


21 декабря 2023 giovanni1313
Каким выглядит будущее ИИ? Каким будет мир, в котором технологии искусственного интеллекта занимают всё более центральную роль во всех сферах нашей жизни?
Мы можем нарисовать радужные, близкие к утопическим картины — и мы найдём немало сторонников для этой точки зрения. Точки зрения, в которой ИИ является «волшебной палочкой», способной превратить жизнь в сказку. Вот что, к примеру, пишут профессионально оптимистичные ребята из «Бостон Консалтинг Груп»:
«ИИ меняет мир со скоростью молнии. Его потенциальные применения, мощь и подрывные возможности кажутся почти неисчерпаемыми. В то же время наша увлеченность созданием разума, который может действовать вне нас, безгранична — и оттенена тревогой — как никогда».
Мы можем уйти в другую крайность и представить ужасный, апокалиптический сценарий. И здесь нас также поддержит большое число экспертов — причем экспертов, гораздо лучше владеющих темой, чем ребята в дорогих костюмах из консалтинговых фирм. Процитируем первого среди равных таких экспертов — Элиезера Юдковски:
«Если оно намного умнее нас, то оно может добиться больше того, что хочет. Во-первых, оно может захотеть умертвить нас до того, как мы сможем построить следующий сверхинтеллект, который мог бы с ним соперничать. Во-вторых, оно скорее всего захочет сделать вещи, которые убьют нас в результате побочных эффектов, например построит так много электростанций, работающих на термоядерном синтезе — ведь в океанах много водорода — что океаны вскипят».
Но мне кажется, что наше ИИ-будущее не будет ни радужно-пафосным, ни катастрофически смертельным. Оно будет… трудным. А трудным оно будет потому, что для развития этой важнейшей технологии нам нужны экспоненты. Много экспонент. Переплетенных между собой, зависящих друг от друга, утыкающихся в самые разные препятствия и потому представляющих собой очень и очень неустойчивую конструкцию.
Расти по экспоненте всегда трудно. Но когда требуется идти вверх сразу по целой связке экспонент, сложность задачи растёт многократно. В этом обзоре я попробую отметить наиболее очевидные трудности на этом пути. Но этот обзор не претендует на исчерпывающий характер. Потому что на самом деле экспонент, необходимых для ИИ, не восемь — а намного больше. Я постарался описать лишь самые масштабные из них. Это скорее набор необходимых — но не обязательно достаточных — условий.
Обзор основан на идеях американского исследователя Карла Шульмана, а также Пола Кристиано, Элиезера Юдковски (с критических позиций) и некоторых других уважаемых экспертов. В некоторых вопросах я стараюсь изложить собственное видение, особенно в местах, которые больше опираются на экономические факторы. На всякий случай сразу возьму на себя вину: все возможные ошибки, скорее всего, являются моей отсебятиной.
А без ошибок будущее предугадать, увы, довольно трудно, если вообще возможно. Описываемые здесь сценарии являются лишь одним из возможных путей к искусственному интеллекту. И эти сценарии не лишены недостатков. О которых мы отдельно поговорим в заключительной части. Тем не менее, с позиций сегодняшнего дня и сегодняшнего понимания темы эти сценарии видятся самым надежным и самым вероятным путем к ИИ.
Итак, начинаем!
1. Вычислительная сложность ИИ
Большой интеллект — это большая и очень сложная штуковина. Пожалуй, это одна из самых интуитивно ожидаемых экспонент для развития ИИ. Первое упоминание о которой мы находим в первой же статье, основавшей эту область научного знания: «Вычислительные машины и разум» Алана Тьюринга.
Описывая предпосылки, при которых машина может обыграть человека в «игре в имитацию» (позже она станет широко известна как тест Тьюринга), британский математик сразу говорит о размере программы. «Я уверен, что лет через пятьдесят станет возможным программировать работу машин с емкостью памяти около 10^9 [т. е. 128 мегабайт; гигантский объем по меркам 1950 г., когда писалась работа - Giovanni] так, чтобы они могли играть в имитацию настолько успешно, что шансы среднего человека установить присутствие машины через пять минут после того, как он начнет задавать вопросы, не поднимались бы выше 70%».

Алан Тьюринг
В следующие несколько десятилетий исследователи пытались создать ИИ, используя символический подход и не дожидаясь предсказанных Тьюрингом сотен мегабайт памяти. Ничего хорошего у них не получилось. Немного позднее стал развиваться альтернативный подход — машинное обучение. И вот там очень быстро стало ясно: размер имеет значение. А чтобы это значение сравнялось со значением человеческого интеллекта, может потребоваться куда больше тьюринговских 128 мегабайт…
Особенно большими оказались вычислительные затраты на такой алгоритм, как нейронные сети. Настолько, что еще в 1987 пионер этого научного направления Джеффри Хинтон не верил, что данный подход можно будет использовать для решения больших, серьезных задач — слишком велики были требования к объёму вычислений.
Но пока скептик Хинтон искал альтернативные, менее вычислительно затратные методы создания нейросетей (спойлер: до сих пор прогресс в этом направлении невелик, чего мы коснемся в обсуждении следующей экспоненты), оптимисты рисовали радужные прогнозы развития ИИ, в которых не существовало никаких трудностей роста по экспоненте.
Одним из таких оптимистов был Ханс Моравек. В 1997 он опубликовал смелую статью «Когда компьютерное оборудование догонит человеческий мозг?», в числе центральных тезисов которой был такой график:

Надо сказать, что этот график, где обычная живая мышь наделяется сотней миллиардов инструкций в секунду и помещается рядом с шахматным суперкомпьютером «Дип Блу», заработал Моравеку изрядную порцию критики. Но какие конструктивные идеи критики могли противопоставить “количественному“ подходу Моравека? Заклинания о том, что у человека есть сознание, которое не опишешь миллионами инструкций в секунду? Полумистические рассуждения о некой «божьей искре», отделящей разумное от неразумного? Философские эксперименты, построенные по принципу софизмов, где задача подгоняется под заранее выбранный ответ?
Все эти глубокомысленные рассуждения тогда, в 1997, меркли на фоне недавно одержанной победы шахматного суперкомпьютера «Дип Блу» над Гарри Каспаровым. «Количественный» подход обрастал новыми сторонниками. Одним из самых известных стал Рэй Курцвейл. В своей книге “Сингулярность рядом“ он приводит следующий график, близкий по духу к графику Моравека, но описывающий как раз экспоненциальный рост:
К 2020, прогнозировал Курцвейл, вычислительная мощь, необходимая для симуляции человеческого мозга, будет стоить 1000 долларов. Программное обеспечение, правда, должно было подъехать позже на 10 лет. Так что еще тогда главный теоретик технологической сингулярности обещал нам весьма интересные 2020-ые.
Что ж, пора переходить от радужных прогнозов сторонников «количественного» подхода к практическим достижениям. Получается ли у нас конвертировать мегабайты и гигафлопсы в искусственный интеллект?
На этот вопрос мы можем ответить решительным, безоговорочным «да!». Оптимисты оказались абсолютно правы. И, что самое любопытное, самые сильные результаты достигаются архитектурой, в возможностях которой сомневался даже отец-основатель Джеффри Хинтон — нейронными сетями.
Если в 1987 Хинтон писал, что большое количество параметров ставит крест на практическом развитии таких моделей, то к 2020 его отношение к перспективам их масштабирования сменилось на прямо противоположное. Что хорошо отразилось в его ироничном твите, написанном вскоре после выхода гигантской модели GPT-3:

“Экстраполируя в будущее впечатляющую мощь GPT-3, получим, что ответ на главный вопрос жизни, вселенной и всего такого — всего лишь 4,398 триллионов параметров».
Количественное масштабирование нейронных сетей — уже давно повод не для шуток, а для фундаментальных исследований. За последние годы они оформились в отдельную область, число работ в которой скоро пойдёт на сотни. И все эти работы приходят к однозначному выводу: чем сложнее модель, чем больше в ней параметров — тем большего она может достичь. Исключения очень редки и часто, как водится, лишь подтверждают общее правило.
Для иллюстрации этого правила посмотрим на результаты одной из таких работ, исследовавшей в общей сложности 12 различных архитектур и 54 различных вариантов моделей:
Итак, для развития ИИ нам нужно наращивать размеры модели. Но с каким темпом у нас получалось это делать? Вновь обратимся к графикам:
Автор этого графика, Джейм Севилья, делает следующие важные выводы. Во-первых, начиная с 00-ых, темп роста числа параметров оставался более-менее стабильным: удвоение каждые 18-24 месяца. Даже революция глубокого обучения — распространение нейронных сетей в качестве преобладающей архитектуры, датируемое 2011-12 гг. — никак не повлияла на скорость масштабирования.
Однако примерно в 2016-18 случается любопытная вещь: в отрыв уходят языковые модели. Число их параметров удваивается каждые 3-8 месяцев. Отметим, что именно в языковых моделях мы видим наиболее впечатляющий прогресс в степени интеллекта (в классическом понимании этого термина).
При этом график заканчивается 2021-ым. Где самый высоко забравшийся квадратик обозначает модель “Switch” c 1,6 трлн. параметрами. С момента публикации этой работы прошло уже более двух лет — что, как любят повторять адепты машинного обучения, является целой вечностью для этой области исследования. Насколько выросли модели за это время?
Ответ разочарует сторонников экспоненциального роста. Если мы отбросим технические попытки «проверить концепцию» и сосредоточимся на реальных, практических моделях, роста в числе параметров за эти два года мы толком и не увидим. Одна из сильнейших моделей на сегодня, GPT-4, имеет 1,76 трлн. параметров. Причем вычислительная сложность этой системы выросла совсем ненамного по сравнению с GPT-3 (175 млрд. параметров), за счет применения так называемой разреженной архитектуры.

Трансформерный блок с разреженной архитектурой. Разреженной она называется потому, что слои, обозначенные MLP, не задействуются все одновременно
Почему же эта экспонента остановилась? Может, дело в том, что и GPT-3, и “Switch” опережали своё время, забравшись выше тренда, и затем случилась «нормализация»? Нет: тренд конца 2010-ых действительно был неимоверно крут (в прямом смысле). Если бы мы четко следовали этому тренду, GPT-3 вышла бы 9-ю месяцами позже, в начале 2021. И cейчас мы вправе были бы ожидать модели с 80 триллионами параметров — размером, который будоражил неокрепшие умы падких до хайпа твиттерных экспертов, но который имеет мало общего с физической реальностью.
Впрочем, эта гипотеза выглядит более разумной, если мы посчитаем тренд конца 2010-ых слишком крутым, чтобы быть устойчивым, и предположим откат к старому тренду с удвоением каждые полтора года.
Однако важно понимать не только то, где на графике проходят экспоненциальные трендовые кривые, но и фундаментальные факторы, влияющие на их форму. Одним из ключевых таких факторов в начале 2020-ых стал выход языковых моделей из академической среды в коммерческую. Это означало, что, помимо стоимости разработки таких алгоритмов, инженеры стали принимать в расчет и стоимость их использования конечными пользователями. А эта стоимость напрямую зависит от вычислительной сложности модели.
Но вопросов себестоимости мы подробнее коснемся в разговоре о следующей экспоненте ИИ. Пока же отметим еще одну существенную черту коммерциализации: информация о характеристиках передовых моделей перестаёт публиковаться разработчиками. Чтобы не облегчать работу конкурентам. Данные о числе параметров GPT-4 по-прежнему имеют неофициальный характер и стали известны публике в результате утечек. А, например, о еще одной сильной недавно вышедшей модели, ”Gemini”, мы не знаем практически ничего. Всё это будет затруднять дальнейший анализ перспектив масштабирования ИИ-алгоритмов.
Подытоживая, пока нет особых оснований предполагать, что экспонента роста вычислительной сложности ИИ «сломалась» и навсегда перестала работать. Переход ИИ из академической сферы в коммерческую очень сильно повышает ставки в гонке между крупными корпорациями-разработчиками. Увеличение количества параметров является проверенным рецептом лидерства в этой гонке. Необходимым условием. Хотя и недостаточным.
Скоростной участок трассы остался позади, и последние три года разработчики проехали «на пониженной передаче». Но впереди могут возникнуть возможности для еще одного ускорения. Консервативный прогноз, на мой взгляд, заключается в продолжении долгосрочного тренда на удвоение размера модели каждые 18 месяцев.
Есть ли пределы этому росту? Да, разумеется. И подробнее мы их обсудим, знакомясь с еще одной экспонентой, критически необходимой для дальнейшего развития ИИ.
Мы можем нарисовать радужные, близкие к утопическим картины — и мы найдём немало сторонников для этой точки зрения. Точки зрения, в которой ИИ является «волшебной палочкой», способной превратить жизнь в сказку. Вот что, к примеру, пишут профессионально оптимистичные ребята из «Бостон Консалтинг Груп»:
«ИИ меняет мир со скоростью молнии. Его потенциальные применения, мощь и подрывные возможности кажутся почти неисчерпаемыми. В то же время наша увлеченность созданием разума, который может действовать вне нас, безгранична — и оттенена тревогой — как никогда».
Мы можем уйти в другую крайность и представить ужасный, апокалиптический сценарий. И здесь нас также поддержит большое число экспертов — причем экспертов, гораздо лучше владеющих темой, чем ребята в дорогих костюмах из консалтинговых фирм. Процитируем первого среди равных таких экспертов — Элиезера Юдковски:
«Если оно намного умнее нас, то оно может добиться больше того, что хочет. Во-первых, оно может захотеть умертвить нас до того, как мы сможем построить следующий сверхинтеллект, который мог бы с ним соперничать. Во-вторых, оно скорее всего захочет сделать вещи, которые убьют нас в результате побочных эффектов, например построит так много электростанций, работающих на термоядерном синтезе — ведь в океанах много водорода — что океаны вскипят».
Но мне кажется, что наше ИИ-будущее не будет ни радужно-пафосным, ни катастрофически смертельным. Оно будет… трудным. А трудным оно будет потому, что для развития этой важнейшей технологии нам нужны экспоненты. Много экспонент. Переплетенных между собой, зависящих друг от друга, утыкающихся в самые разные препятствия и потому представляющих собой очень и очень неустойчивую конструкцию.
Расти по экспоненте всегда трудно. Но когда требуется идти вверх сразу по целой связке экспонент, сложность задачи растёт многократно. В этом обзоре я попробую отметить наиболее очевидные трудности на этом пути. Но этот обзор не претендует на исчерпывающий характер. Потому что на самом деле экспонент, необходимых для ИИ, не восемь — а намного больше. Я постарался описать лишь самые масштабные из них. Это скорее набор необходимых — но не обязательно достаточных — условий.
Обзор основан на идеях американского исследователя Карла Шульмана, а также Пола Кристиано, Элиезера Юдковски (с критических позиций) и некоторых других уважаемых экспертов. В некоторых вопросах я стараюсь изложить собственное видение, особенно в местах, которые больше опираются на экономические факторы. На всякий случай сразу возьму на себя вину: все возможные ошибки, скорее всего, являются моей отсебятиной.
А без ошибок будущее предугадать, увы, довольно трудно, если вообще возможно. Описываемые здесь сценарии являются лишь одним из возможных путей к искусственному интеллекту. И эти сценарии не лишены недостатков. О которых мы отдельно поговорим в заключительной части. Тем не менее, с позиций сегодняшнего дня и сегодняшнего понимания темы эти сценарии видятся самым надежным и самым вероятным путем к ИИ.
Итак, начинаем!
1. Вычислительная сложность ИИ
Большой интеллект — это большая и очень сложная штуковина. Пожалуй, это одна из самых интуитивно ожидаемых экспонент для развития ИИ. Первое упоминание о которой мы находим в первой же статье, основавшей эту область научного знания: «Вычислительные машины и разум» Алана Тьюринга.
Описывая предпосылки, при которых машина может обыграть человека в «игре в имитацию» (позже она станет широко известна как тест Тьюринга), британский математик сразу говорит о размере программы. «Я уверен, что лет через пятьдесят станет возможным программировать работу машин с емкостью памяти около 10^9 [т. е. 128 мегабайт; гигантский объем по меркам 1950 г., когда писалась работа - Giovanni] так, чтобы они могли играть в имитацию настолько успешно, что шансы среднего человека установить присутствие машины через пять минут после того, как он начнет задавать вопросы, не поднимались бы выше 70%».
Алан Тьюринг
В следующие несколько десятилетий исследователи пытались создать ИИ, используя символический подход и не дожидаясь предсказанных Тьюрингом сотен мегабайт памяти. Ничего хорошего у них не получилось. Немного позднее стал развиваться альтернативный подход — машинное обучение. И вот там очень быстро стало ясно: размер имеет значение. А чтобы это значение сравнялось со значением человеческого интеллекта, может потребоваться куда больше тьюринговских 128 мегабайт…
Особенно большими оказались вычислительные затраты на такой алгоритм, как нейронные сети. Настолько, что еще в 1987 пионер этого научного направления Джеффри Хинтон не верил, что данный подход можно будет использовать для решения больших, серьезных задач — слишком велики были требования к объёму вычислений.
Но пока скептик Хинтон искал альтернативные, менее вычислительно затратные методы создания нейросетей (спойлер: до сих пор прогресс в этом направлении невелик, чего мы коснемся в обсуждении следующей экспоненты), оптимисты рисовали радужные прогнозы развития ИИ, в которых не существовало никаких трудностей роста по экспоненте.
Одним из таких оптимистов был Ханс Моравек. В 1997 он опубликовал смелую статью «Когда компьютерное оборудование догонит человеческий мозг?», в числе центральных тезисов которой был такой график:
Надо сказать, что этот график, где обычная живая мышь наделяется сотней миллиардов инструкций в секунду и помещается рядом с шахматным суперкомпьютером «Дип Блу», заработал Моравеку изрядную порцию критики. Но какие конструктивные идеи критики могли противопоставить “количественному“ подходу Моравека? Заклинания о том, что у человека есть сознание, которое не опишешь миллионами инструкций в секунду? Полумистические рассуждения о некой «божьей искре», отделящей разумное от неразумного? Философские эксперименты, построенные по принципу софизмов, где задача подгоняется под заранее выбранный ответ?
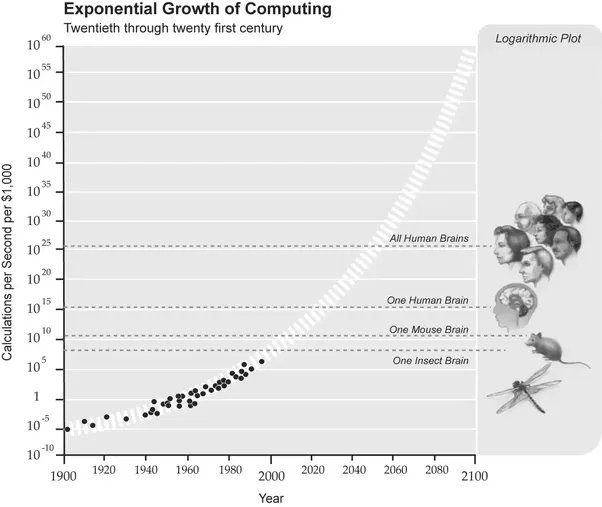
Все эти глубокомысленные рассуждения тогда, в 1997, меркли на фоне недавно одержанной победы шахматного суперкомпьютера «Дип Блу» над Гарри Каспаровым. «Количественный» подход обрастал новыми сторонниками. Одним из самых известных стал Рэй Курцвейл. В своей книге “Сингулярность рядом“ он приводит следующий график, близкий по духу к графику Моравека, но описывающий как раз экспоненциальный рост:
К 2020, прогнозировал Курцвейл, вычислительная мощь, необходимая для симуляции человеческого мозга, будет стоить 1000 долларов. Программное обеспечение, правда, должно было подъехать позже на 10 лет. Так что еще тогда главный теоретик технологической сингулярности обещал нам весьма интересные 2020-ые.
Что ж, пора переходить от радужных прогнозов сторонников «количественного» подхода к практическим достижениям. Получается ли у нас конвертировать мегабайты и гигафлопсы в искусственный интеллект?
На этот вопрос мы можем ответить решительным, безоговорочным «да!». Оптимисты оказались абсолютно правы. И, что самое любопытное, самые сильные результаты достигаются архитектурой, в возможностях которой сомневался даже отец-основатель Джеффри Хинтон — нейронными сетями.
Если в 1987 Хинтон писал, что большое количество параметров ставит крест на практическом развитии таких моделей, то к 2020 его отношение к перспективам их масштабирования сменилось на прямо противоположное. Что хорошо отразилось в его ироничном твите, написанном вскоре после выхода гигантской модели GPT-3:
“Экстраполируя в будущее впечатляющую мощь GPT-3, получим, что ответ на главный вопрос жизни, вселенной и всего такого — всего лишь 4,398 триллионов параметров».
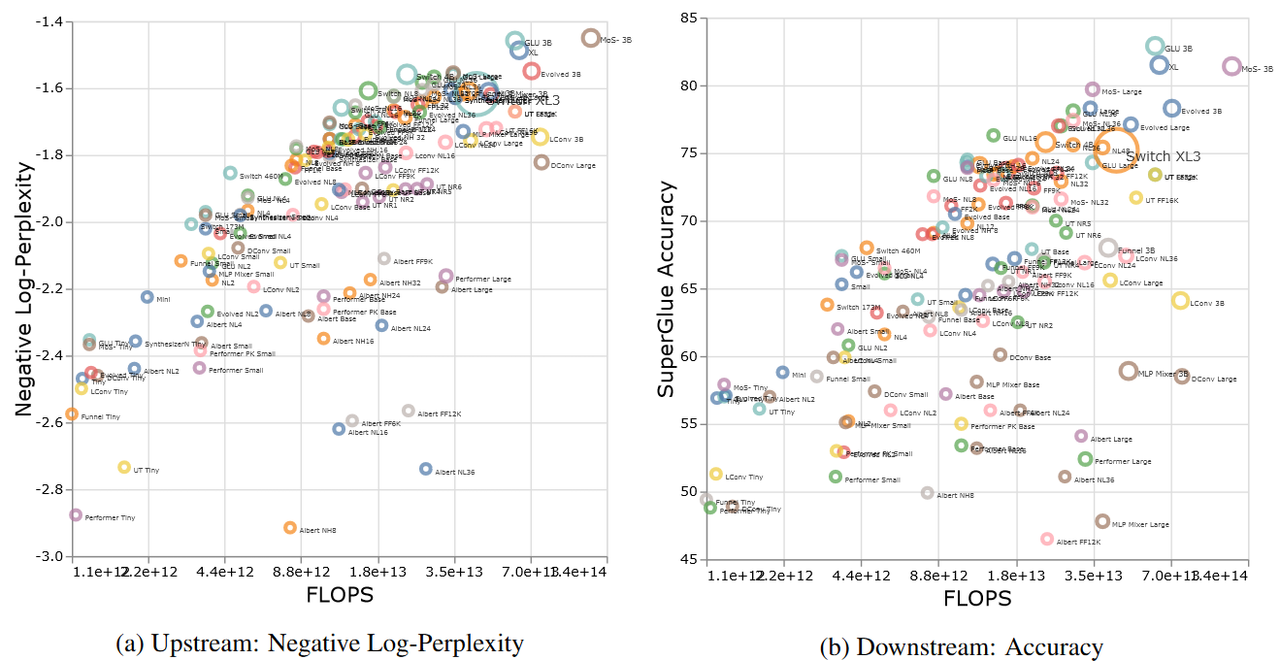
Количественное масштабирование нейронных сетей — уже давно повод не для шуток, а для фундаментальных исследований. За последние годы они оформились в отдельную область, число работ в которой скоро пойдёт на сотни. И все эти работы приходят к однозначному выводу: чем сложнее модель, чем больше в ней параметров — тем большего она может достичь. Исключения очень редки и часто, как водится, лишь подтверждают общее правило.
Для иллюстрации этого правила посмотрим на результаты одной из таких работ, исследовавшей в общей сложности 12 различных архитектур и 54 различных вариантов моделей:
Итак, для развития ИИ нам нужно наращивать размеры модели. Но с каким темпом у нас получалось это делать? Вновь обратимся к графикам:
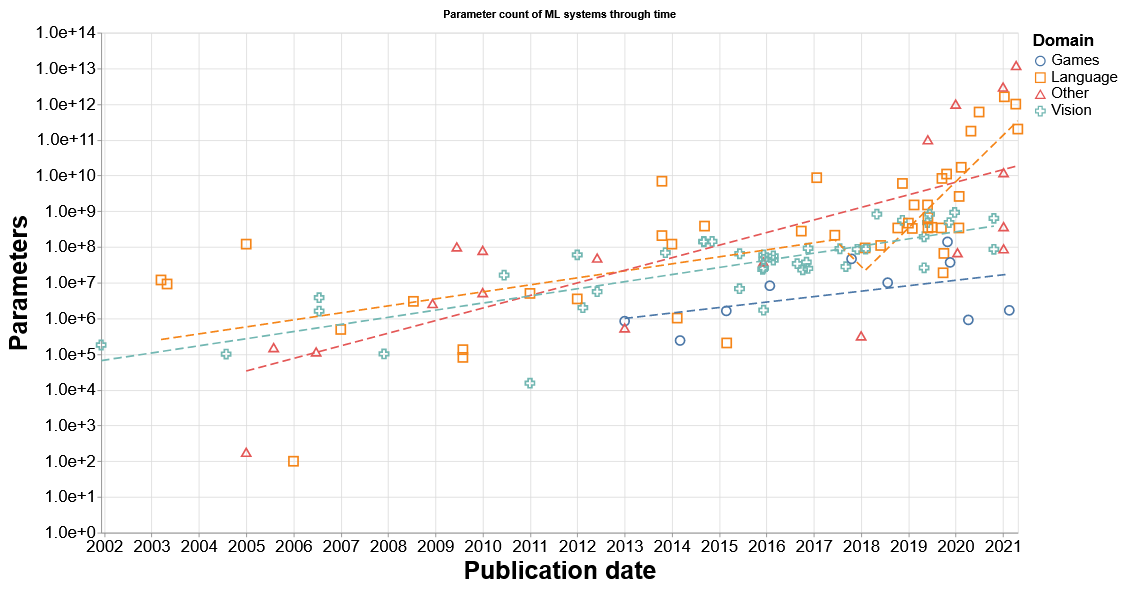
Автор этого графика, Джейм Севилья, делает следующие важные выводы. Во-первых, начиная с 00-ых, темп роста числа параметров оставался более-менее стабильным: удвоение каждые 18-24 месяца. Даже революция глубокого обучения — распространение нейронных сетей в качестве преобладающей архитектуры, датируемое 2011-12 гг. — никак не повлияла на скорость масштабирования.
Однако примерно в 2016-18 случается любопытная вещь: в отрыв уходят языковые модели. Число их параметров удваивается каждые 3-8 месяцев. Отметим, что именно в языковых моделях мы видим наиболее впечатляющий прогресс в степени интеллекта (в классическом понимании этого термина).
При этом график заканчивается 2021-ым. Где самый высоко забравшийся квадратик обозначает модель “Switch” c 1,6 трлн. параметрами. С момента публикации этой работы прошло уже более двух лет — что, как любят повторять адепты машинного обучения, является целой вечностью для этой области исследования. Насколько выросли модели за это время?
Ответ разочарует сторонников экспоненциального роста. Если мы отбросим технические попытки «проверить концепцию» и сосредоточимся на реальных, практических моделях, роста в числе параметров за эти два года мы толком и не увидим. Одна из сильнейших моделей на сегодня, GPT-4, имеет 1,76 трлн. параметров. Причем вычислительная сложность этой системы выросла совсем ненамного по сравнению с GPT-3 (175 млрд. параметров), за счет применения так называемой разреженной архитектуры.
Трансформерный блок с разреженной архитектурой. Разреженной она называется потому, что слои, обозначенные MLP, не задействуются все одновременно
Почему же эта экспонента остановилась? Может, дело в том, что и GPT-3, и “Switch” опережали своё время, забравшись выше тренда, и затем случилась «нормализация»? Нет: тренд конца 2010-ых действительно был неимоверно крут (в прямом смысле). Если бы мы четко следовали этому тренду, GPT-3 вышла бы 9-ю месяцами позже, в начале 2021. И cейчас мы вправе были бы ожидать модели с 80 триллионами параметров — размером, который будоражил неокрепшие умы падких до хайпа твиттерных экспертов, но который имеет мало общего с физической реальностью.
Впрочем, эта гипотеза выглядит более разумной, если мы посчитаем тренд конца 2010-ых слишком крутым, чтобы быть устойчивым, и предположим откат к старому тренду с удвоением каждые полтора года.
Однако важно понимать не только то, где на графике проходят экспоненциальные трендовые кривые, но и фундаментальные факторы, влияющие на их форму. Одним из ключевых таких факторов в начале 2020-ых стал выход языковых моделей из академической среды в коммерческую. Это означало, что, помимо стоимости разработки таких алгоритмов, инженеры стали принимать в расчет и стоимость их использования конечными пользователями. А эта стоимость напрямую зависит от вычислительной сложности модели.
Но вопросов себестоимости мы подробнее коснемся в разговоре о следующей экспоненте ИИ. Пока же отметим еще одну существенную черту коммерциализации: информация о характеристиках передовых моделей перестаёт публиковаться разработчиками. Чтобы не облегчать работу конкурентам. Данные о числе параметров GPT-4 по-прежнему имеют неофициальный характер и стали известны публике в результате утечек. А, например, о еще одной сильной недавно вышедшей модели, ”Gemini”, мы не знаем практически ничего. Всё это будет затруднять дальнейший анализ перспектив масштабирования ИИ-алгоритмов.
Подытоживая, пока нет особых оснований предполагать, что экспонента роста вычислительной сложности ИИ «сломалась» и навсегда перестала работать. Переход ИИ из академической сферы в коммерческую очень сильно повышает ставки в гонке между крупными корпорациями-разработчиками. Увеличение количества параметров является проверенным рецептом лидерства в этой гонке. Необходимым условием. Хотя и недостаточным.
Скоростной участок трассы остался позади, и последние три года разработчики проехали «на пониженной передаче». Но впереди могут возникнуть возможности для еще одного ускорения. Консервативный прогноз, на мой взгляд, заключается в продолжении долгосрочного тренда на удвоение размера модели каждые 18 месяцев.
Есть ли пределы этому росту? Да, разумеется. И подробнее мы их обсудим, знакомясь с еще одной экспонентой, критически необходимой для дальнейшего развития ИИ.
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба