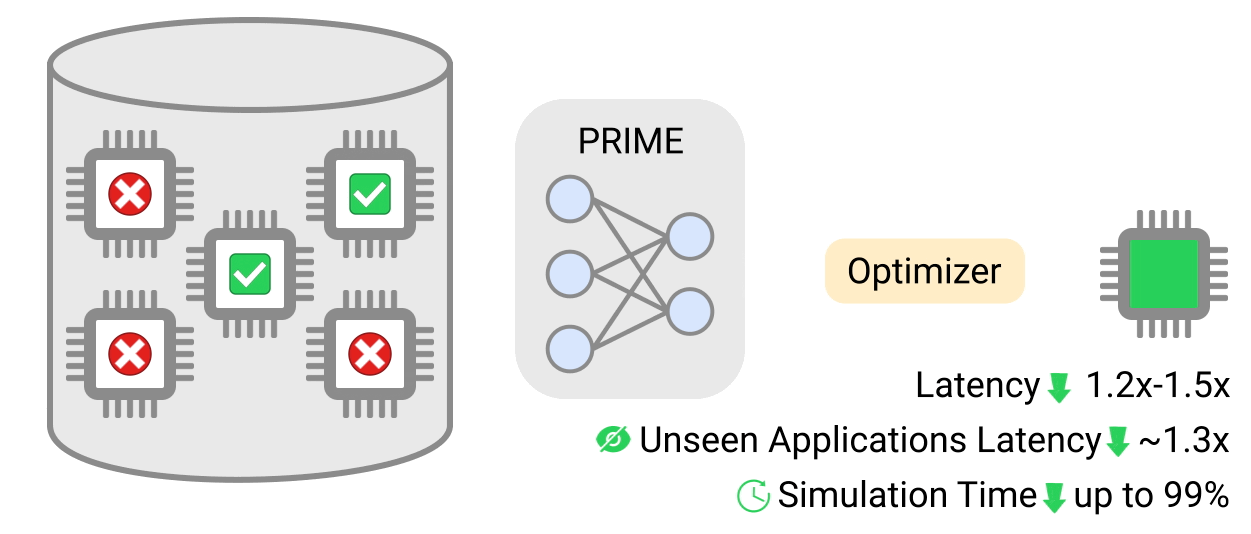
Работа алгоритма PRIME. Данные: Google.
Исследователи сравнили производительность чипов, созданных PRIME, с ускорителями EdgeTPU в девяти ИИ-приложениях, включая модели классификации изображений MobileNetV2 и MobileNetEdge. Они подчеркнули, что конструкции были оптимизированы для каждого приложения.
Подход PRIME улучшил задержку в 2,7 раза и уменьшил площадь кристалла в 1,5 раза. Это позволит удешевить чипы и снизить энергопотребление, заявили ученые.
Кроме этого, производительность чипов, созданных с помощью ИИ, оказалась выше во всех девяти приложениях, участвовавших в эксперименте. Всего три из них имели более высокую задержку в сравнении с конструкциями, созданных с помощью моделирования.
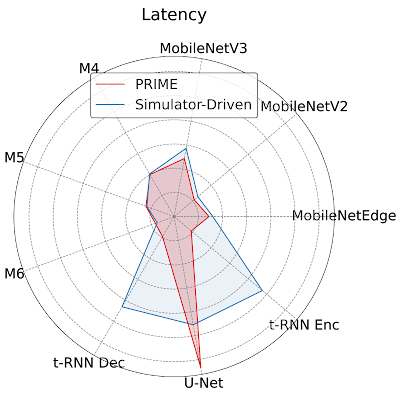
Сравнение задержки при тестировании девяти приложений (меньше — лучше). Данные: Google.
По словам исследователей, PRIME имеет многообещающие перспективы. Это включает в себя создание микросхем для приложений, требующих решения сложных задач оптимизации, а также использование чертежей низкопроизводительных микросхем в качестве обучающих данных.
Presenting PRIME, a data-driven approach for architecting hardware accelerators that trains a #DeepLearning model on existing accelerator data, improves runtime and chip area usage by 1.2 — 1.5X, and can generate accelerators for unseen applications → https://t.co/E0PcQMg3d4 pic.twitter.com/NdQWQgZ4AA
— Google AI (@GoogleAI) March 17, 2022
— Google AI (@GoogleAI) March 17, 2022
Новый подход создает архитектуру ИИ-чипов на основе существующих чертежей и показателей производительности.
Команда заявила, что сделанные по методу PRIME-конструкции чипы имеют задержку до 50% меньше, чем созданные с использованием классических подходов. Глубокое обучение также позволило сократить время для создания чертежей до 99%.
Работа алгоритма PRIME. Данные: Google.
Исследователи сравнили производительность чипов, созданных PRIME, с ускорителями EdgeTPU в девяти ИИ-приложениях, включая модели классификации изображений MobileNetV2 и MobileNetEdge. Они подчеркнули, что конструкции были оптимизированы для каждого приложения.
Подход PRIME улучшил задержку в 2,7 раза и уменьшил площадь кристалла в 1,5 раза. Это позволит удешевить чипы и снизить энергопотребление, заявили ученые.
Кроме этого, производительность чипов, созданных с помощью ИИ, оказалась выше во всех девяти приложениях, участвовавших в эксперименте. Всего три из них имели более высокую задержку в сравнении с конструкциями, созданных с помощью моделирования.
Сравнение задержки при тестировании девяти приложений (меньше — лучше). Данные: Google.
По словам исследователей, PRIME имеет многообещающие перспективы. Это включает в себя создание микросхем для приложений, требующих решения сложных задач оптимизации, а также использование чертежей низкопроизводительных микросхем в качестве обучающих данных.
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба