


2 февраля 2024 giovanni1313
Мы продолжаем срывать покровы критически анализировать экономические исследования по теме замещения работников искусственным интеллектом. Сегодня мы познакомимся с работой «Beyond AI Exposure: Which Tasks are Cost-Effective to Automate with Computer Vision?», посвященной экономической привлекательности замены людей на ИИ.
Эта работа была широко освещена в СМИ: Bloomberg, Euronews, Business Insider, Time и далее по списку. Во всех без исключения заголовках читается коллективное облегчение: ура, люди не останутся без работы, потому что это ваш ИИ тупо экономически неконкурентоспособен.
Вывод, мягко говоря, неожиданный. Как с точки зрения взглядов, бытующих среди экспертов и футурологов, так и с точки зрения истории автоматизации труда. Поэтому давайте в подробностях рассмотрим, как именно исследователи к нему пришли.
Один из центральных моментов исследования заключается в том, что он ограничивается только задачей машинного зрения. Главным образом потому, что это одна из самых зрелых областей в машинного обучения. Где более-менее ясны вводные: что представляет собой машинная модель, сколько она стоит и что она может. Причем круг ее возможностей достаточно узок, что здорово облегчает сопоставление с нынешней «человеческой» экономикой.
Другими словами, у нас опять получается ситуация «ищут не там, где потеряли, а там, где светло». Помните, в предыдущей рассмотренной работе авторы пытались натянуть всё разнообразие человеческой работы на несколько узких направлений машинного обучения, существовавших в 2019 году (в числе которых было и машинное зрение)? Здесь примерно тот же принцип.
Разве что в нынешнем случае исследователи хотя бы остаются в границах адекватности и сопоставляют узкий функционал машинного зрения со зрительными задачами на разных рабочих местах. Например, такая задача, как проверка поддонов, чтобы на них лежали нужные предметы, или оценка состояния кожи и волос в контексте работы косметолога или дерматолога.

Но на большинстве рабочих мест работать надо не только глазами. Так, косметологу надо не только оценивать состояние кожи, но и уметь обрабатывать ее самыми разными способами. Как здесь сопоставить машину и человека?
Авторы предлагают не заморачиваться с такими каверзными моментами и просто-напросто абстрагироваться от неудобных сложностей. Они берут долю рабочего времени, которая относится на выполнение зрительных задач, берут зарплату человека пропорционально этой долe, и всё остальное их не касается. В теории особых претензий к такому анализу нет. Но на практике такой сценарий, конечно, зачастую невозможен. Вряд ли кто-то будет приставлять к каждому косметологу манипулятор с камерой, который будет задействован 7% времени и будет делать то же самое, что уже умеет косметолог. И требовать от последнего на 7% ужаться в зарплате.
Так что такой анализ имеет лишь теоретическую ценность. Практические выводы из такой постановки задачи не вынести — за исключением тех немногих профессий, где использование зрительныx навыков составляет львиную долю рабочего времени.
Ладно, ограничимся теорией. В теории у авторов получается 420 зрительных задач, из которых 416 фактически представлены в американской экономике. Ключевая предпосылка данной работы — это расчеты экономической целесообразности замены человека машиной в таких задачах. Практически во всех предыдущих исследованиях на эту тему данный аспект игнорировался; подразумевалось, что если ИИ технологически способен выполнять ту или иную задачу — этого достаточно.
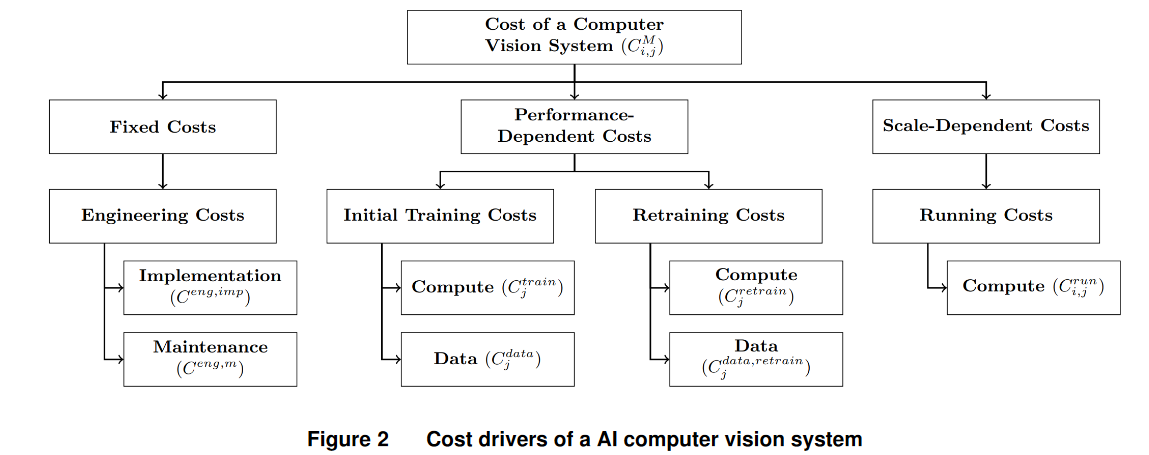
Что ж, предпосылка действительно нужная. Остаётся только подсчитать, сколько будет стоить работа машины. Исследователи делят издержки на 3 группы, которые мы можем примерно обозначить как операционные, капитальные с влиянием на производительность и безусловные капитальные.
В качестве базовой модели машинного зрения авторы откапывают берут VGG-19 – старинную, тяжеловесную нейросеточку, созданную еще во времена, когда по планете бродили динозавры, а Дженсен Хуанг и помыслить не мог, что будущее “Nvidia” может быть связано с чем-то помимо компьютерной графики. Честно говоря, такому антиквариату место в музее, а не в серьезном экономическом исследовании. Более современные разработки ускакали настолько далеко вперёд, что даже прямое сравнение становится затруднительным.
Возьмем EfficientNet v2, вышедшую в июле 2021. Даже самая маленькая её версия на две головы превосходит VGG-19 в точности классификации изображений. При этом превосходя её по скорости на 11%.
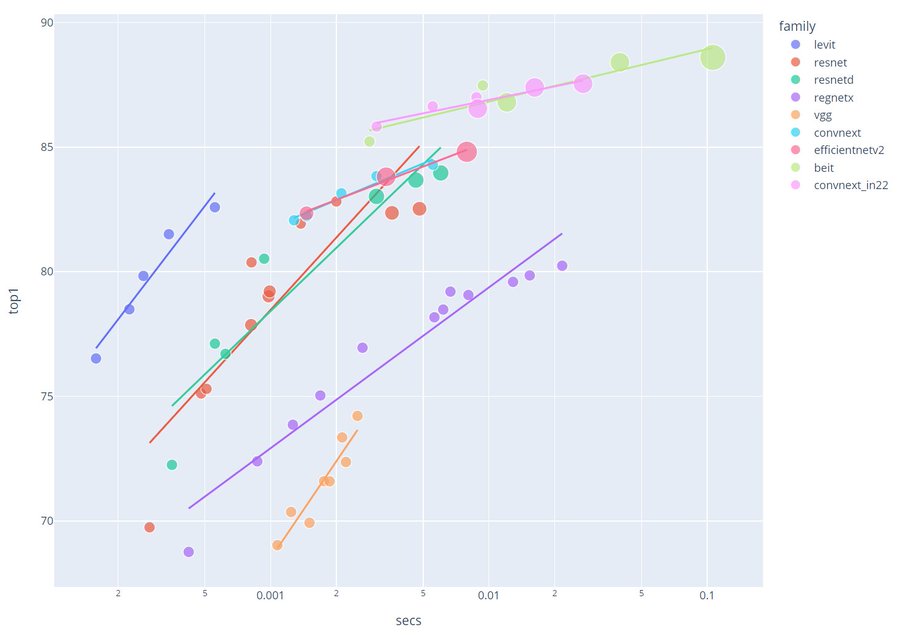
Выше и левее - лучшие характеристики точности и скорости
Ок, разница в скорости небольшая, так что можно заменить модель на более современную и держать в уме выигрыш в качестве. Что будет получаться по издержкам? Начнем с операционных. Это стоимость обсчета данных нейросетью. И тут сразу возникает вопрос: сколько именно данных надо считать? В примерах зрительных задач, которые я привёл выше, число кадров не должно быть велико. Для задачи с поддоном это один кадр — максимум еще пара, с разных ракурсов. Для задачи косметолога — это 10-30 кадров максимум.
Машина обсчитывает кадр быстро — для EfficientNet v2-S нужно 24 миллисекунды (порядка 42 кадров/сек) на видеокарте Nvidia V100. То есть задача будет выполнена за долю секунды. Секунда работы V100, в свою очередь, стоит 0,03 американских цента. Цента, не доллара. Чуть меньше трёх русских копеек.
Ну как человеческий работник может конкурировать с такими расценками? Очень просто, говорят нам авторы исследования. Нас не волнует, что машина считает всё за доли секунды. Мы будем считать, что машина будет работать столько же времени, сколько человек пялится на эти поддоны и на эту клиентскую кожу с волосами. И плевать, что содержимое кадров там будет практически одно и то же.
Но ладно. Невзирая на такое несправедливое отягощение, стоимость облачных GPU настолько низка, что на итоговый результат операционные издержки влияют слабо.
Идём дальше. Следующая группа затрат — капитальные с влиянием на производительность. Под этой категорией авторы подразумевают часть издержек на создание модели, варьирующуюся в зависимости от специфики задачи. Вариабельность объясняется, главным образом, стоимостью сбора данных, необходимых для обучения модели, а также затратами на собственно ее обучение (стоимость вычислений).
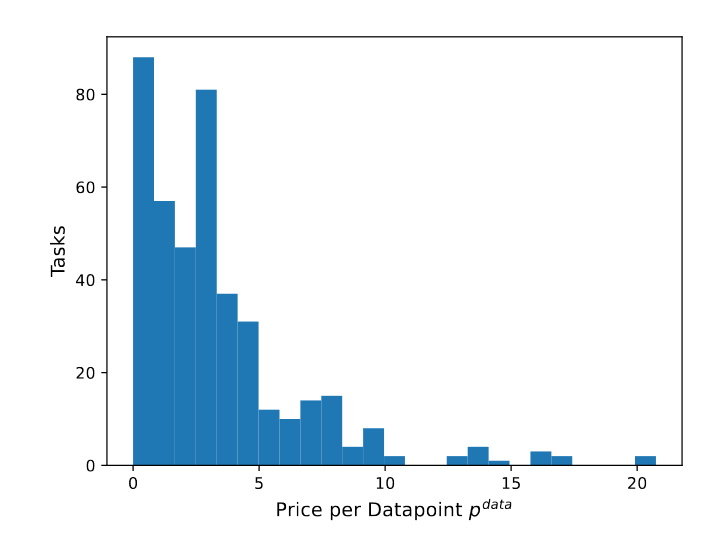
Здесь авторы скрупулезно подходят к расчетам необходимой точности и способностей модели в каждой визуальной задаче, а также стоимость добычи данных, опрашивая (через онлайн-платформу) представителей соответствующих профессий. Для большинства задач стоимость одного обучающего примера составляет от 0 до 4 долларов, с медианой в районе $3. Например, стоимость одного фотоснимка, сделанного работником, авторы оценили в $1,22. На мой взгляд, здесь есть некоторое завышение, но вряд ли больше, чем в 2 раза.
Помимо затрат на создание, в эту же категорию попадают затраты на регулярное переобучение/доводку модели. В совокупности за время использования модели эти затраты сравняются с затратами на первоначальное обучение, т. е. удвоят начальный вычислительный бюджет.
Наконец, безусловные капитальные затраты. Они примерно соответствуют человеческому труду, необходимому, чтобы превратить набор данных в готовую к применению машинную модель. Здесь они опираются на более раннее исследование, в котором приводится кейс создания ИИ-продукта за 6 месяцев командой из 11 специалистов, включавшей инженеров IBM. Затраты на проект составили 1,8 млн. долларов. Еще 240 тыс. долларов в год надо будет тратить на «сопровождение» проекта специалистами.
Сумма немалая — и в итоге эта категория затрат будет доминировать среди общей стоимости использования модели. Единственная ремарка, которая у меня есть, касается возможного аутсорсинга этой разработки. Если облачные GPU стоят примерно одинаково во всём мире, а собрать обучающие данные в американской фирме могут только американские работники, то разработка модели может вестись и в более экономных юрисдикциях, нежели родина IBM. Команда из Ижевска или Бангалора может справиться с этой задачей за гораздо меньшие деньги, чем инженеры IBM. Авторы совершенно не учитывают этой возможности для ускорения ИИ-автоматизации.
В общей совокупности, медианная приведенная стоимость машинной системы в визуальных задачах составила 2,3 млн. долларов. Сумма вполне здравая. И даже немного ниже моих интуитивных представлений; для ровного счета мы можем принять, что она отражает потенциал оффшоризации разработки.
Расчетный срок эксплуатации системы — 5 лет, в течение которых мы должны самортизировать все капитальные затраты на ее создание. Тоже более чем разумная оценка.
Недоумение возникает чуть позже — когда мы знакомимся с моделью внедрения таких систем в национальную экономику. Недоумение — это еще мягко сказано. Потому что основная модель авторов подразумевает, что каждая отдельная фирма в экономике — вплоть до микро-бизнеса из двух сотрудников — должна разрабатывать такую систему самостоятельно, независимо и для каждой визуальной задачи.
Почему? Откуда взялась такая предпосылка? Где ее видно в реальном мире? Модель машинного зрения — то же программное обеспечение. Много ли фирм пилят своё, уникальное ПО — для бухгалтерского учета, для CRM, для баз данных, для редактирования текстовых и табличных документов? Пилят уникальные операционные системы для своих компьютеров, в конце концов?
Впрочем, почему мы должны останавливаться только на программном обеспечении? По логике авторов, фирмы всё должны разрабатывать сами, ведь у них якобы такие уникальные нужды… Так что и компьютеры пускай тоже разрабатывают сами. И станки. И офисную мебель.
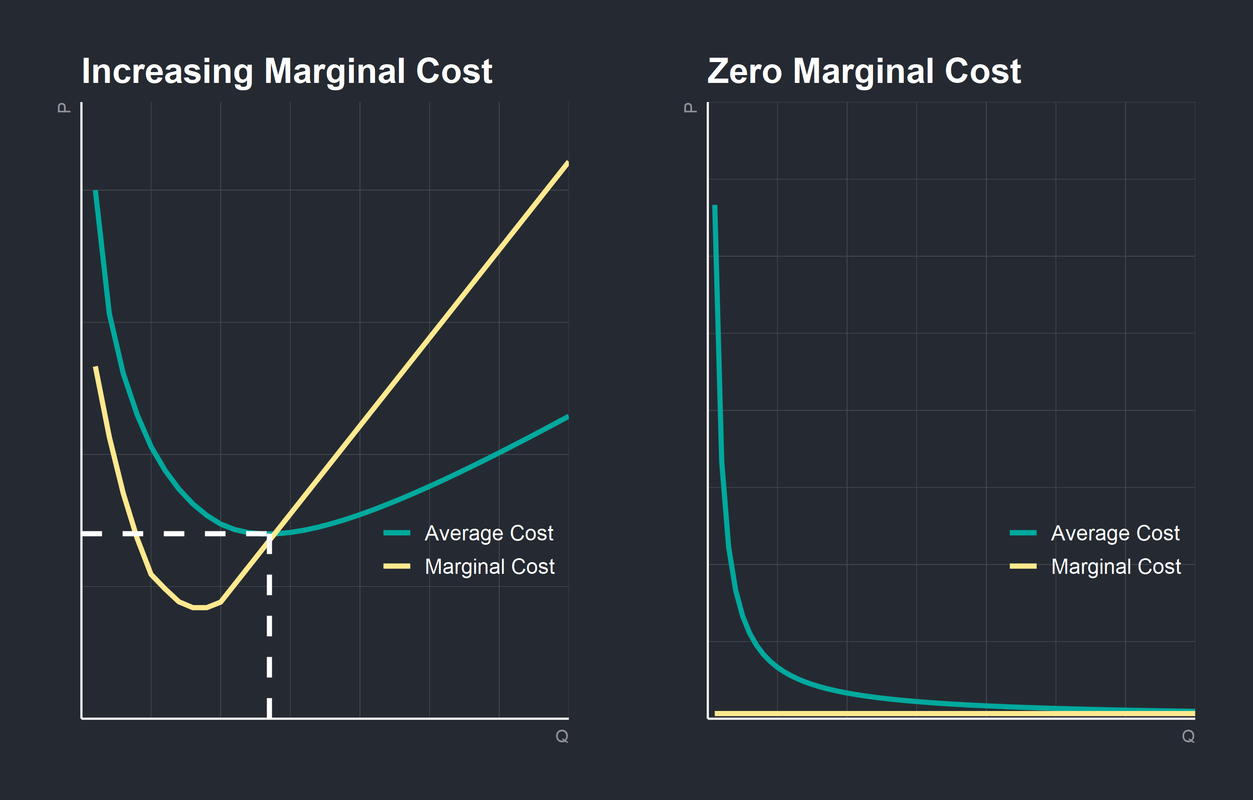
Внесем немножко логики в эту сюрреалистичную картину. Информационные продукты — а модель машинного зрения им является — хороши тем, что львиная доля издержек здесь приходится на процесс их разработки. Как только информационный продукт разработан — использование каждой последующей его копии для разработчика практически ничего не стоит. Если более строго, маржинальные издержки на каждого нового его покупателя почти равны нулю. Это означает огромный выигрыш от масштабирования использования таких продуктов. Выигрыш как для разработчика, так и для его пользователей.
Мы можем видеть этот выигрыш в успехе модели разработки ПО «на сторону», для массового клиента. И каком успехе! Крупнейшие корпорации с капитализацией в миллиарды и триллионы долларов — «Майкрософт», «Гугл», «Мета», «Оракл» — выросли на предоставлении своих программных продуктов максимально широкому кругу потребителей. Потому что намного проще и дешевле купить несколько лицензий ”Windows” по 200 долларов за штуку, чем разрабатывать ОС с нуля своими силами.
Но авторы исследования игнорируют эти очевидные вещи, а также преобладающую вокруг модель отношений вокруг ПО. Дальше остаётся чистая статистика. 87% американских фирм имеют не больше 20 сотрудников. Если ранжировать фирмы по численности персонала, медианный сотрудников будет работать в фирме, где от 500 до 749 человек. Только 36% рабочих мест имеют хотя бы одну задачу, где требуются зрительные навыки. Доля оплаты труда, которую можно отнести на эти навыки, еще меньше — 1,6% от всех зарплат в экономике. Последняя цифра, кстати, говорит нам, что было бы неуместно распространять выводы этого исследования на всю национальную экономику.
В общем, если мы заставим каждую фирму «изобретать велосипед» по новой, для большинства овчинка не будет стоить выделки. Авторы рассчитывают, что автоматизация по такой модели будет выгодна только для 23% затрагиваемых рабочих мест, т. е. для 8% в масштабах всей экономики. Именно эти цифры и подхватили все СМИ, трубя о бесперспективности замещения человека ИИ и расширяя эти выводы, мало адекватные даже для одного направления, на всю экономическую деятельность.

К чести авторов, они рассматривают разные предпосылки и модели применения машинного зрения. Так, одним из сценариев является «минималистичный», предполагающий нулевую стоимость сбора данных и вычислений. Стоимость разработки в нем падает до 165 тыс. долларов, стоимость «сопровождения» — до 123 тыс. долларов в год.
Удешевление даёт свои плоды: снижение расходов примерно на порядок позволяет нам с выгодой заменить машиной уже не 23%, а 49% зрительных задач.
Конечно, бесплатность вычислений и сбора данных — это нереалистичные предпосылки. Бесплатного ничего не бывает. Сценарий интересен другим: он позволяет нам оценить, сколько могли бы платить фирмы за лицензию на соответствующее ПО. Мы видим, что первая четверть рабочих мест выгодна при стоимости лицензии 2,3 млн. долларов на 5 лет. Вторая четверть — при стоимости порядка 150 тыс. долларов в год (165/5 + 123).
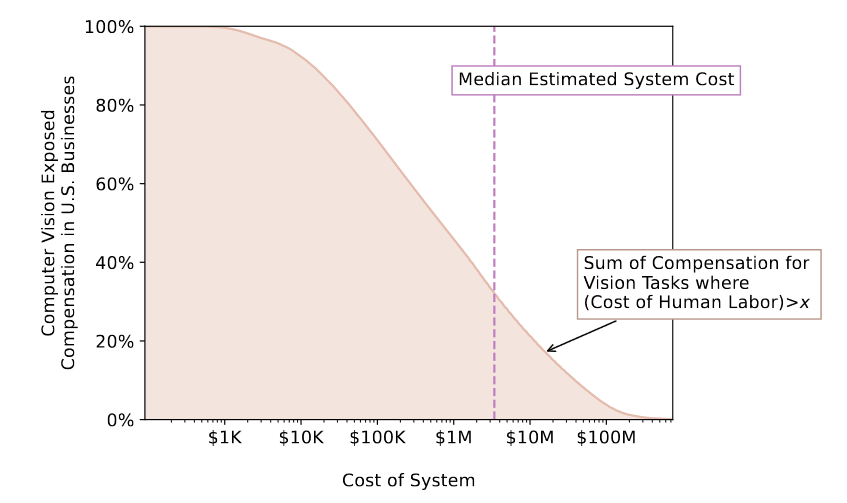
То есть пока связь такая: удешевление системы в ~3 раза даёт нам возможность автоматизировать еще 25% рабочих мест. Добавим, что 150 тыс. долларов — это внушительная сумма по меркам рынка ПО. Хотя, как правило, лицензирование там идёт по количеству рабочих мест, а не по одной «оптовой» лицензии на фирму.
Наконец, мы переходим к самым интересным — самым реалистичным — альтернативным сценариям. Первый из них касается как раз классической модели масштабирования ПО: когда одна система используется широким кругом фирм. И с такой моделью результаты меняются кардинально. Даже если для каждой визуальной задачи каждая отрасль экономики (классификация США выделяет 324 отрасли) будет создавать свою систему, доля задач, где человека выгодно заместить машиной, подскакивает где-то до 85%. Агрегирование в масштабах всей экономики (одна модель на каждую задачу) даёт небольшой прирост: до 88%.
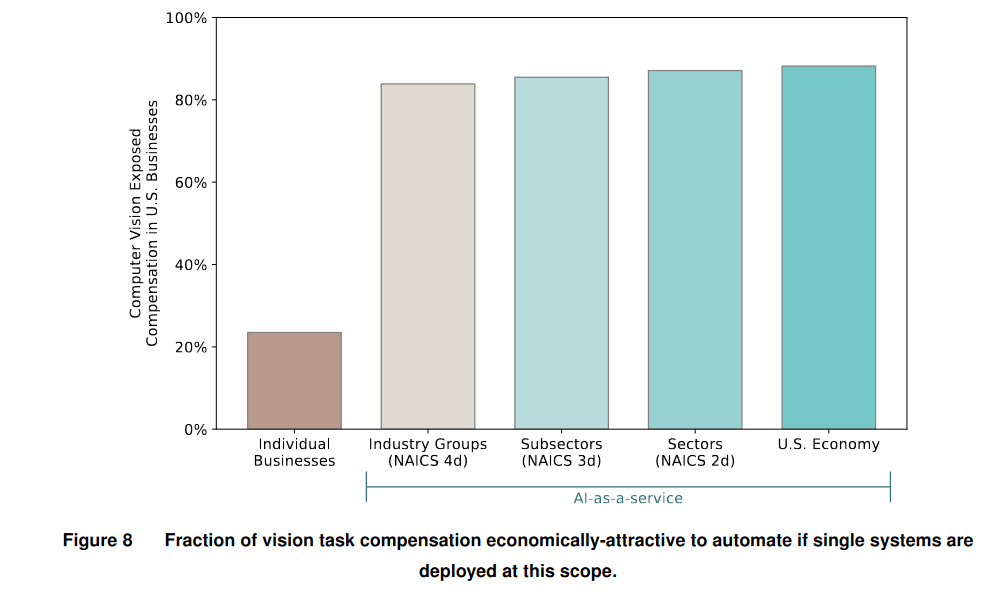
И это не предел: работоспособность системы машинного зрения не обязательно должна ограничиваться национальными рамками. Она точно так же может работать и в других странах. Обратимся к нашим примерам визуальных задач. Определение того, что за предметы стоят на поддоне — задача, которая мало меняется от отрасли к отрасли и от страны к стране. Аналогично, оценка состояния кожи и волос мало зависит от того, в какой именно фирме работает косметолог, а межстрановые различия если и появятся, то в худшем случае на уровне разных рас.
Что ж, если эти две модели дают настолько разные результаты с точки зрения выгодности замены человека, и если вокруг преобладает cхема«один разработчик ПО — много клиентов», возникает вопрос: почему в качестве основной модели авторы выбрали самостоятельное «изобретение велосипеда» каждой фирмой?
Во-первых, они скептически смотрят на то, сможет ли система быть настолько универсальной, чтобы обслуживать все фирмы хотя бы на уровне отрасли.
Примеры выше говорят о том, что сможет. Но список визуальных задач разнообразен, и формулировки в нем порой даются слишком общие. Так, авторы приводят еще один пример задачи: «интерпретация рентгеновских и УЗИ-результатов». Разумеется, логично предположить, что здесь понадобится как минимум две модели, одна для рентгена, другая — для УЗИ.
Но этот пример не очень убедителен. Пускай мы еще больше специализируем модели: какая-то будет заниматься рентгенологией скелета, какая-то — грудной клетки, какая-то — диагностикой беременности, какая-то — УЗИ внутренних органов, и так далее. Пускай у нас будет не 2 модели, а 20. Всё равно это гораздо меньше, чем количество отдельных фирм в секторе здравоохранения. Всё равно у нас получится реализовать огромный выигрыш от масштабирования системы на множество пользователей.
Следующий довод против модели «ИИ-как-сервис» авторы формулируют как «издержки координации». Привлечение множества разных фирм на одну платформу — это якобы слишком дорогой процесс. Имеются в виду расходы на отдел продаж, на рекламу и т. п.
Тезис странный. Эмпирика говорит совсем о другом: софтверные компании, продающие ПО другим корпоративным клиентам, имеют очень высокую маржинальность. Выше мы упоминали, что экономически оправданная стоимость лицензий на системы машинного зрения может достигать сотен тысяч долларов — этого с лихвой хватит, чтобы платить за продвижение и сопровождение продаж.
Еще один аргумент — сопротивление работников автоматизации своих позиций. Отрицать его нельзя, но количественно оценить этот эффект работа даже не пытается. Опять же, эмпирика говорит нам, что автоматизация углубляется вне зависимости от желаний работников.

Следующий довод — доступность данных. Действительно, данные о рабочем процессе в фирме проще всего собрать ей самой. А что, если фирма не захочет передавать эти данные сторонней организации? Вдруг это очень чувствительные данные? Вдруг они содержат какое-то ноу-хау?
Полностью исключать такую возможность нельзя. Но, на мой взгляд, чувствительность такого рода — а также уникальность процессов, требующая, чтобы модель была знакома с данными именно этой фирмы для корректной работы — касается лишь очень небольшого числа задач и фирм. Скажем, ни пример с поддоном, ни пример с косметологом, ни пример с рентгеном и УЗИ под это ограничение не подпадают.
Как правило, более чувствительные данные имеют текстовую форму или форму базы данных. Мнение о том, что в целях конфиденциальности обработка текста языковыми моделями должна вестись внутри периметра фирмы, я слышу очень часто, в том числе от людей, непосредственно внедряющих такие системы. Визуальные же данные редко содержат особые секреты производства, и потому могут переходить из рук в руки с большей легкостью. Кроме того, в отличие от проприетарных больших языковых моделей, алгоритмы машинного зрения более легковесны и их легче запустить на локальной машине.
Даже если визуальные данные имеют чувствительный характер, мы всё равно приходим к соотношению выгод и издержек от их передачи на сторону. Возможно, риски нарушения конфиденциальности не настолько серьезны, чтобы перевесить выгоды от автоматизации рабочего процесса.
На этом доводы против модели «ИИ-как-сервис» заканчиваются. Если мы решаем, что эти доводы слабы, можно посмотреть на расчеты авторов по скорости распространения такой модели:
При скорости распространения на 20% в год львиную долю бизнесов удастся охватить за 8 лет. Но 20% в год — это далеко не самый высокий возможный темп роста, если оглядываться на историю. В 1993-99 гг. «Майкрософт» увеличивала выручку в среднем на 33% в год. Другой, более свежий пример революционной бизнес-модели: «Amazon AWS» увеличивал выручку в среднем на 47% в год в 2014-22. Так что вполне возможен сценарий еще более быстрого «платформенного» замещения работников машиной.
Следующее направление анализа в рассматриваемом исследовании — гипотетический эффект технического прогресса на удешевление ИИ-систем. Во всех расчетах, которые мы обсуждали выше, уже «сидит» удешевление вычислений (закон Мура) с темпом 22% в год. Однако, во-первых, я довольно скептично смотрю на дальнейшие перспективы закона Мура. Мы можем консервативно приравнять скорость удешевления к нулю. Во-вторых, вычисления составляют лишь малую часть долларовых затрат на создание систем машинного зрения. Главные издержки — это стоимость данных и труд инженеров по машинному обучению.
Здесь уместно вспомнить про ИИ-экспоненту, касающуюся прогресса в эффективности алгоритмов. Благо единственные откалиброванные закономерности, которые удалось надёжно выявить в этой области, касаются как раз области машинного зрения. Эффективность здесь растёт примерно в 2,5 раза в год. Именно поэтому более новая модель EfficientNet v2 кладёт на обе лопатки VGG-19, созданную в 2014.

Рост эффективности касается не только вычислительных потребностей. Но и позволяет обходиться меньшим количеством данных для обучения до заданной точности. А это уже одна из крупных статей затрат при создании модели. Хотя прогресс здесь идёт существенно медленнее, чем для вычислительных нужд. Мы можем примерно оценить его как 1/5 от общей эффективности, т. е. потребность в данных падает где-то на 12% в год.
Исследователи называют еще несколько путей для уменьшения затрат на создание ИИ-систем. При этом предупреждая, что спрогнозировать темп их удешевления затруднительно. Например, средняя стоимость данных для обучения может упасть вследствие цифровизации рабочих мест. В нашем случае достаточно, чтобы операции фиксировались на камеру, в идеале — с правильного ракурса. Больше камер — доступнее обучающие данные.
Следующий момент касается собственно процесса разработки машинных моделей. Речь о новых программных инструментах разработки, ускоряющих процесс. Другое направление — распространение инженерной экспертизы в области машинного обучения. Сейчас такие специалисты стоят дорого. Но если подобные навыки будут более массовыми, разработка будет обходиться дешевле.
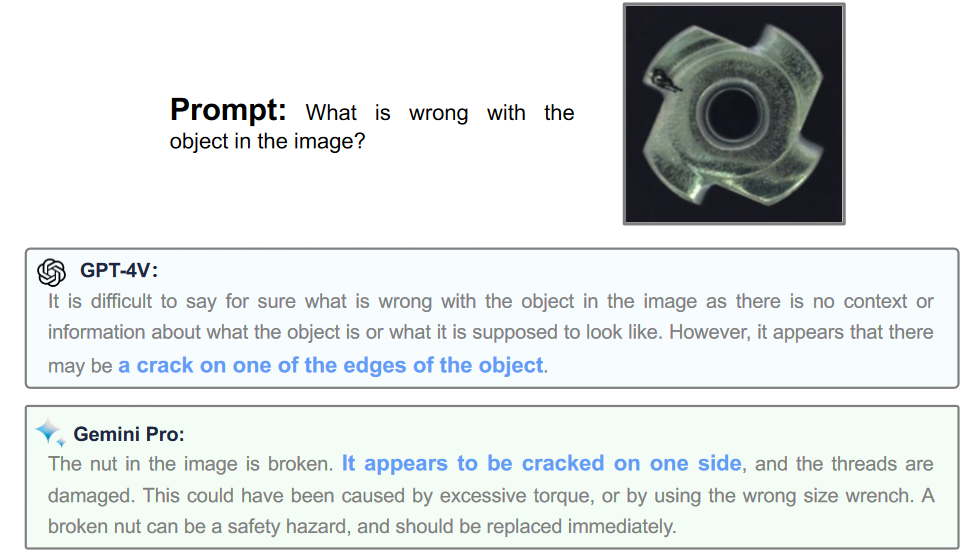
Наконец, авторы упоминают фундаментальные модели. Сказать, что это перспективное направление — не сказать ничего. По сути, фундаментальная модель должна работать «из коробки» — достаточно дать ей инструкции в свободной форме. Или, в более продвинутых случаях, дать доступ к некоторой базе данных с образцами изображений.
Мультимодальные — то есть умеющие понимать как текст, так и фото, видео и пр. — фундаментальные модели сейчас являются самой горячей темой для передовых компаний в сфере ИИ. Разработчики справедливо полагают, что такое сочетание умений является ключом к выполнению экономически ценной работы.
Сегодняшние мультимодальные модели уже достаточно универсальны, чтобы справляться с широким набором задач — но им не хватает «глубины», точности и стабильности работы. Тем не менее, очень высокий темп прогресса в этой области не оставляет сомнений, что уже в ближайшие годы они выйдут на уровень, достаточный для внедрения в производственные процессы.
Это означало бы существенное перераспределение структуры затрат на такие системы. Затраты на разработку и поддержание человеческими специалистами сократились бы почти до нуля. Зато существенно выросли бы вычислительные затраты: сильные мультимодальные модели требуют очень много вычислений. Вспомним, однако, что в базовом сценарии авторов на вычисления нужны совсем крохи. Даже если мы масштабируем эти затраты в десятки и в сотни раз, мы всё равно имеем преимущество перед стоимостью человеческой рабочей силы.
Наконец, замещение дорогого человеческого труда возможно не только в зрительных задачах, но и в области разработки таких алгоритмов. Мы обсуждали это в ИИ-экспоненте, касающейся автоматизации исследований и разработок. Машины могут разрабатывать машины. Причем машинное обучение — самый первый кандидат на такую автоматизацию, примеры «подтверждения концепта» здесь уже имеются. Это перспективы завтрашнего, а не сегодняшнего дня, но их тоже разумно принимать во внимание.
Авторы исследования выдвигают два контр-аргумента против фундаментальных моделей. Первый: для них будет недостаточно данных. Они приводят такой реальный кейс. Машинное зрение планировалось использовать для идентификации фотографий сломанных деталей, присылаемых клиентами, чтобы модель выдавала номер детали на ее замену.
Действительно, могут существовать узкие задачи, в которых недостаток данных может стать камнем преткновения. Но, скорее всего, таких задач в рамках всей экономики будет немного — по сравнению с задачами, где данных будет в избытке. Второй момент — фундаментальные модели становятся всё более умными. И одно из качеств, где проявляется рост умений — способность выполнять задачу, обходясь всё меньшим и меньшим количеством примеров. Поэтому, чем дальше — тем меньше данных будет им требоваться.
Второй контр-аргумент авторов — якобы прогресс в фундаментальных моделях замедляется. Это, мягко говоря, непопулярная точка зрения внутри самой индустрии машинного обучения. Напротив, мало кто сомневается, что прогресс здесь продолжится с таким же быстрым темпом. Мы подробно обсуждали предпосылки этого прогресса в цикле об экспонентах ИИ. Коммерциализация этой технологии создает массивный денежный поток, поддерживающий дальнейшие разработки. Упомянутая выше автоматизация исследований обещает и вовсе ускорить эти процессы до невиданных раньше масштабов.
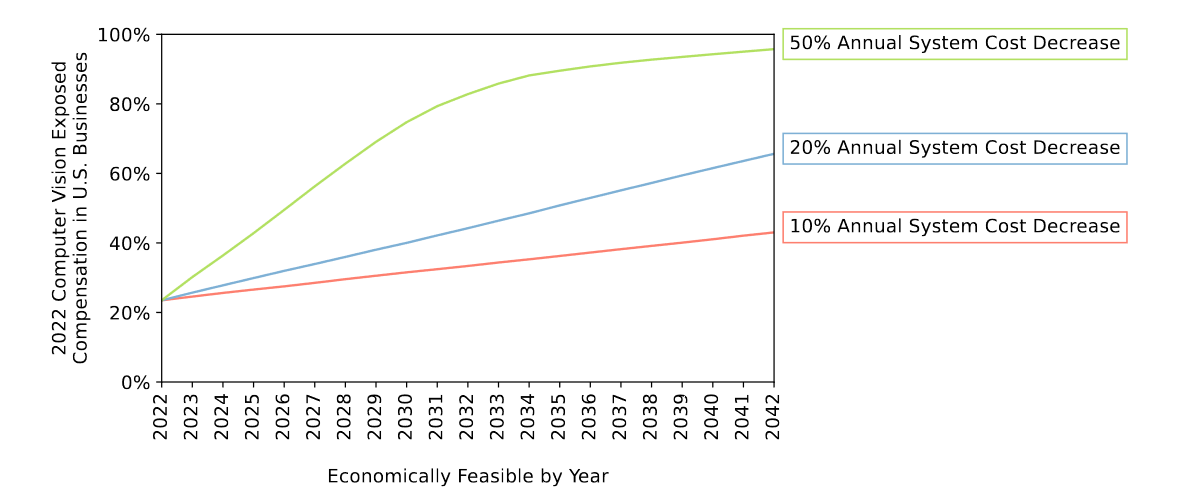
На следующем графике исследователи моделируют долю зрительных задач, которую становится выгодно автоматизировать при разных темпах удешевления стоимости модели. Базовый сценарий здесь тот же самый: «изобретение велосипеда» силами каждой фирмы в отдельности:
Следующий график посвящен масштабу подрывных изменений на рынке труда вследствие массового замещения человеческого зрения машинным. В начале анализа мы уже упоминали, что такой сценарий совсем нереалистичен. Соответственно, это не более чем теоретическое упражнение:
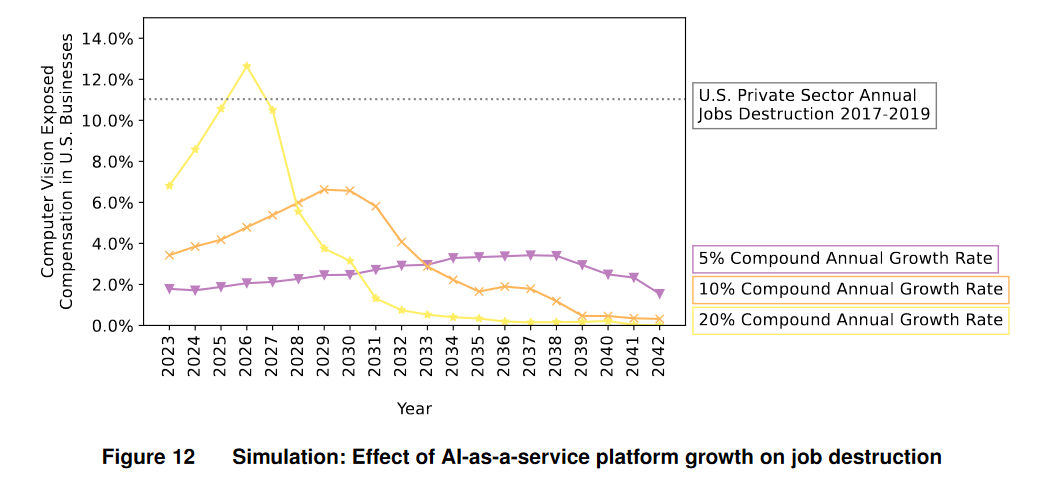
Опять-таки, выше мы сказали, что 20%-й темп распространения — это не предел, а скорее «средний» сценарий. В таком сценарии темп замещения трудовых задач (здесь пересчитанных в зарплаты) лишь в одном году превысит темп «естественного» исчезновения позиций, который в США в 2017-19 составлял 11% в год.
Поэтому выводы получаются успокаивающими: всё идёт своим чередом, рынок труда это практически не заметит. Но подобное сравнение не совсем корректно. Во-первых, «естественный» круговорот рабочих мест связан в большей степени с бизнес-обстановкой внутри отдельных фирм, нежели с технологическим устареванием трудовых задач. Другими словами, электрик, уволенный из одной фирмы, скорее всего станет работать электриком в другой фирме — в которую, возможно, будет аутсорсить свои задачи первая фирма. Вероятность того, что электрик сменит профессию на сварщика или дояра, гораздо меньше.
Даже если наш электрик решит сменить карьеру, он может предложить экономики свои руки, ноги, мозги и глаза — максимально универсальные инструменты, которым экономика может найти самое разнообразное применение.
В случае экспансии машинного зрения этот тезис уже теряет актуальность. Из списка инструментов исчезают глаза: у экономики появляется более выгодная искусственная замена для них. Экономике не нужен дорогой ресурс, когда у нее есть более дешевый аналогичный ресурс. Вы же не будете покупать бензин по 100 рублей, когда рядом продаётся такой же, но по 50 рублей? Здесь та же самая история.
Продолжим эту мысль. На замену рукам и ногам появляются роботы. На замену мозгам — общий ИИ. И вот у нашего электрика не остаётся конкурентоспособных инструментов, которые были бы востребованы экономикой. Пускай экономика США «естественным образом» сокращала 11% рабочих мест в год. Важно, что одновременно, таким же «естественным образом», она создавала еще 12,6% рабочих мест, обеспечивая нетто-прирост. Но в сценарии экспансии ИИ все (или хотя бы многие) потребности экономики будут «естественно» закрываться более дешевыми, нечеловеческими решениями. И нетто-прирост может смениться на нетто-сокращение.
Наконец, стоит упомянуть еще один фактор, который авторы исследования оставляют за скобками. Дело в том, что их подход наивно антропоцентричен (или, точнее, работнико-центричен). Они предполагают, что бизнес-процессы «отлиты в граните»: есть позиция, на ней работает человек, и машина обязана делать всё то же самое, что делает человек. Идеально эмулировать его способности.

Но бизнес-процессы не «отлиты в граните». Они строятся по принципу минимизации издержек и, естественно, следования технологическим возможностям. Ключевой здесь пока является технология под названием «человек разумный», с его глазами, руками, ногами и мозгами, с заданной «скоростью», «грузоподъемностью», выносливостью, временем реакции, «объемом оперативной памяти» и т. д.
Как только у нас появляется альтернативная технология с сопоставимыми (а то и более низкими) издержками, появляется смысл реинжиниринга бизнес-процессов. Это означает, что не только модели будут подгоняться под задачи (что и обсчитывали авторы в своём исследовании). Но и задачи будут подгоняться под возможности моделей и под наиболее низкие издержки использования таких моделей.
Так что это дорога с двухсторонним движением. И расчеты авторов скорее стоит интерпретировать как верхнюю границу возможной себестоимости машинных моделей, не учитывающую потенциал оптимизации.
Поэтому, друзья, чрезмерный оптимизм, наивность и выдача желаемого за действительное в отношении будущего рабочих мест вряд ли оправданы. Какое-то время технология под названием «человек разумный» всё еще будет оставаться ключевой. Но для нее уже начали появляться альтернативы. И конкурентные позиции у этой альтернативы — ИИ — с точки зрения экономики выглядят очень и очень неплохо.
Эта работа была широко освещена в СМИ: Bloomberg, Euronews, Business Insider, Time и далее по списку. Во всех без исключения заголовках читается коллективное облегчение: ура, люди не останутся без работы, потому что это ваш ИИ тупо экономически неконкурентоспособен.
Вывод, мягко говоря, неожиданный. Как с точки зрения взглядов, бытующих среди экспертов и футурологов, так и с точки зрения истории автоматизации труда. Поэтому давайте в подробностях рассмотрим, как именно исследователи к нему пришли.
Один из центральных моментов исследования заключается в том, что он ограничивается только задачей машинного зрения. Главным образом потому, что это одна из самых зрелых областей в машинного обучения. Где более-менее ясны вводные: что представляет собой машинная модель, сколько она стоит и что она может. Причем круг ее возможностей достаточно узок, что здорово облегчает сопоставление с нынешней «человеческой» экономикой.
Другими словами, у нас опять получается ситуация «ищут не там, где потеряли, а там, где светло». Помните, в предыдущей рассмотренной работе авторы пытались натянуть всё разнообразие человеческой работы на несколько узких направлений машинного обучения, существовавших в 2019 году (в числе которых было и машинное зрение)? Здесь примерно тот же принцип.
Разве что в нынешнем случае исследователи хотя бы остаются в границах адекватности и сопоставляют узкий функционал машинного зрения со зрительными задачами на разных рабочих местах. Например, такая задача, как проверка поддонов, чтобы на них лежали нужные предметы, или оценка состояния кожи и волос в контексте работы косметолога или дерматолога.
Но на большинстве рабочих мест работать надо не только глазами. Так, косметологу надо не только оценивать состояние кожи, но и уметь обрабатывать ее самыми разными способами. Как здесь сопоставить машину и человека?
Авторы предлагают не заморачиваться с такими каверзными моментами и просто-напросто абстрагироваться от неудобных сложностей. Они берут долю рабочего времени, которая относится на выполнение зрительных задач, берут зарплату человека пропорционально этой долe, и всё остальное их не касается. В теории особых претензий к такому анализу нет. Но на практике такой сценарий, конечно, зачастую невозможен. Вряд ли кто-то будет приставлять к каждому косметологу манипулятор с камерой, который будет задействован 7% времени и будет делать то же самое, что уже умеет косметолог. И требовать от последнего на 7% ужаться в зарплате.
Так что такой анализ имеет лишь теоретическую ценность. Практические выводы из такой постановки задачи не вынести — за исключением тех немногих профессий, где использование зрительныx навыков составляет львиную долю рабочего времени.
Ладно, ограничимся теорией. В теории у авторов получается 420 зрительных задач, из которых 416 фактически представлены в американской экономике. Ключевая предпосылка данной работы — это расчеты экономической целесообразности замены человека машиной в таких задачах. Практически во всех предыдущих исследованиях на эту тему данный аспект игнорировался; подразумевалось, что если ИИ технологически способен выполнять ту или иную задачу — этого достаточно.
Что ж, предпосылка действительно нужная. Остаётся только подсчитать, сколько будет стоить работа машины. Исследователи делят издержки на 3 группы, которые мы можем примерно обозначить как операционные, капитальные с влиянием на производительность и безусловные капитальные.
В качестве базовой модели машинного зрения авторы откапывают берут VGG-19 – старинную, тяжеловесную нейросеточку, созданную еще во времена, когда по планете бродили динозавры, а Дженсен Хуанг и помыслить не мог, что будущее “Nvidia” может быть связано с чем-то помимо компьютерной графики. Честно говоря, такому антиквариату место в музее, а не в серьезном экономическом исследовании. Более современные разработки ускакали настолько далеко вперёд, что даже прямое сравнение становится затруднительным.
Возьмем EfficientNet v2, вышедшую в июле 2021. Даже самая маленькая её версия на две головы превосходит VGG-19 в точности классификации изображений. При этом превосходя её по скорости на 11%.
Выше и левее - лучшие характеристики точности и скорости
Ок, разница в скорости небольшая, так что можно заменить модель на более современную и держать в уме выигрыш в качестве. Что будет получаться по издержкам? Начнем с операционных. Это стоимость обсчета данных нейросетью. И тут сразу возникает вопрос: сколько именно данных надо считать? В примерах зрительных задач, которые я привёл выше, число кадров не должно быть велико. Для задачи с поддоном это один кадр — максимум еще пара, с разных ракурсов. Для задачи косметолога — это 10-30 кадров максимум.
Машина обсчитывает кадр быстро — для EfficientNet v2-S нужно 24 миллисекунды (порядка 42 кадров/сек) на видеокарте Nvidia V100. То есть задача будет выполнена за долю секунды. Секунда работы V100, в свою очередь, стоит 0,03 американских цента. Цента, не доллара. Чуть меньше трёх русских копеек.
Ну как человеческий работник может конкурировать с такими расценками? Очень просто, говорят нам авторы исследования. Нас не волнует, что машина считает всё за доли секунды. Мы будем считать, что машина будет работать столько же времени, сколько человек пялится на эти поддоны и на эту клиентскую кожу с волосами. И плевать, что содержимое кадров там будет практически одно и то же.
Но ладно. Невзирая на такое несправедливое отягощение, стоимость облачных GPU настолько низка, что на итоговый результат операционные издержки влияют слабо.
Идём дальше. Следующая группа затрат — капитальные с влиянием на производительность. Под этой категорией авторы подразумевают часть издержек на создание модели, варьирующуюся в зависимости от специфики задачи. Вариабельность объясняется, главным образом, стоимостью сбора данных, необходимых для обучения модели, а также затратами на собственно ее обучение (стоимость вычислений).
Здесь авторы скрупулезно подходят к расчетам необходимой точности и способностей модели в каждой визуальной задаче, а также стоимость добычи данных, опрашивая (через онлайн-платформу) представителей соответствующих профессий. Для большинства задач стоимость одного обучающего примера составляет от 0 до 4 долларов, с медианой в районе $3. Например, стоимость одного фотоснимка, сделанного работником, авторы оценили в $1,22. На мой взгляд, здесь есть некоторое завышение, но вряд ли больше, чем в 2 раза.
Помимо затрат на создание, в эту же категорию попадают затраты на регулярное переобучение/доводку модели. В совокупности за время использования модели эти затраты сравняются с затратами на первоначальное обучение, т. е. удвоят начальный вычислительный бюджет.
Наконец, безусловные капитальные затраты. Они примерно соответствуют человеческому труду, необходимому, чтобы превратить набор данных в готовую к применению машинную модель. Здесь они опираются на более раннее исследование, в котором приводится кейс создания ИИ-продукта за 6 месяцев командой из 11 специалистов, включавшей инженеров IBM. Затраты на проект составили 1,8 млн. долларов. Еще 240 тыс. долларов в год надо будет тратить на «сопровождение» проекта специалистами.
Сумма немалая — и в итоге эта категория затрат будет доминировать среди общей стоимости использования модели. Единственная ремарка, которая у меня есть, касается возможного аутсорсинга этой разработки. Если облачные GPU стоят примерно одинаково во всём мире, а собрать обучающие данные в американской фирме могут только американские работники, то разработка модели может вестись и в более экономных юрисдикциях, нежели родина IBM. Команда из Ижевска или Бангалора может справиться с этой задачей за гораздо меньшие деньги, чем инженеры IBM. Авторы совершенно не учитывают этой возможности для ускорения ИИ-автоматизации.
В общей совокупности, медианная приведенная стоимость машинной системы в визуальных задачах составила 2,3 млн. долларов. Сумма вполне здравая. И даже немного ниже моих интуитивных представлений; для ровного счета мы можем принять, что она отражает потенциал оффшоризации разработки.
Расчетный срок эксплуатации системы — 5 лет, в течение которых мы должны самортизировать все капитальные затраты на ее создание. Тоже более чем разумная оценка.
Недоумение возникает чуть позже — когда мы знакомимся с моделью внедрения таких систем в национальную экономику. Недоумение — это еще мягко сказано. Потому что основная модель авторов подразумевает, что каждая отдельная фирма в экономике — вплоть до микро-бизнеса из двух сотрудников — должна разрабатывать такую систему самостоятельно, независимо и для каждой визуальной задачи.
Почему? Откуда взялась такая предпосылка? Где ее видно в реальном мире? Модель машинного зрения — то же программное обеспечение. Много ли фирм пилят своё, уникальное ПО — для бухгалтерского учета, для CRM, для баз данных, для редактирования текстовых и табличных документов? Пилят уникальные операционные системы для своих компьютеров, в конце концов?
Впрочем, почему мы должны останавливаться только на программном обеспечении? По логике авторов, фирмы всё должны разрабатывать сами, ведь у них якобы такие уникальные нужды… Так что и компьютеры пускай тоже разрабатывают сами. И станки. И офисную мебель.
Внесем немножко логики в эту сюрреалистичную картину. Информационные продукты — а модель машинного зрения им является — хороши тем, что львиная доля издержек здесь приходится на процесс их разработки. Как только информационный продукт разработан — использование каждой последующей его копии для разработчика практически ничего не стоит. Если более строго, маржинальные издержки на каждого нового его покупателя почти равны нулю. Это означает огромный выигрыш от масштабирования использования таких продуктов. Выигрыш как для разработчика, так и для его пользователей.
Мы можем видеть этот выигрыш в успехе модели разработки ПО «на сторону», для массового клиента. И каком успехе! Крупнейшие корпорации с капитализацией в миллиарды и триллионы долларов — «Майкрософт», «Гугл», «Мета», «Оракл» — выросли на предоставлении своих программных продуктов максимально широкому кругу потребителей. Потому что намного проще и дешевле купить несколько лицензий ”Windows” по 200 долларов за штуку, чем разрабатывать ОС с нуля своими силами.
Но авторы исследования игнорируют эти очевидные вещи, а также преобладающую вокруг модель отношений вокруг ПО. Дальше остаётся чистая статистика. 87% американских фирм имеют не больше 20 сотрудников. Если ранжировать фирмы по численности персонала, медианный сотрудников будет работать в фирме, где от 500 до 749 человек. Только 36% рабочих мест имеют хотя бы одну задачу, где требуются зрительные навыки. Доля оплаты труда, которую можно отнести на эти навыки, еще меньше — 1,6% от всех зарплат в экономике. Последняя цифра, кстати, говорит нам, что было бы неуместно распространять выводы этого исследования на всю национальную экономику.
В общем, если мы заставим каждую фирму «изобретать велосипед» по новой, для большинства овчинка не будет стоить выделки. Авторы рассчитывают, что автоматизация по такой модели будет выгодна только для 23% затрагиваемых рабочих мест, т. е. для 8% в масштабах всей экономики. Именно эти цифры и подхватили все СМИ, трубя о бесперспективности замещения человека ИИ и расширяя эти выводы, мало адекватные даже для одного направления, на всю экономическую деятельность.
К чести авторов, они рассматривают разные предпосылки и модели применения машинного зрения. Так, одним из сценариев является «минималистичный», предполагающий нулевую стоимость сбора данных и вычислений. Стоимость разработки в нем падает до 165 тыс. долларов, стоимость «сопровождения» — до 123 тыс. долларов в год.
Удешевление даёт свои плоды: снижение расходов примерно на порядок позволяет нам с выгодой заменить машиной уже не 23%, а 49% зрительных задач.
Конечно, бесплатность вычислений и сбора данных — это нереалистичные предпосылки. Бесплатного ничего не бывает. Сценарий интересен другим: он позволяет нам оценить, сколько могли бы платить фирмы за лицензию на соответствующее ПО. Мы видим, что первая четверть рабочих мест выгодна при стоимости лицензии 2,3 млн. долларов на 5 лет. Вторая четверть — при стоимости порядка 150 тыс. долларов в год (165/5 + 123).
То есть пока связь такая: удешевление системы в ~3 раза даёт нам возможность автоматизировать еще 25% рабочих мест. Добавим, что 150 тыс. долларов — это внушительная сумма по меркам рынка ПО. Хотя, как правило, лицензирование там идёт по количеству рабочих мест, а не по одной «оптовой» лицензии на фирму.
Наконец, мы переходим к самым интересным — самым реалистичным — альтернативным сценариям. Первый из них касается как раз классической модели масштабирования ПО: когда одна система используется широким кругом фирм. И с такой моделью результаты меняются кардинально. Даже если для каждой визуальной задачи каждая отрасль экономики (классификация США выделяет 324 отрасли) будет создавать свою систему, доля задач, где человека выгодно заместить машиной, подскакивает где-то до 85%. Агрегирование в масштабах всей экономики (одна модель на каждую задачу) даёт небольшой прирост: до 88%.
И это не предел: работоспособность системы машинного зрения не обязательно должна ограничиваться национальными рамками. Она точно так же может работать и в других странах. Обратимся к нашим примерам визуальных задач. Определение того, что за предметы стоят на поддоне — задача, которая мало меняется от отрасли к отрасли и от страны к стране. Аналогично, оценка состояния кожи и волос мало зависит от того, в какой именно фирме работает косметолог, а межстрановые различия если и появятся, то в худшем случае на уровне разных рас.
Что ж, если эти две модели дают настолько разные результаты с точки зрения выгодности замены человека, и если вокруг преобладает cхема«один разработчик ПО — много клиентов», возникает вопрос: почему в качестве основной модели авторы выбрали самостоятельное «изобретение велосипеда» каждой фирмой?
Во-первых, они скептически смотрят на то, сможет ли система быть настолько универсальной, чтобы обслуживать все фирмы хотя бы на уровне отрасли.
Примеры выше говорят о том, что сможет. Но список визуальных задач разнообразен, и формулировки в нем порой даются слишком общие. Так, авторы приводят еще один пример задачи: «интерпретация рентгеновских и УЗИ-результатов». Разумеется, логично предположить, что здесь понадобится как минимум две модели, одна для рентгена, другая — для УЗИ.
Но этот пример не очень убедителен. Пускай мы еще больше специализируем модели: какая-то будет заниматься рентгенологией скелета, какая-то — грудной клетки, какая-то — диагностикой беременности, какая-то — УЗИ внутренних органов, и так далее. Пускай у нас будет не 2 модели, а 20. Всё равно это гораздо меньше, чем количество отдельных фирм в секторе здравоохранения. Всё равно у нас получится реализовать огромный выигрыш от масштабирования системы на множество пользователей.
Следующий довод против модели «ИИ-как-сервис» авторы формулируют как «издержки координации». Привлечение множества разных фирм на одну платформу — это якобы слишком дорогой процесс. Имеются в виду расходы на отдел продаж, на рекламу и т. п.
Тезис странный. Эмпирика говорит совсем о другом: софтверные компании, продающие ПО другим корпоративным клиентам, имеют очень высокую маржинальность. Выше мы упоминали, что экономически оправданная стоимость лицензий на системы машинного зрения может достигать сотен тысяч долларов — этого с лихвой хватит, чтобы платить за продвижение и сопровождение продаж.
Еще один аргумент — сопротивление работников автоматизации своих позиций. Отрицать его нельзя, но количественно оценить этот эффект работа даже не пытается. Опять же, эмпирика говорит нам, что автоматизация углубляется вне зависимости от желаний работников.
Следующий довод — доступность данных. Действительно, данные о рабочем процессе в фирме проще всего собрать ей самой. А что, если фирма не захочет передавать эти данные сторонней организации? Вдруг это очень чувствительные данные? Вдруг они содержат какое-то ноу-хау?
Полностью исключать такую возможность нельзя. Но, на мой взгляд, чувствительность такого рода — а также уникальность процессов, требующая, чтобы модель была знакома с данными именно этой фирмы для корректной работы — касается лишь очень небольшого числа задач и фирм. Скажем, ни пример с поддоном, ни пример с косметологом, ни пример с рентгеном и УЗИ под это ограничение не подпадают.
Как правило, более чувствительные данные имеют текстовую форму или форму базы данных. Мнение о том, что в целях конфиденциальности обработка текста языковыми моделями должна вестись внутри периметра фирмы, я слышу очень часто, в том числе от людей, непосредственно внедряющих такие системы. Визуальные же данные редко содержат особые секреты производства, и потому могут переходить из рук в руки с большей легкостью. Кроме того, в отличие от проприетарных больших языковых моделей, алгоритмы машинного зрения более легковесны и их легче запустить на локальной машине.
Даже если визуальные данные имеют чувствительный характер, мы всё равно приходим к соотношению выгод и издержек от их передачи на сторону. Возможно, риски нарушения конфиденциальности не настолько серьезны, чтобы перевесить выгоды от автоматизации рабочего процесса.
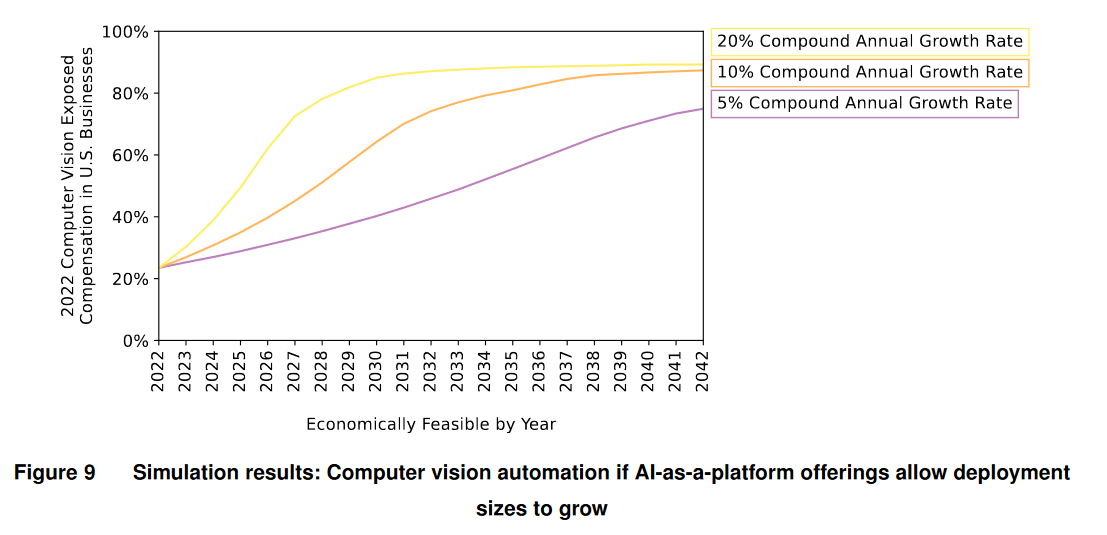
На этом доводы против модели «ИИ-как-сервис» заканчиваются. Если мы решаем, что эти доводы слабы, можно посмотреть на расчеты авторов по скорости распространения такой модели:
При скорости распространения на 20% в год львиную долю бизнесов удастся охватить за 8 лет. Но 20% в год — это далеко не самый высокий возможный темп роста, если оглядываться на историю. В 1993-99 гг. «Майкрософт» увеличивала выручку в среднем на 33% в год. Другой, более свежий пример революционной бизнес-модели: «Amazon AWS» увеличивал выручку в среднем на 47% в год в 2014-22. Так что вполне возможен сценарий еще более быстрого «платформенного» замещения работников машиной.
Следующее направление анализа в рассматриваемом исследовании — гипотетический эффект технического прогресса на удешевление ИИ-систем. Во всех расчетах, которые мы обсуждали выше, уже «сидит» удешевление вычислений (закон Мура) с темпом 22% в год. Однако, во-первых, я довольно скептично смотрю на дальнейшие перспективы закона Мура. Мы можем консервативно приравнять скорость удешевления к нулю. Во-вторых, вычисления составляют лишь малую часть долларовых затрат на создание систем машинного зрения. Главные издержки — это стоимость данных и труд инженеров по машинному обучению.
Здесь уместно вспомнить про ИИ-экспоненту, касающуюся прогресса в эффективности алгоритмов. Благо единственные откалиброванные закономерности, которые удалось надёжно выявить в этой области, касаются как раз области машинного зрения. Эффективность здесь растёт примерно в 2,5 раза в год. Именно поэтому более новая модель EfficientNet v2 кладёт на обе лопатки VGG-19, созданную в 2014.
Рост эффективности касается не только вычислительных потребностей. Но и позволяет обходиться меньшим количеством данных для обучения до заданной точности. А это уже одна из крупных статей затрат при создании модели. Хотя прогресс здесь идёт существенно медленнее, чем для вычислительных нужд. Мы можем примерно оценить его как 1/5 от общей эффективности, т. е. потребность в данных падает где-то на 12% в год.
Исследователи называют еще несколько путей для уменьшения затрат на создание ИИ-систем. При этом предупреждая, что спрогнозировать темп их удешевления затруднительно. Например, средняя стоимость данных для обучения может упасть вследствие цифровизации рабочих мест. В нашем случае достаточно, чтобы операции фиксировались на камеру, в идеале — с правильного ракурса. Больше камер — доступнее обучающие данные.
Следующий момент касается собственно процесса разработки машинных моделей. Речь о новых программных инструментах разработки, ускоряющих процесс. Другое направление — распространение инженерной экспертизы в области машинного обучения. Сейчас такие специалисты стоят дорого. Но если подобные навыки будут более массовыми, разработка будет обходиться дешевле.
Наконец, авторы упоминают фундаментальные модели. Сказать, что это перспективное направление — не сказать ничего. По сути, фундаментальная модель должна работать «из коробки» — достаточно дать ей инструкции в свободной форме. Или, в более продвинутых случаях, дать доступ к некоторой базе данных с образцами изображений.
Мультимодальные — то есть умеющие понимать как текст, так и фото, видео и пр. — фундаментальные модели сейчас являются самой горячей темой для передовых компаний в сфере ИИ. Разработчики справедливо полагают, что такое сочетание умений является ключом к выполнению экономически ценной работы.
Сегодняшние мультимодальные модели уже достаточно универсальны, чтобы справляться с широким набором задач — но им не хватает «глубины», точности и стабильности работы. Тем не менее, очень высокий темп прогресса в этой области не оставляет сомнений, что уже в ближайшие годы они выйдут на уровень, достаточный для внедрения в производственные процессы.
Это означало бы существенное перераспределение структуры затрат на такие системы. Затраты на разработку и поддержание человеческими специалистами сократились бы почти до нуля. Зато существенно выросли бы вычислительные затраты: сильные мультимодальные модели требуют очень много вычислений. Вспомним, однако, что в базовом сценарии авторов на вычисления нужны совсем крохи. Даже если мы масштабируем эти затраты в десятки и в сотни раз, мы всё равно имеем преимущество перед стоимостью человеческой рабочей силы.
Наконец, замещение дорогого человеческого труда возможно не только в зрительных задачах, но и в области разработки таких алгоритмов. Мы обсуждали это в ИИ-экспоненте, касающейся автоматизации исследований и разработок. Машины могут разрабатывать машины. Причем машинное обучение — самый первый кандидат на такую автоматизацию, примеры «подтверждения концепта» здесь уже имеются. Это перспективы завтрашнего, а не сегодняшнего дня, но их тоже разумно принимать во внимание.
Авторы исследования выдвигают два контр-аргумента против фундаментальных моделей. Первый: для них будет недостаточно данных. Они приводят такой реальный кейс. Машинное зрение планировалось использовать для идентификации фотографий сломанных деталей, присылаемых клиентами, чтобы модель выдавала номер детали на ее замену.
Действительно, могут существовать узкие задачи, в которых недостаток данных может стать камнем преткновения. Но, скорее всего, таких задач в рамках всей экономики будет немного — по сравнению с задачами, где данных будет в избытке. Второй момент — фундаментальные модели становятся всё более умными. И одно из качеств, где проявляется рост умений — способность выполнять задачу, обходясь всё меньшим и меньшим количеством примеров. Поэтому, чем дальше — тем меньше данных будет им требоваться.
Второй контр-аргумент авторов — якобы прогресс в фундаментальных моделях замедляется. Это, мягко говоря, непопулярная точка зрения внутри самой индустрии машинного обучения. Напротив, мало кто сомневается, что прогресс здесь продолжится с таким же быстрым темпом. Мы подробно обсуждали предпосылки этого прогресса в цикле об экспонентах ИИ. Коммерциализация этой технологии создает массивный денежный поток, поддерживающий дальнейшие разработки. Упомянутая выше автоматизация исследований обещает и вовсе ускорить эти процессы до невиданных раньше масштабов.
На следующем графике исследователи моделируют долю зрительных задач, которую становится выгодно автоматизировать при разных темпах удешевления стоимости модели. Базовый сценарий здесь тот же самый: «изобретение велосипеда» силами каждой фирмы в отдельности:
Следующий график посвящен масштабу подрывных изменений на рынке труда вследствие массового замещения человеческого зрения машинным. В начале анализа мы уже упоминали, что такой сценарий совсем нереалистичен. Соответственно, это не более чем теоретическое упражнение:
Опять-таки, выше мы сказали, что 20%-й темп распространения — это не предел, а скорее «средний» сценарий. В таком сценарии темп замещения трудовых задач (здесь пересчитанных в зарплаты) лишь в одном году превысит темп «естественного» исчезновения позиций, который в США в 2017-19 составлял 11% в год.
Поэтому выводы получаются успокаивающими: всё идёт своим чередом, рынок труда это практически не заметит. Но подобное сравнение не совсем корректно. Во-первых, «естественный» круговорот рабочих мест связан в большей степени с бизнес-обстановкой внутри отдельных фирм, нежели с технологическим устареванием трудовых задач. Другими словами, электрик, уволенный из одной фирмы, скорее всего станет работать электриком в другой фирме — в которую, возможно, будет аутсорсить свои задачи первая фирма. Вероятность того, что электрик сменит профессию на сварщика или дояра, гораздо меньше.
Даже если наш электрик решит сменить карьеру, он может предложить экономики свои руки, ноги, мозги и глаза — максимально универсальные инструменты, которым экономика может найти самое разнообразное применение.
В случае экспансии машинного зрения этот тезис уже теряет актуальность. Из списка инструментов исчезают глаза: у экономики появляется более выгодная искусственная замена для них. Экономике не нужен дорогой ресурс, когда у нее есть более дешевый аналогичный ресурс. Вы же не будете покупать бензин по 100 рублей, когда рядом продаётся такой же, но по 50 рублей? Здесь та же самая история.
Продолжим эту мысль. На замену рукам и ногам появляются роботы. На замену мозгам — общий ИИ. И вот у нашего электрика не остаётся конкурентоспособных инструментов, которые были бы востребованы экономикой. Пускай экономика США «естественным образом» сокращала 11% рабочих мест в год. Важно, что одновременно, таким же «естественным образом», она создавала еще 12,6% рабочих мест, обеспечивая нетто-прирост. Но в сценарии экспансии ИИ все (или хотя бы многие) потребности экономики будут «естественно» закрываться более дешевыми, нечеловеческими решениями. И нетто-прирост может смениться на нетто-сокращение.
Наконец, стоит упомянуть еще один фактор, который авторы исследования оставляют за скобками. Дело в том, что их подход наивно антропоцентричен (или, точнее, работнико-центричен). Они предполагают, что бизнес-процессы «отлиты в граните»: есть позиция, на ней работает человек, и машина обязана делать всё то же самое, что делает человек. Идеально эмулировать его способности.
Но бизнес-процессы не «отлиты в граните». Они строятся по принципу минимизации издержек и, естественно, следования технологическим возможностям. Ключевой здесь пока является технология под названием «человек разумный», с его глазами, руками, ногами и мозгами, с заданной «скоростью», «грузоподъемностью», выносливостью, временем реакции, «объемом оперативной памяти» и т. д.
Как только у нас появляется альтернативная технология с сопоставимыми (а то и более низкими) издержками, появляется смысл реинжиниринга бизнес-процессов. Это означает, что не только модели будут подгоняться под задачи (что и обсчитывали авторы в своём исследовании). Но и задачи будут подгоняться под возможности моделей и под наиболее низкие издержки использования таких моделей.
Так что это дорога с двухсторонним движением. И расчеты авторов скорее стоит интерпретировать как верхнюю границу возможной себестоимости машинных моделей, не учитывающую потенциал оптимизации.
Поэтому, друзья, чрезмерный оптимизм, наивность и выдача желаемого за действительное в отношении будущего рабочих мест вряд ли оправданы. Какое-то время технология под названием «человек разумный» всё еще будет оставаться ключевой. Но для нее уже начали появляться альтернативы. И конкурентные позиции у этой альтернативы — ИИ — с точки зрения экономики выглядят очень и очень неплохо.
Не является индивидуальной инвестиционной рекомендацией | При копировании ссылка обязательна | Нашли ошибку - выделить и нажать Ctrl+Enter | Жалоба